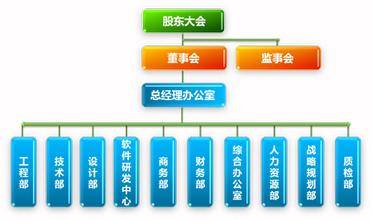
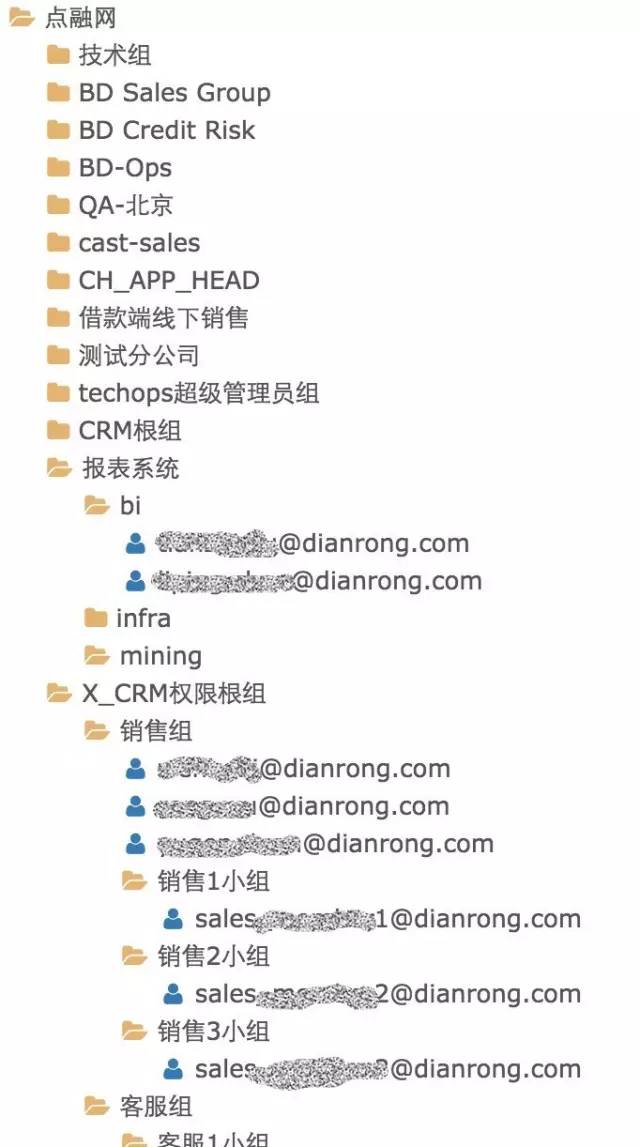
我们时常会遇到这样的场景,如:组织结构图、回复评论的评论链、用于组织资源的树形资源组。
如图:
而作为一名程序员如果你特别纠结于类似这样的问题“我们的需求方想要支持多少层”, “我觉得管理或者维护树形结构的代码简直烦透了”,那么你应该试一试我下面提到的第二种树形结构的解决方案。
到目前为止我在实战中曾使用过三种方式来实现这种hierarchical-data:
Adjacency list (邻接表)
Closure table (闭包表)
Path enumeration (路径枚举)
因为不想篇幅太长,本文仅详细介绍Closure table,并与Adjacency list做少许对比,文章附录中会有资料链接,里面有四种hierarchical-data详解(上面三种 + Nested Set )
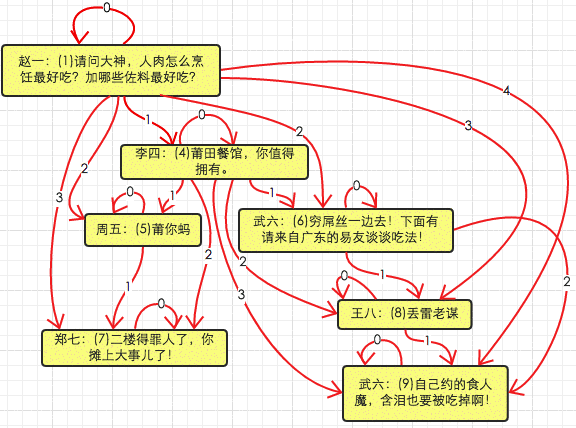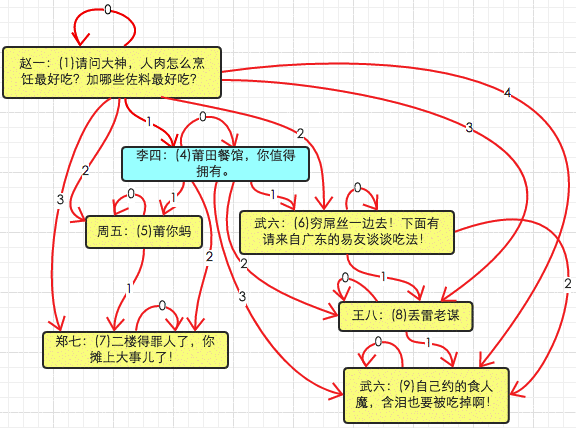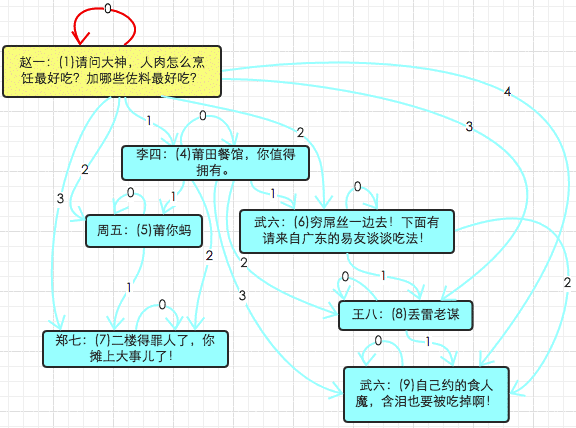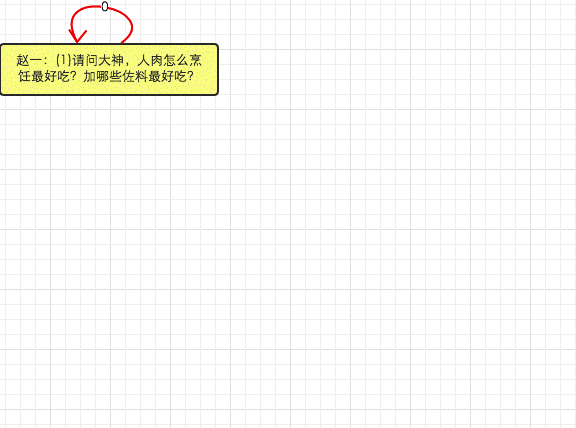
我这里以一个网易评论树来做讲解【已编号(1)-(9)】:
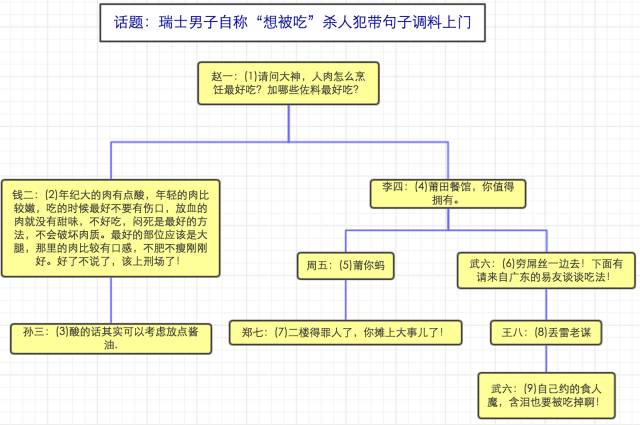
两种设计共有的数据:

设计1:Adjacency list(邻接表)

comment table data:

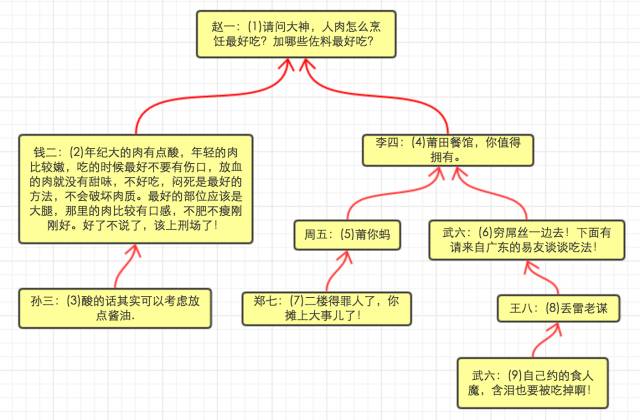
这种设计非常直观,在表comment上添加一个parent_id字段, 每一条记录都知道自己的父记录是谁. comment之间数据结构关系如下图所示:
设计2:Closure table (闭包表)
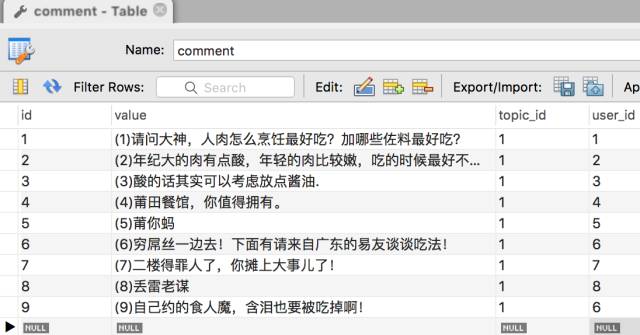
comment table data:
comment_path table data:

这种设计, comment table本身并不保存 评论与评论之间的关系, 而将该关系用另外一张表(comment_path)保存起来, 理论上讲需要O(n²)的空间来存储关系,但现实中并不会需要这么多。
comment之间数据结构关系如下图所示:
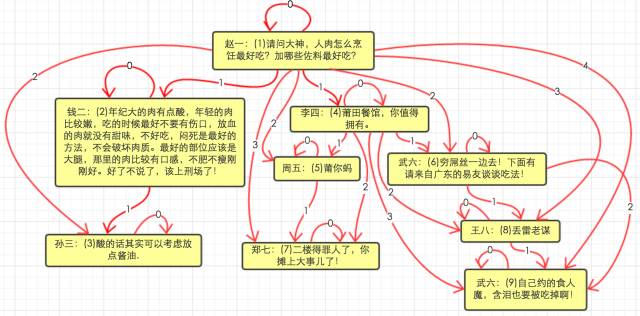
每根红线都是comment_path中的一条数据, 线条上的数字为depth。
我们直接上需求
查询直接回复4号comment的comment(父查子)
Adjacency :
select * from comment c1 where c1.parent_id=4;
Closure :
select c.* from comment c join comment_path cp on (c.id = cp.descendant) where cp.ancestor = 4 and depth = 1;

查询所有回复4号的子comment(父查所有子)
Adjacency :
思路为递归查询(使用SQL99的CTE 或 oracle的connect by语法),不支持递归查询的数据库(如mysql) 将无法使用一条sql语句满足不固定层级数量的需求.
Closure :
select c.* from comment c join comment_path cp on (c.id = cp.descendant) where cp.ancestor = 4;
--如果你需要保留层级关系, 则将cp中的值也返回即可

查询所有7号的 父comment(子查所有父)
Adjacency :
方案与需求2类似
Closure :
select c.* from comment c JOIN comment_path cp on (c.id = cp.ancestor) where cp.descendant = 7;

添加一条子回复到 6号comment上(新增)
Adjacency :
insert into comment (value, parent_id, topic_id, user_id) values('(10)我以gin食阼啦', 6, 1, 2);
Closure :
step a: insert into comment(value, topic_id, user_id) values('(10)我以gin食阼啦', 1, 2);
-- 拿到该句返回的id, 假设为10
step b: insert into comment_path (ancestor, descendant, depth) select cp.ancestor, 10, cp.depth+1 from comment_path as cp where cp.descendant=6 union all select 10, 10, 0;
-- 只要拥有子comment_id为6作为子节点的节点,全都新增一个id为10,depth+1的子节点 并且插入一个10, 10, 0的节点.

从评论链中删除4号comment及其子comment(删除子或者子树)
Adjacency :
由于parent_id是可以为空的foreign key约束 ==> 递归将所有4号的子节点从栈底开始 删除到栈顶。
Closure :
delete a from comment_path a join comment_path b on (a.descendant = b.descendant) where b.ancestor=4;
-- 这句话等价于 "delete from comment_path where descendant in (select descendant from comment_path where ancestor = 4);”, 但mysql会报from句子中的表不能用于update的错误.
将6号comment的父comment更改为2号(移动子或者子树)
Adjacency :
update comment set parent_id = 2 where id = 6;
Closure :
step a:
delete a from comment_path as a join comment_path as d on a.descendant = d.descendant left join comment_path as x on x.ancestor = d.ancestor and x.descendant = a.ancestor where d.ancestor = 6 and x.ancestor is null;
--这样删除的原因和需求5一致.
step b:
insert into comment_path (ancestor, descendant, depth) select supertree.ancestor, subtree.descendant, supertree.depth+subtree.depth+1 from comment_path as supertree join comment_path as subtree where subtree.ancestor = 6 and supertree.descendant = 2;
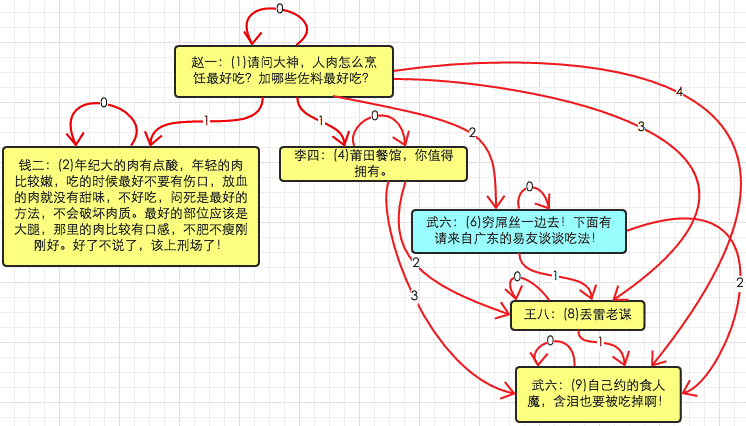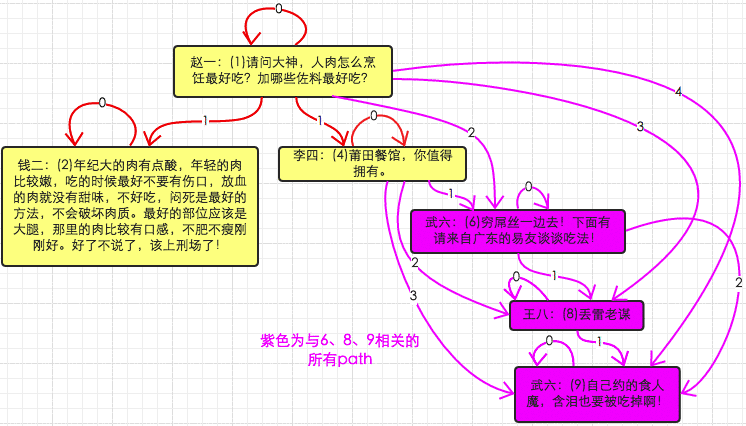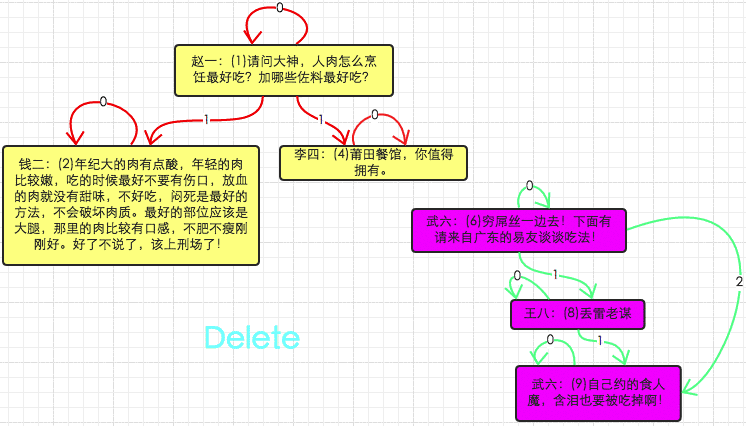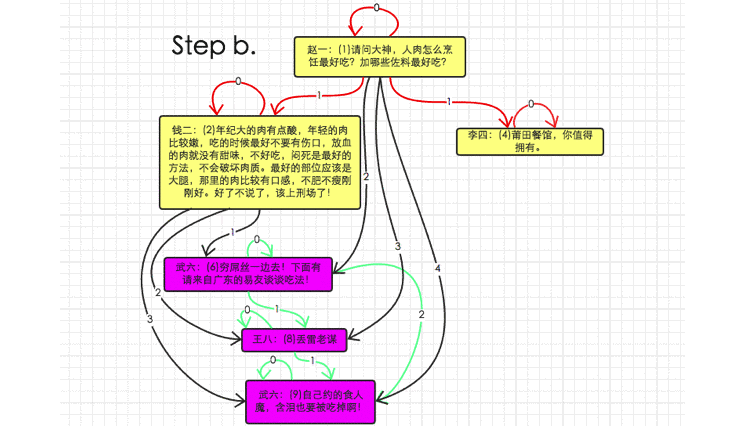
以上6种需求覆盖了最为常用的几种情况,解决了我基本上所有的问题,想要更多的例子各位看官可以后台小纸条我。
结束语
这是多层级关系解决方案中非常好的一种,希望能帮助各位解决一些问题, 找到适合自己项目的解决方案。下面的最后一个link是我这篇文章github地址,其中有我做例子用的sql语句,看官可直接参考。
更多相关资料:
http://www.slideshare.net/billkarwin/models-for-hierarchical-data
https://www.percona.com/blog/2011/02/14/moving-subtrees-in-closure-table/
http://stackoverflow.com/questions/23030755/depth-in-mysql-and-closure-table-trees
http://mp.weixin.qq.com/s?__biz=MjM5NjAwNzI0MA==&mid=2651941866&idx=2&sn=158d0b9b6ed93c15c6876126352d48d9&scene=23&srcid=0511Oe59cZtONNzdntkXuqaw#rd
https://detail.tmall.com/item.htm?spm=a230r.1.14.9.axx0DG&id=45220665214&cm_id=140105335569ed55e27b&abbucket=8
https://github.com/Agileaq/Hierarchical_Design
补充延伸
有朋友想要了解 controller 是怎样转换数据库数据以及前端js是如何控制和展现该数据, 我这里补充一下大致的思路:
从数据库中增删改查节点,上面的6种case都覆盖了, 那么我的java后端是怎么做的呢?
准备工作:
做一个entity映射, 里面包含commentId, commentValue
抽象出一个叫做“Node”的返回bean class, json形式如下:
{
id: “数据库中的唯一标识”,
label: “界面上应该显示的一段文本”,
type: “该节点的类型, 对于comment来说可以是cmt”, //该字段可以用作界面显示每一个节点的图片类型判断
children: “子node”,
……(其他您想加上去的字段)
}
step 1. 从db拉出所需数据
在Service中 getCommentsById 查询comment表, -- 根据我想要拉出的root节点的id查到该root及该root下的所有节点信息
e.g. select comment.id, comment.value
from comment join comment_path on (comment.id = comment_path.descendant) where comment_path.ancestor = ?;
在Service中 getCommentsLinks, -- 根据我拉出的节点id, 找到其作为depth=1的子节点的comment_path
e.g.
select t1.descendant, t1.ancestor from comment_path as t1
join (select comment.id, comment.value
from comment join comment_path on (comment.id = comment_path.descendant)
where comment_path.ancestor = ?) as t2 on t1.descendant = t2.id where t1.depth=1 and t1.descendant <> ?;
step 2. 构建即将返回的对象
foreach 数据库映射的comment entity对象即可将其转化为”node” bean, 与此同时用一个map将node的id 和 转化的bean保存在内存中。
step 3. 组装返回对象
foreach step1中装comment_path的对象list, 根据里面保存的ancestorId和descendantId可以从step2中的map取出父和子的”node”bean, 并且将它们组装起来。
step 4. 返回根node(框架会将该node对象序列化成json给前端)。
step 5. 前端展现这些数据的同时,往每一个展现节点上添加一些js事件即可。
本文作者:钱晟龙 Arc_Qian(点融黑帮),现任点融网架构组产品研发工程师,主要任务是思考并尝试解决各类点融网迈出第一公里之后遇到的现实问题。