网页简介
有人说“互联网中有50%以上的流量是爬虫”,第一次听这句话也许你会觉得这个说法实在太夸张了,怎么可能爬虫比用户还多呢?毕竟会爬虫的相对与不会爬虫的简直少之又少。
但是很多爬虫工程师或者反爬虫工程师讲了实话:50%?你在逗我?就这么少的量?然后他举出例子:
某个公司的某个页面的某个接口,每分钟访问量是1.2万左右,这里面有都少正常用户呢?50%?60%?正确答案是:500个以下,那我们来算算爬虫占比:(12000-500)/12000=95.8%
没错95.8%,这是一位反爬虫工程师给出的爬虫占比!!!

那这么多的爬虫它们在互联网上做什么呢?答案当然是:孜孜不倦的爬取爬取网页信息。今天我们就来讲讲组成互联网的重要部分之一:HTML网页。
一、起源与发展
前面我们介绍HTTP的时候,给大家讲过是万维网的发明者,互联网之父计算机科学家蒂姆·伯纳斯·李,在他最初的构想组成中就有:提出使用HTML超文本标记语言(Hypertext Markup Language)作为创建网页的标准。

大家千万记住HTML并不是一种编程语言,而是一种标记语言 (markup language),由W3C(万维网联盟)制定标准,然后由个大浏览器厂商自己去实现支持!
下面我们来看看HTML标准的发展历史:
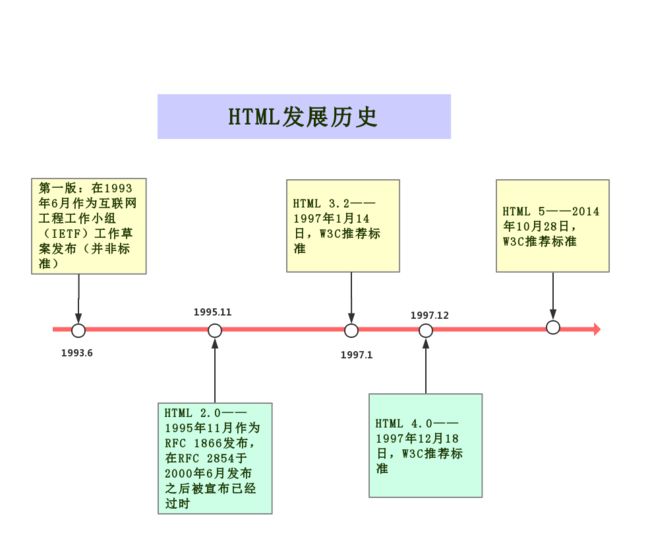
二、组成部分
我们常说的网页就是HTML页面,而构成HTML页面的东西有很多,如:html标签、数据、css样式、js等,那我们就主要讲讲以下这几个组成部分。
1.HTML标签
HTML标签是构成HTML页面的主要组成部分,我们来看一个HTML实际例子:
<html>
<head>
<meta charset="utf-8" />
<title>注册页title>
head>
<body>
<form action="/register" method="post">
<div>用户名:<input type="text" name="username"/>div>
<div>性 别:
<input name="sex" type="radio" checked="checked"/>男
<input name="sex" type="radio" />女
div>
<div>密 码:<input type="text" name="password"/>div>
<br/>
<input type="submit" value="注册" style="width:150px;" />
form>
body>
html>
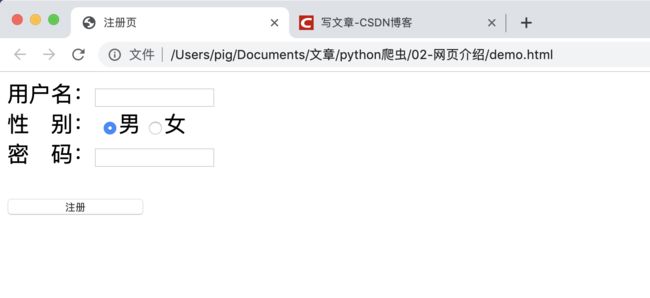
上面是一个非常简陋的用户注册页面(用于教学),用户可以输入用户名性别和密码然后点注册就提交到服务器,下面我们来稍微讲解以下这个页面。
- html标签对限定了文档的开始点和结束点,所有的元素和标签都应该放在他们之间。
- head标签对表示网页头部信息,其中包含了网页标题、网页编码、网站ico、网站引入的一些静态资源(css、js)以及网站关键字SEO相关信息等。
- body标签对表示网页体,几乎所有的网页内容都在这里展现。
- form标签对表示创建表单,表单用于向服务器传输数据,能够包含 input 元素,比如文本字段、复选框、单选框、提交按钮等等。
- div标签对是目前网页中比较流行的标签,在七八年年流行使用table来构思一个网页,把一个网页想象成多少行多少列,这种构思灵活性和维护性极差,并且Table标签构思的网页对google爬虫和百度等这种搜索引擎收录性很差,遇到多层表格嵌套时,会跳过嵌套的内容或直接放弃整个页面。所以目前前端流行使用div+css来构思网页,这样的优点是代码精简、有很好的灵活性和可维护性。
- input标签用于搜集用户信息,它可以根据不同的 type 属性值,输入字段拥有很多种形式。输入字段可以是文本字段、复选框、掩码后的文本控件、单选按钮、按钮等等。
其他的HTML标签猪哥就不多讲,希望大家自己去网上学习。
在有些初级web工程师面试中,面试过程中可能会让你手写一个用户注册功能,这里猪哥给大家讲讲大概的流程:
- 用户点击注册连接(一般是get请求/register),然后服务器响应此请求返回一个注册页面
- 用户输入用户名密码、图形验证码等信息,提交注册信息(一般是post请求/register)
- 服务端收到信息后对信息做校验(一般是前后端双校验),然后存入数据库,返回注册成功提示
2.数据
互联网主要起到了信息交流的作用,而网页作为主要的信息交换载体,标签的主要作用就是包裹数据,让数据能够以人类可视的方式展现。
尤其是一些新闻网站,他们主要以展示新闻信息为主,我们以头条网页来讲讲:
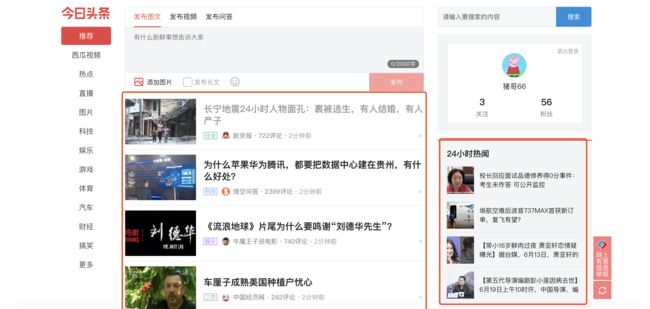
在红色框中圈出来的这些新闻,他们是把数据包裹在html标签中,然后以列表的形式展示给用户,接着我们来看看网页代码:
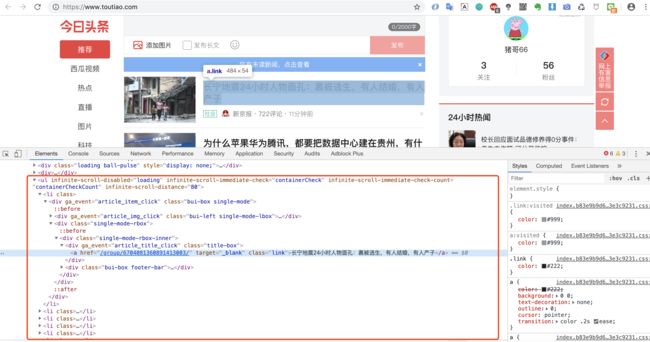
我们可以看到新闻标题被a标签包围,还有一些如缩略图、评论数、时间等信息构成了一条新闻简述,然后多个新闻(il标签)构成了一个列表(ul)。
那服务器是如何将数据与封装到页面中去的呢?
- 前后端未分离:前后端没有分离的公司,一般是先由前端工程师写好页面(数据写死),然后由后端程序员合页面(就是将写死的数据去掉,然后加上数据字段)。
- 前后端分离:前后端没分离最大的问题就是同一个页面可能前后端开发同学都会去修改,修改的人少还行,但是如果开发人员一多,大家改来改去全乱了,而且发布也会有一定的限制,所以目前流行前后端分离,后端同学只需要提供数据,前端同学搭一个nodejs后台自己渲染页面。
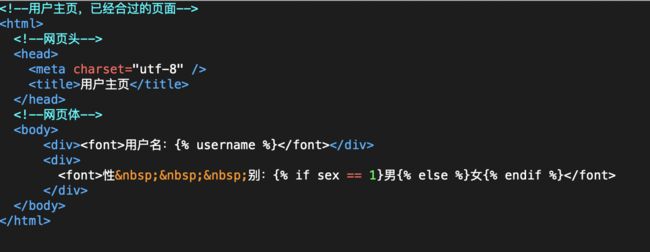
拿上面我们的简陋的注册页面来讲讲前后端未分离时具体返回页面步骤,假设我们用户注册成功然后登录,登录成功我们直接跳转用户主页展示用户名和性别,页面如上图,步骤如下:
- 用户登录成功,在数据库中读取用户信息。
- 读取到用户数据后进行页面渲染
- 返回渲染后的页面给浏览器
3.CSS样式
html标签+数据构成了整个网页的骨架,但是只有数据和html标签的网页是奇丑无比的
层叠样式表(英文全称:Cascading Style Sheets 简称CSS)是一种用来表现HTML等文件样式的计算机语言。css可以定义html现实的样式,可以实现很多不同的效果、排版等等,html中所有的元素几乎都需要css来管理样式,而且现在越来越流行div+css搭配控制页面排版和样式,css主要通过三大选择器来修饰html标签。
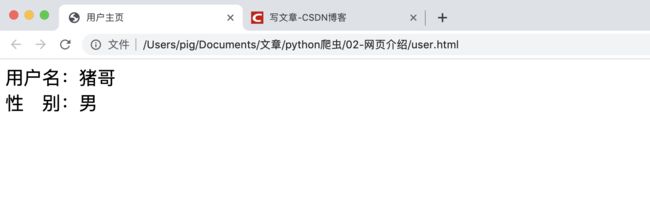
没有css的页面将会是杂乱无章或缺少美感的页面,我们以上面简单的用户主页为例子演示如何使用css以及css的功能。
效果:

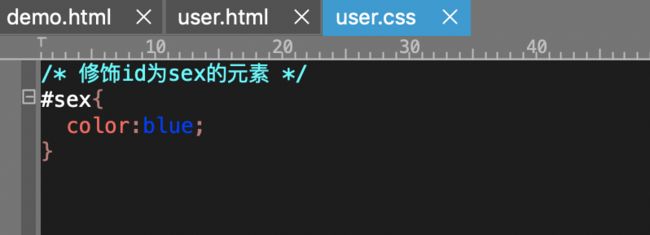
代码:

css:
4.js
css使页面有了很好看的样式,但是却没有很好的交互性,何为交互性?就是用户在使用产品时的浏览、点击、切换使之方便、快捷、平滑都很合理,很友好。
而js(JavaScript)则是增加网页的动态功能,它定义了网页的行为,提高用户体验。比如js可以监控到用户的点击,滑动等动作,然后根据用户的这些动作来做一些操作。
我们还是以上面简单的用户主页为例子,用js(或jquery)来实现用户修改用户名或者性别信息。
代码:
效果:


一个大概的修改用户信息流程:
- 点击修改后通过js现实出输入框
- 在用户输入的时候用js监听输入框内容,及时提醒用户新的用户名是否可用
- 再用户点击提交后,用ajax提交,并且做防止重复提交的操作
- 服务端反馈后用js做提示即可
上面只是给大家做了一个非常简单的js效果,给零基础的朋友演示js是什么,有什么功能,但是js的功能远不止这些,现在的js已经在前端、后端以及app中占据着重要的地位,当然还有使用在反爬虫的js混淆。
三、总结
由于篇幅原因,猪哥这里只给大家演示一些非常基础非常简单的功能,如果想学习网页的制作同学们可以自己去网上学习,这里推荐一个学习网站:菜鸟教程,希望大家都学习一些前端知识,因为爬虫的第一步就是分析网页,然后再根据网页数据是内嵌在html标签中,还是js动态加载,或者网站使用加密或混淆的反扒技术。当遇到反扒高手时,我们就需要去仔仔细细的分析js,这也被称为解毒的过程(反扒工程师在代码里投毒)。所以爬虫与反扒的斗争可谓其乐无穷!
更多爬虫知识及案例,敬请扫描下方二维码关注猪哥爬虫专栏!
