ArcFace算法笔记
论文:ArcFace: Additive Angular Margin Loss for Deep Face Recognition
论文链接:https://arxiv.org/abs/1801.07698
代码链接:https://github.com/deepinsight/insightface
这篇文章提出一种新的用于人脸识别的损失函数:additive angular margin loss,基于该损失函数训练得到人脸识别算法ArcFace(开源代码中为该算法取名为insightface,二者意思一样,接下来都用ArchFace代替)。ArcFace的思想(additive angular margin)和SphereFace以及不久前的CosineFace(additive cosine margin )有一定的共同点,重点在于:在ArchFace中是直接在角度空间(angular space)中最大化分类界限,而CosineFace是在余弦空间中最大化分类界限,这也是为什么这篇文章叫ArcFace的原因,因为arc含义和angular一样。除了损失函数外,本文的作者还清洗了公开数据集MS-Celeb-1M的数据,并强调了干净数据的对实验结果的影响,同时还对网络结构和参数做了优化。总体来说ArcFace这篇文章做了很多实验来验证additive angular margin、网络结构设计和数据清洗的重要性,非常赞。
不管是SphereFace、CosineFace还是ArcFace的损失函数,都是基于传统的softmax loss进行修改得到的,因此公式1就是softmax loss损失函数。
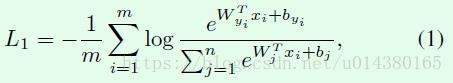
首先把偏置bj设置为0,,然后权重和输入的内积用下面式子表示。
![]()
当用L2正则化处理Wj使得||Wj||=1,L2正则化就是将Wj向量中的每个值都分别除以Wj的模,从而得到新的Wj,新的Wj的模就是1。从公式1就可以得到下面这个式子,这一步操作在SphereFace、CosineFace中都有做。
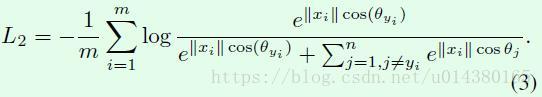
然后一方面对输入xi也用L2正则化处理,同时再乘以一个scale参数s;另一方面将cos(θyi)用cos(θyi+m),这部分是ArcFace的核心,公式也是非常简洁,m默认取0.5。于是就得到下面的公式9,L7就是additive angular margin loss。在限制条件(10)中,前两个正是对权重和输入特征的L2正则化处理。

因为本文会经常对比SphereFace和CosineFace,因此这里给出SphereFace中的angular softmax loss的公式:
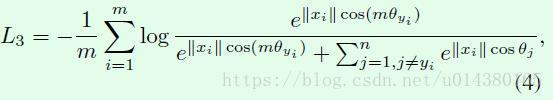
和CosinFace中的additive margin softmax loss公式:

接下来看看几个损失函数的分类边界(decision boundary),这里以二分类为例。对于二分类而言,分类边界就是样本属于两个类别的概率相等,而概率就是前面公式1、3、4、8、9中的log函数的输入。softmax比较容易理解,假设某个样属于类别1的概率是公式1中log函数的输入,那么属于类别2的概率只是将log函数输入的分子换成类别2而已,分母是不变的,又因为以e为底的指数函数又是递增函数,所以直接让两个类别的指数相等就能得到Table1中softmax的分类边界函数。W-Norm softma**x是对权重做L2正则化、偏置b置为0后的损失函数,对应前面的公式3,和softmax类似,直接让两个类别的指数相等就能得到Table1中W-Norm softmax的分类边界函数。Table1中**SphereFace的分类边界准确讲是类别1的(真实标签是1),如果是类别2,则是||x||(cosθ1-cosmθ2)=0,因此有两条分类界限!怎么计算得到的?令公式4中log函数输入的分子e^||xi||cos(mθyi)=e^||x||cos(θj)即可,分母是不变的,因为分母只跟真实标签相关。同理,F-Norm SphereFace是在SphereFace的基础上对输入特征做L2正则化并用s替换后的算法,与SphereFace同理,Table1中显示的分类界限是类别1的。CosinFace的损失函数如前面公式8所示,同样Table1中的分类界限是类别1的,如果是类别2,则分类界限是s(cosθ2-m-cosθ1)=0。同理在Table1中的ArcFace分类界限是类别1的,如果是类别2,则分类界限是cos(θ2+m)-cos(θ1)=0。因此SphereFace、F-Norm Sphereface、CosineFace和ArcFace在二分类中的分界线都是2条。
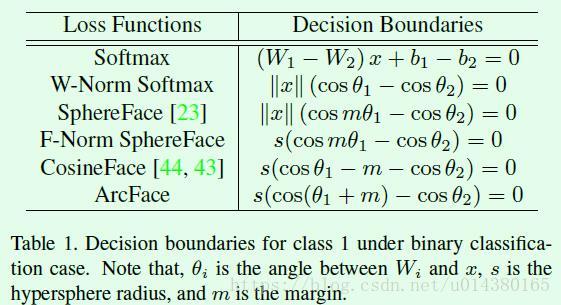
了解了Table1中分类界限的计算后,就容易理解Figure3中的图了,因为基本上就是按照Table1中的公式来画的,看懂Figure3就基本上明白为什么这几个损失函数能够提高人脸识别的效果。softmax和W-Norm softmax比较简单,坐标轴是cosθ1和cosθ2,分界线的斜率是1。SphereFace中的坐标轴是θ1和θ2,其中class1的线对应Table1中的公式,因为m小于1,cos函数在该输入范围内是递减函数,所以斜率(cosmθ1/cosθ2)大于1。class2那条线同理,同时两条线都过原点。CosinFace中的坐标轴是cosθ1和cosθ2,class1那条线相当于将过原点的斜率为1的线向上平移m的结果,为什么这么说?假设θ2=0,那么class1线就是cosθ1=m,又因为纵坐标轴是cosθ1,因此就是平移m,class2同理。ArchFace中的坐标轴是θ1和θ2,class1这条线相当于将过原点的斜率为1的线向上平移m的结果(注意,虽然都是平移m,但是这里的坐标轴和CosinFace不同,因此平移的量不一样)。
因此这里有个非常重要的结论:在ArchFace中是直接在角度空间(angular space,也就是横纵坐标是角度θ1和θ2,不是softmax或CosineFace中的cosθ1和cosθ2)中最大化分类界限。

首先解释下target logit的概念,target logit指的是网络的全连接层输出,假设你的损失函数是softmax loss,也就是下面这个式子:

那么下面这个就是target logit
![]()
因此换句话说target logit就是全连接层输出矩阵中预测类别为真实类别的输出。
再来看下面这个关于target logit的曲线图,尤其在30度到60度范围内,ArcFace的效果要好于其他算法。同时也可以看出SphereFace超参数调整需要一定技巧。

图(c)是ArcFace和CosineFace在训练过程中θ的分布情况,训练过程包括起始(start)、中途(middle)和最后(end)。起始时θ基本围绕90度呈正态分布,当训练到中途时,θ值的中心值逐渐往小移动,到最后时,ArcFace的θ值中心在30到40之间,CosineFace的θ值在40左右,因此ArcFace的效果要优于CosineFace。

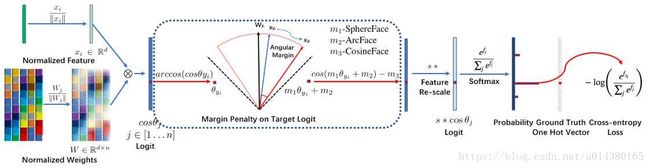
代码链接中的这张图非常好地总结了几种人脸识别算法的流程。输入xi是1*d的向量,表示输入的特征向量,对该向量执行L2正则化操作就得到xi/||xi||。对该向量W是d*n的矩阵,n表示分类的类别数,因此对每一列(也就是Wj)都执行L2正则化操作,就得到Wj/||Wj||。xi/||xi||和Wj/||Wj||做矩阵相乘得到全连接层的输出,这个输出其实就是cosθj(严格讲是||xi/(||xi||)||*||Wj/(||Wj||)||*cosθj,因为前面两项都是1,所以就是cosθj),其中j属于[1…n]。然后对该输出中对应真实标签的值(cosθyi)执行反余弦操作就能得到θyi,yi就表示真实标签。因为SphereFace、ArcFace和CosineFace中都有m参数,所以这里分别用m1、m2和m3表示,因此这3个算法整合在一起就是cos(m1θyi+m2)-m3。然后乘以一个scale参数s,最后该结果作为以e为底的指数函数的指数送到softmax函数,最后就得到预测的输出概率。
实验结果:
这篇文章的对比实验很多。
因为在ImageNet数据集上预训练模型时输入都是224*224,而这里的人脸数据输入是112*112,因此如果直接将112*112的数据作为预训练模型的输入会使得原本最后提取到的特征维度是7*7变成3*3,因此作者将预训练模型的第一个7*7的卷积层(stride=2)替换成3*3的卷积层(stride=1),这样第一个卷积层就不会将输入的维度缩减,因此最后还是能得到7*7的输入,实验中将修改后的网络在命名上加了字母“L”,比如SE-LResNet50D。经过实验对比最后选择L系列结构。

Table3是关于输出层的设计结果对比。A表示Use global pooling layer(GP),B表示Use one fully connected (FC) layer after GP,C表示Use FC-Batch Normalisation (BN) after GP,D表示Use FC-BN-Parametric Rectified Linear Unit (PReLu) after GP,E表示Use BN-Dropout -FC-BN after the last convolutional layer。通过实验对比最后选择E。

Table4是关于改进版residual block的结果对比,网络结构名带“IR”表示改进版。通过实验对比最后选择IR。

改进版的residual block如Figure7所示。
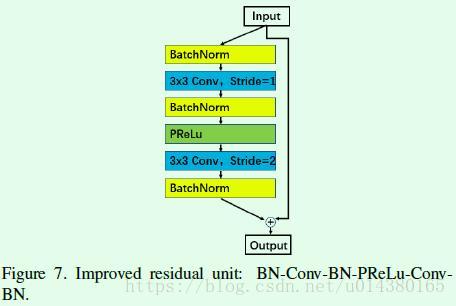
Table8是不同的ArcFace算法的实验结果、速度、模型大小对比。Table9是几个人脸识别算法的实验结果对比,最后两列(R)代表实验是在经过清洗后的数据集上做的。

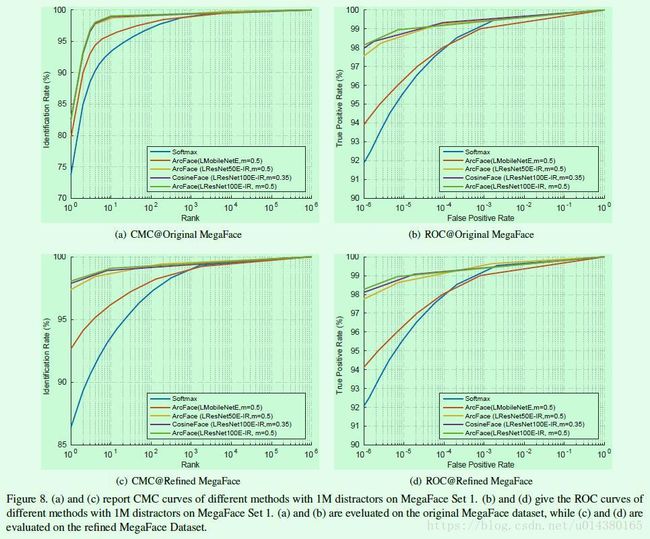
Figure8是几个算法的CMC曲线和ROC曲线对比。