【论文阅读】Learning from Imbalanced Data
论文阅读笔记《Learning from imbalanced data》
He H, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge & Data Engineering, 2008 (9): 1263-1284.
文章目录
- 论文阅读笔记《Learning from imbalanced data》
- 当前主要问题
- 不平衡数据的解决方案
- 1 采样方法
- 1.1 随机过采样和欠采样
- 1.2 Informed Undersampling
- 1.3 Synthetic Sampling with Data Generation
- 1.4 Adaptive Synthetic Sampling
- 1.5 Sampling with Data Cleaning Techniques
- 2 不平衡数据的代价敏感
- 3 基于核函数和主动学习方法
- 3.1 Kernel-Based Learning Framework
- 不平衡分类的评估指标
- 1 单一评估指标
- 2 ROC曲线
- 3 Precision-Recal 曲线
- 4 代价曲线
本文主要是关注二分类中类别不平衡的问题。
不平衡学习的问题主要是解决:在未充分表示的数据和严重的类别分布偏差的情况下,学习算法性能的问题。
当前主要问题
- 单一的总体评价如 accuracy 和 error rate在不平衡学习中无法提供有效的信息
不平衡数据的解决方案
1 采样方法
1.1 随机过采样和欠采样
- 随机过采样:对于数据量少的样本,随机采样并通过复制加入原始样本集合,以此来扩充数量,使得正负类别平衡。
缺点:由于过采样只是将复制数据重复添加到原始数据集,会使得某些句子的多个实例变得“束缚”,导致过度拟合。 - 随机欠采样:随机从数据量多的类别中移除部分样本。
缺点:从多数类中删除样本可能会导致分类器遗漏与多数类相关的重要特征。
1.2 Informed Undersampling
克服传统随机欠采样方法中信息丢失的问题。
EasyEnsemble: 从多数类中独立采样几个子集,并基于每个子集与少数类的组合训练多个分类器,开发集成学习系统。
KNN实现欠采样: NearMiss-1,NearMiss-2,Near-Miss-3,其中NearMiss-2是选择与三个最远的少数类样本的平均距离最小的多数类样例,实验证明这种方法效果最好。
1.3 Synthetic Sampling with Data Generation
SMOTE算法: 基于现有少数类样本之间的特征空间相似性来人工造数据。
缺点:SMOTE为每个原始少数类的样本生成相同数量的合成数据样本,不考虑相邻的样本,这增加了类之间出现重叠的可能性。
1.4 Adaptive Synthetic Sampling
克服SMOTE算法的缺点。
ADASYN算法: 使用密度分布作为标准,自动确定需要为每个少数例子生成的合成样本的数量。自适应地改变不同少数例子的权重以补偿偏斜的分布。
1.5 Sampling with Data Cleaning Techniques
数据清理技术,如Tomek links ,可以有效消除采样方法导致的数据重叠问题。
2 不平衡数据的代价敏感
代价敏感是通过定义不同的代价矩阵来描述不同的错分样本,来解决不平衡问题。
3 基于核函数和主动学习方法
3.1 Kernel-Based Learning Framework
不平衡数据对SVM的影响主要是因为,SVM试图最小化总误差,因此它本质上偏向于多数概念。
不平衡分类的评估指标
1 单一评估指标
Accuracy和ErrorRate这两个评价指标不能准确表现分类器的性能。
因此,通常使用Precision,Recall,F-measure,G-mean这些指标对模型进行评估:

因为Precision和Recall对样本分布是不敏感的,因此可以用来评估不平衡分类模型的性能。
F-measure将Precision和Recall相结合,加权系数可由用户指定,但是F-measure仍然对数据分布敏感。
G-mean根据正类Precision和负类Precision比率来估计归纳偏差程度。
2 ROC曲线
ROC使用TPR和FPR进行评估:
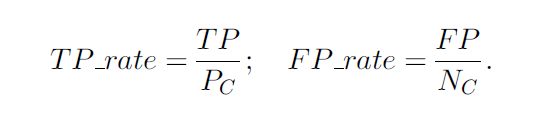
ROC曲线提供了一个分类器的收益(TP表示)和成本(FP表示)之间的权衡关系的表示。
示例:

缺点: 在数据高度不平衡的情况下,ROC曲线可能会对分类器性能展示出过度乐观的结果。此时,可以使用PR曲线进行评估。
3 Precision-Recal 曲线
PR曲线
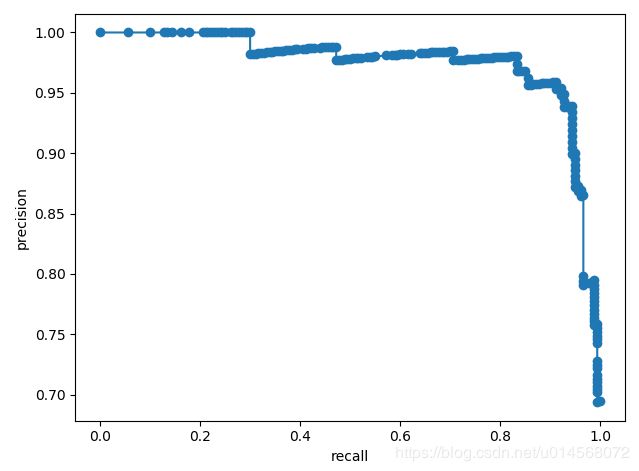
ROC曲线的最佳值位于左上角,而PR曲线最佳值位于右上角。但是不能保证优化ROC空间中的AUC,能与优化PR中的AUC相对应。
PR曲线能够在高度不平衡数据下有效评估模型性能的原因主要是:
- 当负样本远远超过正样本(N>>P)时,如果分类器的性能在FP(false positive)上有很大变化,它并不会显著改变FP_rate,因为分母(负例数)过大,因此ROC并不能准确捕获这种情况。
- PR曲线则考虑了TP关于TP+FP的比率,因此当FP数量急剧增加的时候,它仍能够正确评估分类器性能。
4 代价曲线
成本曲线是一种成本敏感的评估方式,它能够表现分类器在不同的错误分类成本和类分布上的性能的能力。
ROC曲线中的每个点对应到成本空间是一条线,其中(FP, TP)在成本曲线中的对应关系如下:
![]()
其中PCF(+)是样本为正类的概率。
References: Drummond, C., & Holte, R. C. (2004). What ROC curves can’t do (and cost curves can). ROCAI (pp. 19–26).