【AI视野·今日CV 计算机视觉论文速览 第157期】Mon, 16 Sep 2019
AI视野·今日CS.CV 计算机视觉论文速览
Mon, 16 Sep 2019
Totally 33 papers
?上期速览✈更多精彩请移步主页

Interesting:
?DeepHomography内容感知的单应性估计, 由于传统单应性估计方法对于图像质量十分敏感,低纹理和低光照会造成估计误差。先前基于学习的估计方法大多为合成图像的监督学习或基于航空图像的非监督学习,忽略了深度不一致在单应性中的作用。同时对于图像的统一处理忽视了前景和动态目标。这篇文章提出了一种新的非监督方法,首先对于图像进行掩膜学习排除异常区域(无纹理),随后基于得到的特征计算损失代替了直接从图像得到损失,同时还提出了一个新的数据集包含了多种具有挑战的情况。(from 电子科大 旷视)

排除动态、模糊和低纹理的掩膜生成:

一些数据集内得到的结果:
code:https://github.com/JirongZhang/DeepHomography
?荧光显微镜数据合成与实例分割, 研究人员提出了一种合成方法生成荧光显微镜模拟数据集,并利用空间约束的循环一致性对抗网络来进行细胞核检测。(from 普渡 印第安纳大学)
训练方法与合成数据:
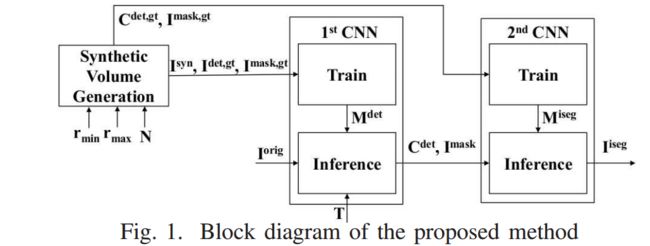

细胞核检测与掩膜分割,下图为语义分割网络:


分割结果:

数据合成方法:Nuclei Segmentation of Fluorescence Microscopy Images Using Three Dimensional Convolutional Neural Networks
Three Dimensional Fluorescence Microscopy Image Synthesis and Segmentation,cvpr2018 CVMI workshop
实验室主页:https://engineering.purdue.edu/~micros/publications.html

?FakeSpotter一个AI合成假脸欺诈检测基线模型, (from 南洋理工、九州大学、阿里巴巴、小米)
利用每一层神经元的行为作为特征:
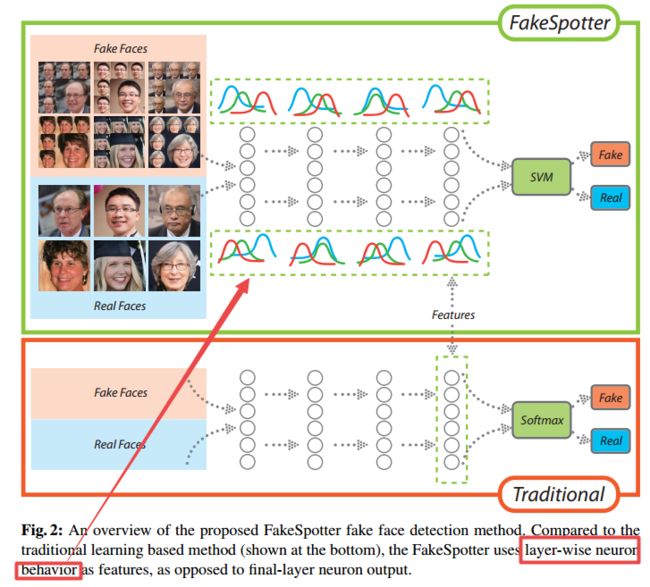
这篇文章页脚中有很多参考代码可以学习
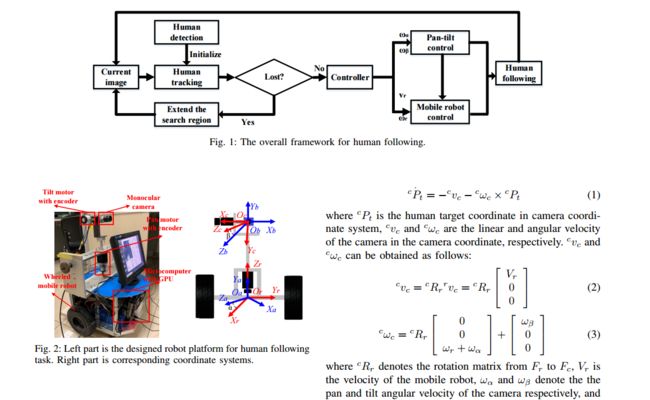
?有云台单目相机的跟随机器人, (from 中科院大学)
?FoodTracker实时食物检测的移动端实现, (from McGill University)

检测结果和营养分析:
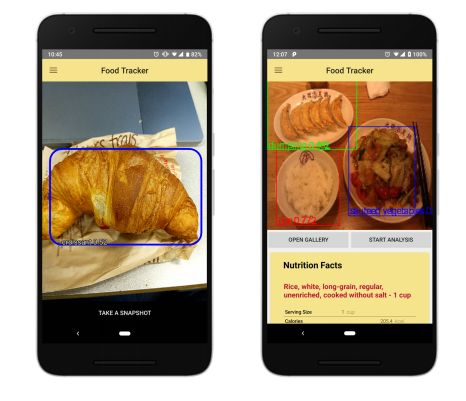

dataset:UECFood100 [11] and UECFood256 [12] benchmarks
?3D U2-Net基于三维Unet的多域医学图像分割方法,(from 浙大 鹏城实验室)

?异常图像检测,检测出背离整体分布的异常图像,(from 飞利浦研究 罗蒙索夫大学)

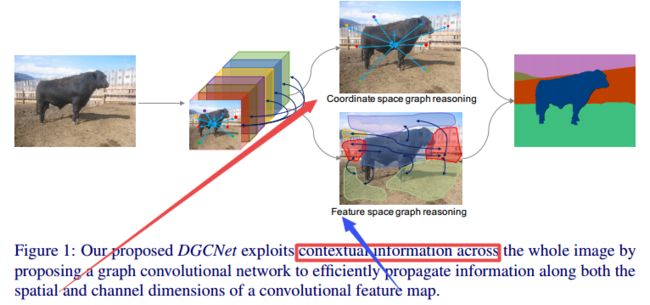
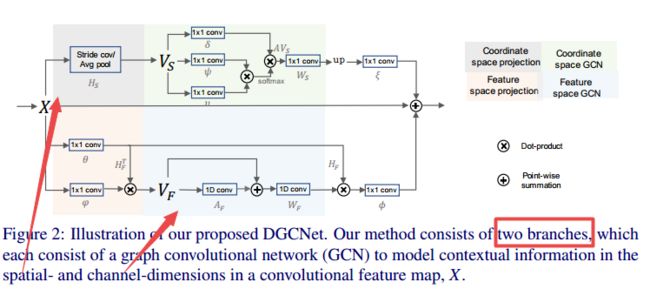
?基于双分支图网络的语义分割方法,(from 牛津 北大 深动科技)
同时基于空间特征和通道维度进行处理:
?基于在线多尺度卷积稀疏编码模型实现,并利用简化最大后验框架和ADMM算法求解得到视频去雨雪效果,(from 西安交大)

Daily Computer Vision Papers
| MRI Brain Tumor Segmentation using Random Forests and Fully Convolutional Networks Authors Mohammadreza Soltaninejad, Lei Zhang, Tryphon Lambrou, Guang Yang, Nigel Allinson, Xujiong Ye 在本文中,我们提出了一种新的基于学习的多模态MRI图像中脑肿瘤自动分割方法,该方法包含两组机器学习和手工制作的特征。完全卷积网络FCN形成机器学习功能,基于文本的功能被视为手工制作的功能。随机森林RF用于将MRI图像体素分类为正常脑组织和肿瘤的不同部分,即水肿,坏死和增强肿瘤。该方法在BRATS 2017挑战数据集上进行评估。结果表明,该方法提供了有希望的分割。对于整个肿瘤,核心和增强肿瘤,针对地面真相的自动脑肿瘤分割的平均骰子重叠测量值分别为0.86,0.78和0.66。 |
| Hierarchical Joint Scene Coordinate Classification and Regression for Visual Localization Authors Xiaotian Li, Jakob Verbeek, Juho Kannala 视觉本地化对计算机视觉和机器人技术中的许多应用至关重要。为了解决单图像RGB定位问题,现有技术的基于特征的方法通过在查询图像和预先构建的3D模型之间匹配局部描述符来解决任务。最近,已经利用深度神经网络来直接学习场景中的原始像素和3D坐标之间的映射,因此通过正向传递通过网络隐式地执行匹配。在这项工作中,我们提出了一种新的分层联合分类回归网络,以从单个RGB图像以粗略到精细的方式预测像素场景坐标。网络由一系列输出层组成,每个输出层都以先前输出的输出为条件,最终输出层对坐标进行回归,其他输出层产生粗略的位置标签。我们的实验表明,所提出的方法优于vanilla场景坐标回归网络,并且在大型环境中更具可扩展性。通过数据增强,它可以在三个基准数据集上实现最先进的单图像RGB定位性能。 |
| Recurrent Connectivity Aids Recognition of Partly Occluded Objects Authors Markus Roland Ernst, Jochen Triesch, Thomas Burwick 前馈卷积神经网络是核心对象识别的普遍模型。对于诸如闭塞等具有挑战性的条件,神经科学家认为视觉皮层中的反复连接有助于物体识别。在这项工作中,我们研究人工神经网络是否以及如何也可以从循环连接中受益。为此,我们系统地比较了由自下而上B,横向L和自上而下T连接组成的架构。为了评估性能,我们引入了两个新颖的立体遮挡对象数据集,它们弥合了从数字分类到识别3D对象的差距。该任务包括识别由多个遮挡物对象遮挡的一个目标对象。我们发现循环模型的性能明显优于前馈模型,后者在参数复杂度方面具有匹配性。我们表明,对于具有挑战性的刺激,循环反馈能够正确地修改网络的初始前馈猜测。总的来说,我们的结果表明,人工和生物神经网络都可以利用复发来改善对象识别。 |
| Brain-Like Object Recognition with High-Performing Shallow Recurrent ANNs Authors Jonas Kubilius, Martin Schrimpf, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott Roy, Kailyn Schmidt, Aran Nayebi, Daniel Bear, Daniel L. K. Yamins, James J. DiCarlo 深度卷积人工神经网络人工神经网络是灵长类腹侧溪流视觉处理机制的候选模型的领先类型。虽然最初受到大脑解剖学的启发,但在过去的几年中,这些人工神经网络已经从AlexNet中的简单八层架构演变为极其深入和分支的架构,展示了越来越好的对象分类性能,但却质疑它们仍然是大脑的样子。特别是,来自机器学习社区的典型深度模型通常难以映射到大脑的解剖结构上,因为它们具有大量的层和缺少生物学上重要的连接,例如复发。在这里,我们证明了更好的解剖学对齐大脑和机器学习的高性能以及神经科学测量不必相互矛盾。我们开发了CORnet S,一个浅层人工神经网络,具有四个解剖学映射区域和循环连接,由Brain Score指导,这是一种新的大规模神经和行为基准综合,用于量化灵长类动物腹侧视觉流模型的功能保真度。尽管比大多数模型要浅得多,但CORnet S是Brain Score的顶级模型,并且在ImageNet上的表现优于同样紧凑的模型。此外,我们对CORnet S电路变体的广泛分析表明,复发是Brain Score和ImageNet前1名表现的主要预测因素。最后,我们报告CORnet S IT神经群体的时间演变类似于实际的猴子IT群体动态。总之,这些结果建立了CORnet S,一种紧凑的,复现的ANN,作为灵长类腹侧视觉流的当前最佳模型。 |
| Video Rain/Snow Removal by Transformed Online Multiscale Convolutional Sparse Coding Authors Minghan Li, Xiangyong Cao, Qian Zhao, Lei Zhang, Chenqiang Gao, Deyu Meng 监控视频中的视频雨雪是计算机视觉社区的一项重要任务,因为视频中存在雨雪会严重降低许多监控系统的性能。已经广泛研究了各种方法,但是大多数方法仅在稳定的背景场景下考虑一致的雨雪。然而,从实际监控摄像机捕获的雨雪在时间上总是高度动态,偶尔会改变背景场景。针对这一问题,本文提出了一种新的雨雪清除方法,该方法充分考虑了雨雪和视频序列背景场景的动态统计。具体来说,雨雪被编码为在线多尺度卷积稀疏编码OMS CSC模型,不仅可以精确地传递真实雨雪的稀疏散射和多尺度形状,而且可以通过实时改善的参数很好地编码其时间动态配置。该模型。此外,对背景场景施加的变换算子被进一步嵌入到所提出的模型中,其精细地传达动态背景变换,例如旋转,缩放和失真,不可避免地存在于真实视频序列中。如此构造的方法自然可以更好地适应动态雨雪以及背景变化,并且还适合于处理归因于其在线学习模式的流视频。所提出的模型在简明的最大后MAP框架中制定,并且可以通过ADMM算法容易地求解。与现有技术的在线和离线视频雨雪清除方法相比,该方法在视觉和数量上均可在合成和真实视频数据集上实现更好的性能。具体来说,我们的方法可以以相对较高的效率实施,显示其实时视频雨雪清除的潜力。 |
| Dual Graph Convolutional Network for Semantic Segmentation Authors Li Zhang, Xiangtai Li, Anurag Arnab, Kuiyuan Yang, Yunhai Tong, Philip H.S. Torr 利用长距离上下文信息是像素明智的预测任务(例如语义分割)的关键。与之前使用多尺度特征融合或扩张卷积的工作相比,我们提出了一种新颖的图卷积网络GCN来解决这个问题。我们的双图卷演化网络DGCNet通过在单个框架中建模两个正交图来模拟输入特征的全局背景。第一个组件模拟图像中像素之间的空间关系,而第二个组件模拟沿网络特征图的通道维度的相互依赖性。这通过将特征投影到新的较低维度空间中来有效地完成,其中可以在重新投影到原始空间之前对所有成对交互进行建模。我们的简单方法比强基线提供了实质性的好处,并在Cityscapes 82.0平均IoU和Pascal Context 53.7平均IoU数据集上实现了最先进的结果。 |
| Weakly-Supervised 3D Pose Estimation from a Single Image using Multi-View Consistency Authors Guillaume Rochette, Chris Russell, Richard Bowden 我们提出了一种新颖的数据驱动正则化器,用于3D人体姿态估计的弱监督学习,消除了影响现有方法的漂移问题。我们通过将立体声重建问题转移到网络本身的损失中来实现这一点。这避免了在训练之前重建3D数据的需要,并且与先前的半监督方法不同,避免了对监督训练的预热期的需要。我们的方法的概念和实现简单性是其吸引力的基础。通过我们额外的基于投影的损失,不仅可以直接增加许多弱监督方法,而且很明显它如何塑造重建并防止漂移。因此,我们相信它将成为任何研究弱监督3D重建的研究人员的宝贵工具。对可用的最大的多摄像机和无标记数据集Panoptic进行评估,我们获得的精度基本上与在训练中充分利用3D groundtruth的强监督方法无法区分。 |
| A Collaborative Approach using Ridge-Valley Minutiae for More Accurate Contactless Fingerprint Identification Authors Ritesh Vyas, Ajay Kumar 非接触式指纹识别已成为各种电子商务和执法应用中个人识别的可靠且用户友好的替代方案。然而,从文献中已经知道,与从基于接触的指纹传感器获得的那些相比,非接触式指纹图像提供非常低的匹配精度。本文开发了一种新方法,可显着改善目前可用的非接触式指纹匹配功能。我们系统地分析了补充岭谷信息的范围,并引入了新方法,以实现与目前常用的现有指纹匹配器相比更高的匹配精度。我们还研究了最少探索的指纹颜色空间转换选项,这些选项可以在更准确的非接触式指纹匹配中发挥关键作用。本文介绍了使用NBIS,MCC和COTS匹配器的不同公开的非接触式指纹数据库的实验结果。我们始终如一的优异成绩验证了所提方法对更准确的非接触式指纹识别的有效性。 |
| BPnP: Further Empowering End-to-End Learning with Back-Propagatable Geometric Optimization Authors Bo Chen, Tat Jun Chin, Nan Li 在本文中,我们提出了BPnP,一种通过PnP求解器进行反向传播的新方法。我们证明了这种几何优化过程的梯度可以使用隐式函数定理来计算,就好像它是可微分的一样。此外,我们开发了一个残差整合技巧,使用BPnP平滑稳定地进行端到端姿态回归。我们还提出了一种成形算法,该算法成功地使用BPnP进行关键点回归。 |
| DARTS+: Improved Differentiable Architecture Search with Early Stopping Authors Hanwen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, Weiran Huang, Kechen Zhuang, Zhenguo Li 最近,对自动化神经架构设计过程的兴趣越来越大,而可分辨架构搜索DARTS方法使该过程在几天内就可用了。特别地,引入了称为一次性模型的超网络,通过该网络可以用梯度下降连续搜索该体系结构。然而,当搜索时期的数量变大时,经常观察到DARTS的性能崩溃。同时,在选定的体系结构中可以找到许多跳过连接。在本文中,我们声称崩溃的原因是在DARTS的双层优化中存在合作和竞争,其中架构参数和模型权重交替更新。因此,我们提出了一种简单有效的算法,名为DARTS,通过在满足某个标准时提前停止搜索过程来避免崩溃并改善原始DARTS。我们证明了提出的早期停止标准在避免崩溃问题方面是有效的。我们还对基准数据集进行了实验,并展示了我们的DARTS算法的有效性,其中DARTS在CIFAR10上达到2.32测试误差,在CIFAR100上达到14.87,在ImageNet上达到23.7。我们进一步指出,通过手动设置少量搜索时期,隐含地将早期停止的想法包括在一些现有的DARTS变体中,同时我们给出了早期停止的明确标准。 |
| Part-Guided Attention Learning for Vehicle Re-Identification Authors Xinyu Zhang, Rufeng Zhang, Jiewei Cao, Dong Gong, Mingyu You, Chunhua Shen 车辆识别Re ID通常需要人们识别车辆之间的细粒度视觉差异。除了容易受到视点变化和变形影响的车辆的整体外观之外,车辆部件还提供了区分近似相同车辆的关键线索。在这些观察的启发下,我们引入了一个部分引导注意网络PGAN来精确定位突出的部分区域,并有效地将全局和部分信息结合起来用于判别性特征学习。 PGAN首先检测不同部件组件和显着区域的位置,而不管车辆身份如何,其作为自下而上的关注来缩小可能的搜索区域。为了估计检测到的部分的重要性,我们提出了一个部分注意模块PAM,以自适应地定位具有高注意力权重的最具辨别力的区域,并抑制具有相对较低权重的不相关部分的分心。 PAM由Re ID损失引导,因此提供自上而下的关注,使得能够在汽车部件和其他显着区域的水平上计算注意力。最后,我们汇总了全局外观和部件功能,以进一步提高功能性能。 PGAN在端到端框架中结合了部分引导的自下而上和自上而下的关注,全局和部分视觉特征。大量实验表明,所提出的方法在四个大规模基准数据集上实现了新的现有技术车辆Re ID性能。 |
| Towards Generalizable Forgery Detection with Locality-aware AutoEncoder Authors Mengnan Du, Shiva Pentyala, Yuening Li, Xia Hu 随着深度学习技术的进步,现在可以生成超逼真的假图像和视频。这些被操纵的伪造品可能会吸引大量观众,并对我们的社会产生不利影响。尽管已经花费了大量精力来检测伪造品,但是它们的性能在以前看不见但相关的操作上显着下降,并且检测泛化能力仍然是个问题。为了弥补这一差距,在本文中,我们提出了Locality aware AutoEncoder LAE,它结合了细粒度表示学习和在统一框架中强制执行局部性。在训练过程中,我们使用像素智能掩模来规范LAE的局部解释,以强制模型学习伪造区域的内在表示,而不是捕获训练集中的伪像并学习伪相关以执行检测。我们进一步提出了一个积极的学习框架,以选择具有挑战性的候选人进行标记,以减少注释工作以规范解释。实验结果表明,LAE确实可以专注于伪造区域做出决策。结果进一步表明,与通过替代操作方法产生的伪造品的现有技术相比,LAE实现了优异的泛化性能。 |
| Rethinking Zero-Shot Learning: A Conditional Visual Classification Perspective Authors Kai Li, Martin Renqiang Min, Yun Fu 零镜头学习ZSL旨在仅基于类的语义描述来识别看不见的类的实例。现有算法通常通过学习从一个特征空间到另一个特征空间的映射来将其表示为语义视觉对应问题。尽管是合理的,但先前的方法基本上以隐式方式丢弃了视觉特征的高度珍贵的辨别能力,因此产生了不期望的结果。我们将ZSL重新表述为条件视觉分类问题,即,基于从语义描述中学习的分类器对视觉特征进行分类。通过这种重新设计,我们开发了针对各种ZSL设置的算法对于传统设置,我们建议训练一个深度神经网络,通过基于情节的训练方案从语义属性直接生成视觉特征分类器。对于广义设置,我们将高度学习连接起来。用于所见类的判别分类器和用于看不见类的生成分类器以对所有类的视觉特征进行分类对于转换设置,我们利用未标记的数据来有效地校准分类器生成器,使用新颖的学习而不忘记自我训练机制并通过鲁棒性指导过程广义交叉熵损失。大量实验表明,在所有ZSL设置中,我们提出的算法在大多数基准数据集上的显着优势明显优于现有技术。 |
| FoodTracker: A Real-time Food Detection Mobile Application byDeep Convolutional Neural Networks Authors Jianing Sun, Katarzyna Radecka, Zeljko Zilic 我们提供了一种移动应用程序,用于实时识别单个图像中的多对象食物的食物项目,然后返回具有组分和近似量的营养成分。我们的工作分为两部分。首先,我们构建了一个深度卷积神经网络,与最先进的检测策略YOLO融合,实现了近80个平均精度的同时多目标识别和定位。其次,我们将我们的模型调整为具有扩展营养分析功能的移动应用程序。在app侧推断和解码模型输出后,我们在实时或本地模式下呈现包括边界框位置和类标签的检测结果。我们的模型非常适合移动设备,具有可忽略的推理时间和较小的内存要求,并具有深度学习算法。 |
| Content-Aware Unsupervised Deep Homography Estimation Authors Jirong Zhang, Chuan Wang, Shuaicheng Liu, Lanpeng Jia, Jue Wang, Ji Zhou 两幅图像之间的鲁棒单应性估计是一项基本任务,已广泛应用于各种视觉应用。传统的基于特征的方法通常根据匹配的特征检测图像特征并根据RANSAC异常值去除拟合单应性。然而,单应性的质量很大程度上依赖于图像特征的质量,其在低光和低纹理图像方面易于出错。另一方面,先前的深度单应性方法要么合成用于监督学习的图像,要么采用用于无监督学习的空间图像,两者都忽略了在单应性估计中深度差异的重要性。此外,它们同等地处理图像内容,包括动态对象和近距离前景的区域,这进一步降低了估计的质量。在这项工作中,为了克服这些问题,我们提出了一种采用新架构设计的无监督深度单应法。我们在估计过程中学习掩模以拒绝异常区域。此外,我们计算了我们学到的深层特征的损失,而不是像以前那样直接比较图像内容。此外,还提供了一个综合数据集,涵盖了常规和具有挑战性的案例,例如质地差和非平面干扰。通过与基于特征和以前的深度方法的比较来验证我们的方法的有效性。代码即将在Github上发布。 |
| Unsupervised Image Regression for Heterogeneous Change Detection Authors Luigi T. Luppino, Filippo M. Bianchi, Gabriele Moser, Stian N. Anfinsen 异构多时相卫星图像中的变化检测是遥感中一个新兴且具有挑战性的主题。特别是,主要挑战之一是以无人监督的方式解决问题。在本文中,我们提出了一种基于亲和矩阵和图像回归比较的双时态异构变化检测的无监督框架。首先,我们的方法量化了从两个图像中的共同定位的图像块计算的亲和度矩阵的相似性。这样做是为了自动识别可能未改变的像素。将识别的像素作为伪训练数据,我们学习转换以将第一图像映射到另一图像的域,反之亦然。选择四种回归方法进行变换高斯过程回归,支持向量回归,随机森林回归,以及最近提出的称为均匀像素变换的核回归方法。为了评估我们框架的潜力和局限性,以及每种回归方法的优缺点,我们对两个真实数据集进行了实验。结果表明,亲和度矩阵的比较本身已经可以被认为是变化检测方法。然而,显示图像回归以改善单独前一步骤获得的结果,并产生准确的变化检测图,尽管多时间输入数据具有异质性。值得注意的是,随机森林回归方法通过实现与其他方法类似的精确度而优异,但具有显着更低的计算成本并且具有快速且稳健的超参数调整。 |
| Transferable Adversarial Robustness using Adversarially Trained Autoencoders Authors Pratik Vaishnavi, Kevin Eykholt, Atul Prakash, Amir Rahmati 事实证明,机器学习是解决许多应用领域中复杂问题的极其有用的工具。这种流行使其成为恶意行为者的有吸引力的目标。对抗性机器学习是一个充分研究的研究领域,其中对手试图通过仔细操纵输入来在机器学习算法中引起可预测的错误。作为回应,已经提出了许多技术来加强机器学习算法并减轻对抗性攻击的影响。在这些技术中,对抗性训练增强了对抗性输入的训练数据,已被证明是一种有效的防御技术。然而,对抗性训练在计算上是昂贵的,并且对抗性能的改进仅限于单个模型。在本文中,我们提出了对抗训练的自动编码器增强,这是第一个对某些自适应对手具有鲁棒性的可转移对抗防御。我们通过对分类损失进行对等训练自动编码器,从分类管道中解除对抗鲁棒性。我们表明,我们的方法可以获得与MNIST,Fashion MNIST和CIFAR 10数据集上最先进的对抗训练模型相媲美的结果。此外,我们可以将我们的方法转移到其他易受攻击的模型,并在没有额外培训的情况下提高其对抗性能。最后,我们将防御与集合方法相结合,并将对抗性训练与多个易受攻击的预训练模型并行化。在单一的对抗训练课程中,自动编码器可以在易受攻击的模型上实现与标准对抗训练相当或更好的对抗性能。 |
| Efficient 2.5D Hand Pose Estimation via Auxiliary Multi-Task Training for Embedded Devices Authors Prajwal Chidananda, Ayan Sinha, Adithya Rao, Douglas Lee, Andrew Rabinovich Magic Leap, Inc 2D关键点估计是人体和手部三维姿态估计问题的重要前提。在这项工作中,我们讨论了在具有高度约束的存储器和计算包络的嵌入式设备上部署极其高效的2.5D手姿态估计所需的数据,体系结构和训练过程,例如AR VR可穿戴设备。我们的2.5D手部姿势估计包括由自我中心图像上的关节位置的2D关键点估计,由深度传感器捕获,并且使用相应的深度值提升到2.5D。我们的贡献是两倍我们讨论数据标记和增强策略,网络架构中的模块与现有技术的MobileNetV2架构相比,共同导致3个翻牌计数和2个参数数量。 b我们提出了一种辅助多任务培训策略,以补偿网络的小容量,同时实现与MobileNetV2相当的性能。我们的32位训练模型的存储器占用空间小于300千字节,工作频率超过50赫兹,小于35 MFLOP。 |
| Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification Authors Tzu Ming Harry Hsu, Hang Qi, Matthew Brown 联合学习使视觉模型能够使用来自移动设备的真实世界数据以隐私保护方式进行培训。鉴于其分布式特性,这些设备上的数据统计数据可能会有很大差异。在这项工作中,我们通过联邦学习来研究这种非相同数据分布对视觉分类的影响。我们提出了一种合成具有连续相同范围的数据集的方法,并为联合平均算法提供性能测量。我们表明,随着分布的不同,性能会下降,并通过服务器动力提出缓解策略。 CIFAR 10上的实验表明,在一系列不相同的情况下,分类性能得到了改善,在最偏斜的环境中分类精度从30.1提高到76.9。 |
| Automatic Hip Fracture Identification and Functional Subclassification with Deep Learning Authors Justin D Krogue, Kaiyang V Cheng, Kevin M Hwang, Paul Toogood, Eric G Meinberg, Erik J Geiger, Musa Zaid, Kevin C McGill, Rina Patel, Jae Ho Sohn, Alexandra Wright, Bryan F Darger, Kevin A Padrez, Eugene Ozhinsky, Sharmila Majumdar, Valentina Pedoia 目的髋部骨折是发病率和死亡率的常见原因。使用深度学习自动识别和分类髋部骨折可以通过减少诊断错误和减少手术时间来改善结果。方法回顾1118项研究中的髋关节和骨盆X线片,并通过边界框标记3034髋,分类为正常,移位股骨颈骨折,非移位股骨颈骨折,股骨转子间骨折,既往ORIF或既往关节成形术。训练基于深度学习的对象检测模型以自动化边界框的放置。密集连接的卷积神经网络DenseNet在边界框图像的一个子集上进行训练,并在一个保持的测试集上评估其性能,并通过比较100个图像子集与两组人类观察者的团队训练放射科医师和矫形外科医生,以及高级急诊医学,放射学和整形外科的居民。结果我们模型的骨折二元精度为93.8 95 CI,91.3 95.8,灵敏度为92.7 95 CI,88.7 95.6,特异性95.0 95 CI,91.5 97.3。多类别分类准确度为90.4 95 CI,87.4 92.9。与人类观察者相比,我们的模型在所有条件下至少达到了专家级别的分类。此外,当该模型被用作辅助时,人类表现得到改善,辅助居民表现接近于独立的团契培训专家表现。结论我们的深度学习模型以至少专家水平的准确度识别和分类髋部骨折,并且当用作辅助改善人类表现时,辅助居民表现接近于无辅助团体训练的参加者。 |
| Flow Models for Arbitrary Conditional Likelihoods Authors Yang Li, Shoaib Akbar, Junier B. Oliva 了解数据集特征之间的依赖关系是大多数无监督学习任务的核心。然而,大多数生成建模方法仅关注联合分布p x并利用模型,其中在给定其余观察到的协变量x o p x u mid x o的情况下获得某些特征子集的条件分布是难以处理的。传统的条件方法为一组固定的协变量提供了一个模型,该协变量以另一组固定的观察到的协变量为条件。相反,在这项工作中,我们开发了一个模型,该模型能够通过易处理的条件可能性产生所有条件分布p x u mid x o,用于任意x u。我们提出了基于流动生成模型的变量变化的新颖扩展,任意条件流模型AC Flow,其可以以观察到的协变量的任意子集为条件,这是先前不可行的。我们将AC Flow应用于特征的插补,并通过引入辅助目标来开发用于多重和单个插补的统一平台,该辅助目标为流动模型提供原则性的单一最佳猜测。大量的实证评估表明,我们的模型在合成和现实世界数据集中的图像修复和特征插补中实现了单一和多重插补的最先进性能。代码可在 |
| White-Box Adversarial Defense via Self-Supervised Data Estimation Authors Zudi Lin, Hanspeter Pfister, Ziming Zhang 在本文中,我们研究了如何防御分类器以防止使用巧妙修改的输入数据欺骗分类器的对抗性攻击的问题。与之前的作品相比,这里我们专注于白盒对抗防御,攻击者不仅可以完全访问分类器,还可以获得尽可能强大攻击的防御者。在这样的上下文中,我们建议将防御者视为功能性的,更高阶的函数,其以函数作为其参数来表示函数空间,而不是常规的固定函数。从这个角度来看,应该针对每个对抗性输入单独实现和优化防御者。为此,我们提出了RIDE,一种有效且可证明收敛的自监督学习算法,用于个人数据估计,以保护预测免受敌对攻击。我们展示了图像识别中对抗性防御性能的显着改善,例如分别在现有BPDA攻击者下的MNIST,CIFAR 10和ImageNet数据集上的98,76,43测试精度。 |
| A superpixel-driven deep learning approach for the analysis of dermatological wounds Authors Gustavo Blanco, Agma J. M. Traina, Caetano Traina Jr., Paulo M. Azevedo Marques, Ana E. S. Jorge, Daniel de Oliveira, Marcos V. N. Bedo 背景。基于图像的皮肤病伤口内不同组织的识别增强了患者的护理,因为它不需要侵入性评估。本手稿提出了一种名为QTDU的方法,该方法将深度学习模型与超像素驱动的分割方法相结合,用于评估皮肤溃疡组织的质量。 |
| FakeSpotter: A Simple Baseline for Spotting AI-Synthesized Fake Faces Authors Run Wang, Lei Ma, Felix Juefei Xu, Xiaofei Xie, Jian Wang, Yang Liu 近年来,我们目睹了生成对抗网络GAN及其在图像合成中的变体的空前成功。这些技术被广泛用于合成虚假面孔,这对现有的面部识别FR系统构成严重挑战,并且随着假货传播和加剧错误信息而给社交网络和媒体带来潜在的安全威胁。不幸的是,这些AI合成假面的强大探测器仍处于起步阶段,尚未准备好完全应对这一新兴挑战。目前,基于图像取证和基于学习的方法是检测假面孔的两大类策略。在这项工作中,我们提出了一种基于监测神经元行为的替代方法。对神经元覆盖和相互作用的研究已经成功地证明它们可以作为深度学习系统的测试标准,特别是在暴露于对抗性攻击的环境下。在这里,我们推测监测神经元行为也可以作为检测假脸的资产,因为逐层神经元激活模式可以捕获对假检测器很重要的更微妙的特征。根据经验,我们已经证明,基于神经元覆盖行为的拟议FakeSpotter与简单的线性分类器相结合,可以大大优于经过深度训练的卷积神经网络CNN,用于发现AI合成假面。在三个深度学习基于DL的FR系统上进行了大量实验,其中两个GAN变体用于合成假面,并且在两个公共高分辨率面部数据集上进行了大量实验,证明了FakeSpotter作为一个简单但强大的假人脸检测基线的潜力。狂野的。 |
| Human Following for Wheeled Robot with Monocular Pan-tilt Camera Authors Zheng Zhu, Hongxuan Ma, Wei Zou 由于其在实际应用中的潜力,人类对移动机器人的追随已经见证了显着的进步。目前,大多数人类跟随系统配备有深度传感器以获得人和机器人之间的距离信息,其受到感知要求和噪声的影响。在本文中,我们设计了一种带有单眼云台摄像机的轮式移动机器人系统,可以跟随人类,它可以在视野中保持目标并同时保持跟随。该系统由快速人体探测器,实时准确的视觉跟踪器,移动机器人和云台摄像机统一控制器组成。在视觉跟踪算法中,利用连体网络和光流信息同时定位和回归人类。为了使用单目相机执行以下操作,引入人体高度的约束来设计控制器。在实验中,人类跟踪在模拟和真实的机器人平台中进行和分析,这证明了整个系统的有效性和稳健性。 |
| 3D U$^2$-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation Authors Chao Huang, Hu Han, Qingsong Yao, Shankuan Zhu, S. Kevin Zhou 像U Net这样的完全卷积神经网络一直是医学图像分割中最先进的方法。实际上,网络是高度专业化的,并且针对每个分段任务单独训练。代替多个模型的集合,非常希望学习用于不同任务的通用数据表示,理想地是单个模型,其中添加了针对每个任务的最少数量的参数。受近期图像分类多领域学习成功的启发,我们首次探索了一种处理多种医学分割任务的有前途的通用架构,并且可以扩展到新任务,无论不同的器官和成像方式如何。我们的3D通用U Net 3D U 2网络基于可分离卷积,假设来自不同域的图像具有特定于域的空间相关性,可以通过信道方式卷积进行探测,同时还共享可以通过逐点卷积建模的交叉信道相关性。我们在五个器官分割数据集上评估3D U 2网络。实验结果表明,该通用网络能够在分割精度方面与传统模型竞争,而只需要大约1个参数。此外,我们观察到该体系结构可以轻松有效地适应新域,而不会牺牲用于学习通用网络共享参数化的域中的性能。我们将3D U 2 Net的代码放入公共领域。网址 |
| Multiple Partitions Aligned Clustering Authors Zhao Kang, Zipeng Guo, Shudong Huang, Siying Wang, Wenyu Chen, Yuanzhang Su, Zenglin Xu 多视图聚类是一项重要但具有挑战性的任务,因为难以集成来自多个表示的信息。大多数现有的多视图聚类方法探索数据点所在空间中的异构信息。由于不可避免的噪音或观点之间的不一致,这种常见做法可能导致重大信息丢失。由于不同的视图允许相同的集群结构,因此自然空间应该是所有分区。与现有技术正交,在本文中,我们建议通过融合分区来利用多视图信息。具体而言,我们通过不同的旋转矩阵对齐每个分区以形成一致的聚类指示符矩阵。此外,为每个视图分配权重以考虑视图的聚类容量差异。最后,在统一框架中共同学习基本分区,权重和一致性聚类。我们证明了我们的方法在几个真实数据集上的有效性,其中发现了相对于其他最先进的多视图聚类方法的显着改进。 |
| Center-Extraction-Based Three Dimensional Nuclei Instance Segmentation of Fluorescence Microscopy Images Authors David Joon Ho, Shuo Han, Chichen Fu, Paul Salama, Kenneth W. Dunn, Edward J. Delp 荧光显微镜是分析组织中3D亚细胞结构的重要工具。表征组织的重要步骤涉及细胞核分割。在本文中,描述了使用卷积神经网络CNN分割核的两阶段方法。特别地,由于3D数据集的大小和复杂性,手动创建用于训练目的的标记体积是不实际的,因此本文描述了一种基于空间受限的循环一致性对抗网络生成合成显微镜体积的方法。所提出的方法在多个真实的显微镜数据集上进行测试,并且优于其他常用的分割技术。 |
| SegNAS3D: Network Architecture Search with Derivative-Free Global Optimization for 3D Image Segmentation Authors Ken C. L. Wong, Mehdi Moradi 深度学习大大减少了对图像分割中手动特征选择的需求。然而,网络架构优化和超参数调整大多是手动和耗时的。尽管在计算机视觉中对网络体系结构搜索的研究越来越多,但大多数工作集中在图像分类而非分割,并且在医学图像分割方面的努力非常有限,特别是在3D中。为了解决这个问题,我们在此提出了一个框架SegNAS3D,用于三维图像分割的网络架构搜索。在该框架中,网络体系结构包括互连的构建块,其由诸如卷积和跳过连接的操作组成。通过将块结构表示为可学习的有向非循环图,可以通过衍生自由全局优化一起学习诸如特征通道的数量和使用深度监督的选项之类的超参数。对具有19个结构的43个3D脑磁共振图像的实验实现了平均Dice系数为82。每个架构搜索在三个GPU上需要不到三天的时间,并且生成的架构比手动创建的架构要小得多。 |
| Encoding High-Level Visual Attributes in Capsules for Explainable Medical Diagnoses Authors Rodney LaLonde, Drew Torigian, Ulas Bagci 由于难以解释决策,深度神经网络通常被称为黑盒子。这是机器学习更深层次趋势的特征,其中预测性能通常以可解释性为代价。在某些领域,例如基于图像的诊断任务,了解机器生成预测背后的原因对于评估信任至关重要。在这项研究中,我们介绍了胶囊网络的新颖设计,以提供可解释的诊断。我们提出的深度可解释的胶囊结构称为DX Caps,可以在胶囊载体内编码高水平的视觉属性,以便同时产生肺癌的恶性预测以及放射科医师用于解释其预测的六种视觉可解释属性的近似值。为了减少这个更深层网络的参数和内存负担,我们引入了一个新的胶囊平均池功能。通过这种简单但基本的补充,胶囊网络可以以比以前更深的方式设计。我们的整体方法可以表征为多任务学习,我们学习在我们独特构建的深层胶囊网络的载体内近似肺结节的六个高级视觉属性,同时分割结节并预测其恶性潜在诊断。通过1000多次CT扫描测试,我们的实验结果表明,我们提出的算法可以近似于肺结节的视觉属性远远好于深度多路径密集3D CNN。当首次应用于此任务时,所提出的网络也比基线可解释的胶囊网络X Caps和CapsNet实现更高的诊断准确度。据我们所知,这是第一个研究胶囊网络进行视觉属性预测的研究,特别是可解释的医学图像诊断。 |
| A method for Cloud Mapping in the Field of View of the Infra-Red Camera during the EUSO-SPB1 flight Authors Alessandro Bruno, Anna Anzalone, Carlo Vigorito for the JEM EUSO collaboration EUSO SPB1于2017年4月24日在新西兰瓦纳卡的美国宇航局气球发射场发布,于5月7日降落在南太平洋。分析由气球上的仪器收集的数据以搜索UHECR超高能宇宙射线空气淋浴的UV脉冲特征。夜间云的存在会影响UHECR的间接测量,因此了解探测器观测期间的气象条件至关重要。在飞行过程中,机上EUSO SPB1 UCIRC摄像机芝加哥大学红外线摄像机获取了紫外望远镜视野中的图像。可用的夜间和白天图像包括在两个红外波段中观察到的大气气象条件的信息。已经研究了云的存在,采用了一种方法,该方法被开发用于为每个可用的红外图像提供密集的云度图。最终的掩模用于在IR相机像素分辨率下给出像素云量信息,该分辨率几乎是UV相机的4倍。在这项工作中,通过使用基于不同低级图像特征分析的专家系统获得云度图。此外,需要应用图像增强步骤作为处理未校准数据的预处理步骤。 |
| Perceptual Image Anomaly Detection Authors Nina Tuluptceva, Bart Bakker, Irina Fedulova, Anton Konushin 我们提出了一种新的图像异常检测方法,其中使用从正常数据的某些分布中抽取的样本的算法旨在检测分布异常样本。我们的方法包括编码器和发生器的组合,用于将图像分布映射到预定义的潜在分布,反之亦然。它利用Generative Adversarial Networks来学习这些数据分布,并使用感知损失来检测图像异常。为了实现这一目标,我们引入了一种新的相似性度量,它表达了图像之间的感知相似性,并且对图像对比度的变化具有鲁棒性。其次,我们介绍了一种新方法,用于在没有用于超参数调整的验证数据集的情况下选择多目标损失函数图像重建和分布映射的权重。在训练之后,我们的模型测量输入图像的异常,作为它与建模数据分布的最近生成图像之间的感知差异。所提出的方法在几个公开可用的图像基准上进行了广泛的评估,并实现了最先进的性能。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

膜拜一下巅峰算力:) 百P算力 1024*Ascend910(*32 Da Vinci AI core) pic from huaweis.com