控制器
正式开始之前,先来回顾一下上节课的内容。
再来用上帝视角看一下今天要讲的2个主角Deployment和ReplicaSet之间的关系是什么?

ReplicationController(rc)
Replication Controller简称RC,RC是Kubernetes系统中的核心概念之一,简单来说,RC可以保证在任意时间运行Pod的副本数量,能够保证Pod总是可用的。如果实际Pod数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当Pod失败、被删除或者挂掉后,RC都会去自动创建新的Pod来保证副本数量,所以即使只有一个Pod,我们也应该使用RC来管理我们的Pod。

解释上面这个图:
- PodA是直接通过pod方式创建的。
- PodB是通过rc、rs或者deploy创建的。
- 当node1出现问题时,因为PodB有控制器保障数量,会自动找合适的节点进行调度,而PodA并不会。
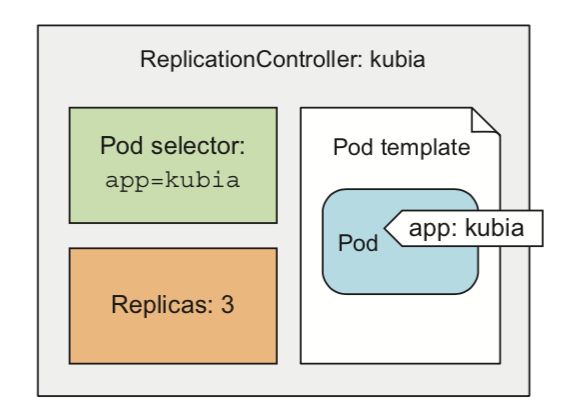
如上图所示,ReplicationController主要包含三个部分:
- Pod selector(用来定位pod)
- replicas(定义副本梳理)
- pod template(被控制pod的模板)

如上图所示,我们来看一下当一个pod被删除时,ReplicationController的工作过程。当kubia-53thy被删除后,ReplicationController发现数量不匹配(期望3个),立刻在创建一个新的pod出来。
ReplicaSet(rs)
Replication Set简称RS,随着Kubernetes的高速发展,官方已经推荐我们使用RS和Deployment来代替RC了,实际上RS和RC的功能基本一致,目前唯一的一个区别就是RC只支持基于等式的selector(env=dev或environment!=qa),但RS还支持基于集合的selector(version in (v1.0, v2.0)。
代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
- 用户期望的pod副本数量
- 标签选择器,判断哪个pod归自己管理
- 当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。(大家想想这是什么原因)
apiVersion: apps/v1 #api版本定义
kind: ReplicaSet #定义资源类型为ReplicaSet
metadata: #元数据定义
name: myapp
namespace: default
spec: #ReplicaSet的规格定义
replicas: 2 #定义副本数量为2个
selector: #标签选择器,定义匹配pod的标签
matchLabels:
app: myapp
release: canary
template: #pod的模板定义
metadata: #pod的元数据定义
name: myapp-pod #自定义pod的名称
labels: #定义pod的标签,需要和上面定义的标签一致,也可以多出其他标签
app: myapp
release: canary
environment: qa
spec: #pod的规格定义
containers: #容器定义
- name: myapp-container #容器名称
image: ikubernetes/myapp:v1 #容器镜像
ports: #暴露端口
- name: http
containerPort: 80
Deployment(deploy)
工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
generation: 14
labels:
app: fbs-cc-v2
mode: new-production
role: default
tier: backend
name: fbs-cc-v2
namespace: new-production
spec:
progressDeadlineSeconds: 600
replicas: 8 #是可以选字段,指定期望的pod数量,默认是1。
revisionHistoryLimit: 10
selector: #是可选字段,用来指定 label selector ,圈定Deployment管理的pod范围。
matchLabels:
app: fbs-cc-v2
mode: new-production
role: default
tier: backend
strategy: #指定新的Pod替换旧的Pod的策略。 .spec.strategy.type 可以是"Recreate"或者是 "RollingUpdate"。"RollingUpdate"是默认值。
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template: #是 pod template. 它跟 Pod有一模一样的schema,除了它是嵌套的并且不需要apiVersion 和 kind字段。
……
strategy(更新策略):
- Recreate: 重建式更新,就是删一个建一个。类似于ReplicaSet的更新方式,即首先删除现有的Pod对象,然后由控制器基于新模板重新创建新版本资源对象。
- rollingUpdate:滚动更新,简单定义 更新期间pod最多有几个等。可以指定maxUnavailable 和 maxSurge 来控制 rolling update 进程。
- maxSurge:.spec.strategy.rollingUpdate.maxSurge 是可选配置项,用来指定可以超过期望的Pod数量的最大个数。该值可以是一个绝对值(例如5)或者是期望的Pod数量的百分比(例如10%)。当MaxUnavailable为0时该值不可以为0。
- maxUnavailable:.spec.strategy.rollingUpdate.maxUnavailable 是可选配置项,用来指定在升级过程中不可用Pod的最大数量。该值可以是一个绝对值(例如5),也可以是期望Pod数量的百分比(例如10%)。通过计算百分比的绝对值向下取整。
例如,该值设置成30%,启动rolling update后新的ReplicatSet将会立即扩容,新老Pod的总数不能超过期望的Pod数量的130%。旧的Pod被杀掉后,新的ReplicaSet将继续扩容,旧的ReplicaSet会进一步缩容,确保在升级的所有时刻所有的Pod数量和不会超过期望Pod数量的130%。
例如,该值设置成30%,启动rolling update后旧的ReplicatSet将会立即缩容到期望的Pod数量的70%。新的Pod ready后,随着新的ReplicaSet的扩容,旧的ReplicaSet会进一步缩容确保在升级的所有时刻可以用的Pod数量至少是期望Pod数量的70%。

[root@master1 ~]# kubectl get deploy fbs-cc-v2 -n new-production
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
fbs-cc-v2 8 8 8 8 29d
- DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
- CURRENT:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
控制循环(调谐)
实际上,k8s的控制器它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环。
比如,现在有一种待编排的对象 X,它有一个对应的控制器。那么,我就可以用一段 Go 语言风格的伪代码,为你描述这个控制循环:
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}

实际状态
实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
期望状态
期望状态一般来自于用户提交的 YAML 文件。
比如,Deployment 对象中 Replicas 字段的值。很明显,这些信息往往都保存在 Etcd 中。
接下来,以 Deployment 为例:
- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod。
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。
k8s使用的是一种“用一种对象管理另一种对象”的“艺术”。
其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
而被控制对象的定义,则来自于一个“模板”。比如,Deployment 里的 template 字段。可以看到,Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义,丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,其实都是根据这个 template 字段的内容创建出来的。像 Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate。

如上图所示,类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。
现在,请思考一个问题,假如我把其中一个pod的label改了,会发生什么?


对pod模板内容进行修改,只有在删除pod,rc尝试重新创建pod时才会用新的pod模板。

在删除一个rc时,如果不想同步删除pod 要加上--cascade=false,当rc删除后,这些pod会变成没人管的“孤儿”。
实战体验
#查看deploy
kubectl get deploy -n mengtms1
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
boss-dahai-com 1 1 1 1 41d
cc-dahai-com 1 1 1 1 41d
libs-dahai-com 1 1 1 1 41d
#查看replicaset
kubectl get rs -n mengtms1
NAME DESIRED CURRENT READY AGE
boss-dahai-com-68788f7775 0 0 0 41d
boss-dahai-com-6f5987c966 1 1 1 3d
cc-dahai-com-77f7bf5867 0 0 0 41d
cc-dahai-com-78df67c954 1 1 1 41d
libs-dahai-com-5db64968f7 1 1 1 41d
#查看pod
kubectl get pods --show-labels -n mengtms1
NAME READY STATUS RESTARTS AGE LABELS
boss-dahai-com-6f5987c966-d2zkn 1/1 Running 0 3d app=boss-dahai-com,pod-template-hash=2915437522,tier=frontend
cc-dahai-com-78df67c954-qr6zq 1/1 Running 0 41d app=cc-dahai-com,pod-template-hash=3489237510,tier=backend
libs-dahai-com-5db64968f7-nxw26 1/1 Running 0 41d app=libs-dahai-com,pod-template-hash=1862052493,tier=backend
# 扩容
## 通过scale命令
kubectl scale deployment cc-dahai-com --replicas 3 -n mengtms1
deployment "cc-dahai-com" scaled
## 通过修改yaml文件/修改deploy文件
kubectl edit deployment cc-dahai-com -n mengtms1
……
replicas: 3
……
## 查看pod数变化
kubectl get deploy -n mengtms1
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
boss-dahai-com 1 1 1 1 41d
cc-dahai-com 3 3 3 3 41d
libs-dahai-com 1 1 1 1 41d
## 滚动升级/蓝绿部署
kubectl scale deployment cc-dahai-com --replicas 10 -n mengtms1
kubectl edit deployment cc-dahai-com -n mengtms1
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
boss-dahai-com 1 1 1 1 41d
cc-dahai-com 10 10 10 10 41d
libs-dahai-com 1 1 1 1 41d
### fbs-cc:master-20190704174559
### fbs-cc:master-20190704103840
## 观察滚动升级过程
kubectl rollout status deployment cc-dahai-com -n mengtms1
Waiting for rollout to finish: 2 out of 10 new replicas have been updated...
# 金丝雀环境/灰度发布/ABTest
## 将deploy设置为pause
kubectl set image deploy cc-dahai-com cc-dahai-com=image.docker.dahai.com/apps/fbs-cc:master-20190704174559 -n mengtms1 && kubectl rollout pause deploy cc-dahai-com -n mengtms1
## 观察滚动升级过程,发现不再持续更新
kubectl rollout status deployment cc-dahai-com -n mengtms1
Waiting for rollout to finish: 0 out of 10 new replicas have been updated...
## 查看pod
kubectl get pods -l app=cc-dahai-com -n mengtms1 -w
## 确保更新的pod没问题了,继续更新,恢复滚动升级过程
kubectl rollout resume deploy cc-dahai-com -n mengtms1
# 回滚
## 查看版本
kubectl rollout history deploy cc-dahai-com -n mengtms1
deployments "cc-dahai-com"
REVISION CHANGE-CAUSE
1
2
3
6
7
## 查看对应版本的信息
kubectl rollout history deploy cc-dahai-com -n mengtms1 --revision=2
deployments "cc-dahai-com" with revision #2
Pod Template:
Labels: app=cc-dahai-com
pod-template-hash=3489237510
tier=backend
Containers:
cc-dahai-com:
Image: image.docker.xxxxx/apps/cc-dahai-com:latest
Port:
Limits:
cpu: 400m
memory: 1Gi
Requests:
cpu: 20m
memory: 100Mi
Liveness: http-get http://:9001/ping delay=0s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:9001/ping delay=0s timeout=1s period=10s #success=1 #failure=3
Environment:
NAMESPACE: (v1:metadata.namespace)
CLUSTER: dev
OCEAN_ENV: Test
ENV_TYPE:
BASE_MODE: super
OCEAN_MODE: mengtms1
SERVER_USER_ENV: mengtms1
OCEAN_APP: cc-dahai-com
SYSTEM_NAME: cc.xxxxx
Mounts:
/libs.xxxxx from libs-vol (rw)
Volumes:
libs-vol:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mengtms1-libs-pvc
ReadOnly: false
## 回到上个版本
kubectl rollout undo deploy cc-dahai-com -n mengtms1
## 回到特定版本
kubectl rollout undo deploy cc-dahai-com -n mengtms1 --to-revision=1
DaemonSet

DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。
Job
只要完成就立即退出,不需要重启或重建。
Cronjob
周期性任务控制,不需要持续后台运行,
StatefulSet
管理有状态应用