【今日CV 计算机视觉论文速览 第103期】Mon, 22 Apr 2019
今日CS.CV 计算机视觉论文速览
Mon, 22 Apr 2019
Totally 38 papers
?上期速览✈更多精彩请移步主页

Interesting:
?Fashion++, 如何通过微小的改变改进时尚程度?研究人员提出了在与学习的编码下合成时尚元素,给出时尚修饰建议。(from UT Austin )

首先通过两个编码器得到了纹理质地和外形的隐含空间编码,随后利用F++对上述特征进行编辑生成t++和s++特征,s++特征将生成二维分割mask,并与修改后的纹理特征t++更新m++得到了新的特征图u++,最后利用Gt生成最终的修改后的时尚着装x++。
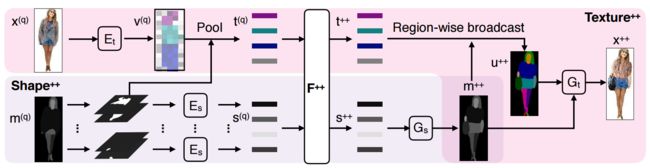
其中基于VAE的形状生成:
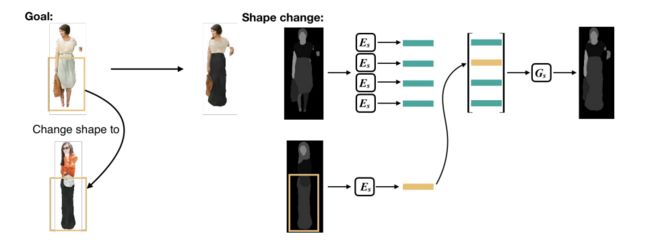
训练样本生成和编辑的变化:
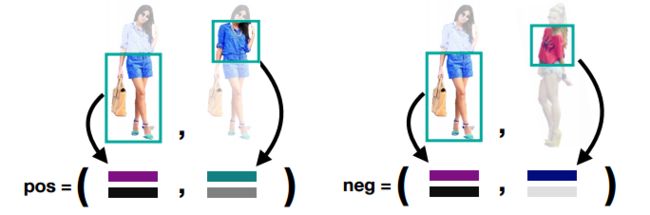
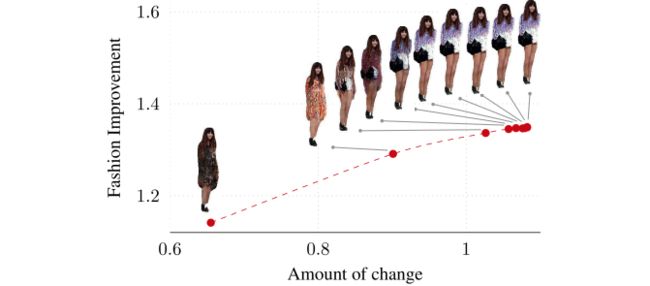
一些不同因素的影响和结果:

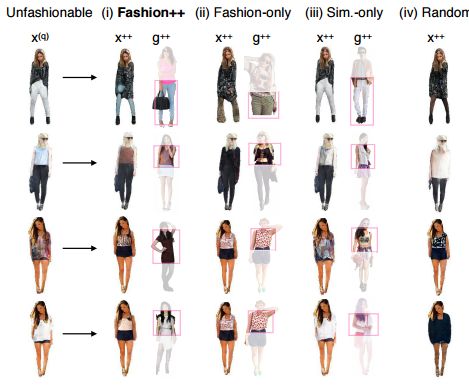
dataset:Chictopia dataset
project: http://vision.cs.utexas.edu/projects/FashionPlus/
?深度神经决策树(NDF)决策过程的可视化, 研究跟踪了决策过程、并对显著性图进行可视化以了解分类和回归问题中最重要的影响因素。(from 香港科技)

code:https://github.com/Nicholasli1995/VisualizingNDF
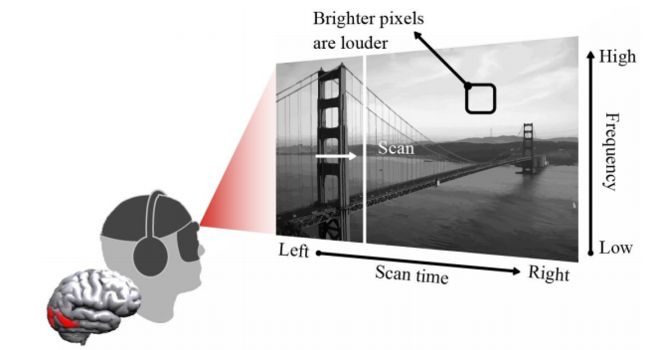
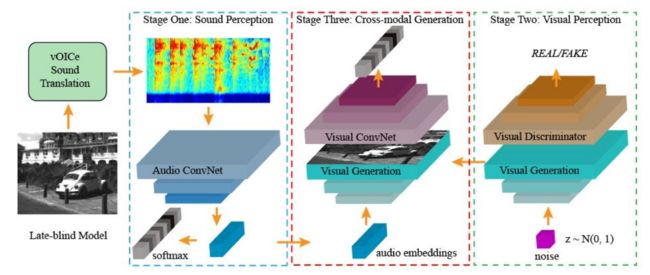
?Listen to the Image, 通过将视觉转换为声音帮助盲人感知周遭世界。(from OPTIMAL)
模型通过三层感知模型构建声音嵌入、视觉知识学习和交叉模态生成。
ref:http://www.seeingwithsound.com/
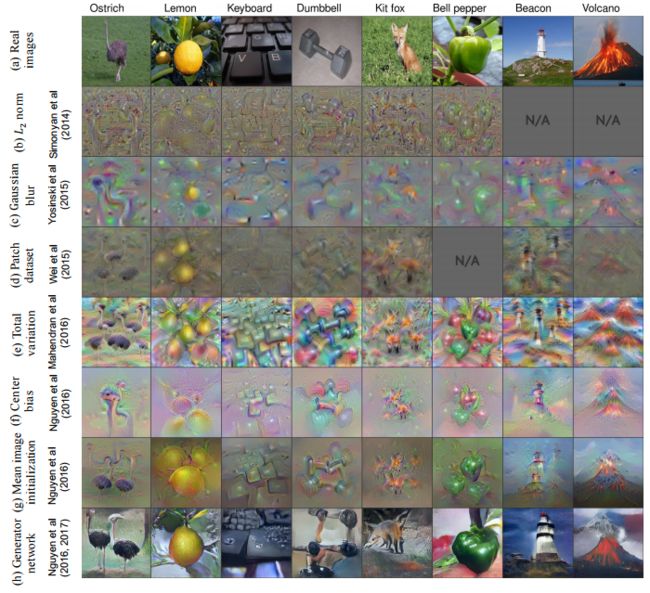
?神经网络特征可视化综述, (from 奥本大学 Uber )


?基于特征前传的图像去雾, (from MIT Lincoln Laboratory)
左侧为FastNet模型将特征直接传入金字塔来精炼。右侧为DualFastNet,同时估计了大气光(散射)模型和投射模型。
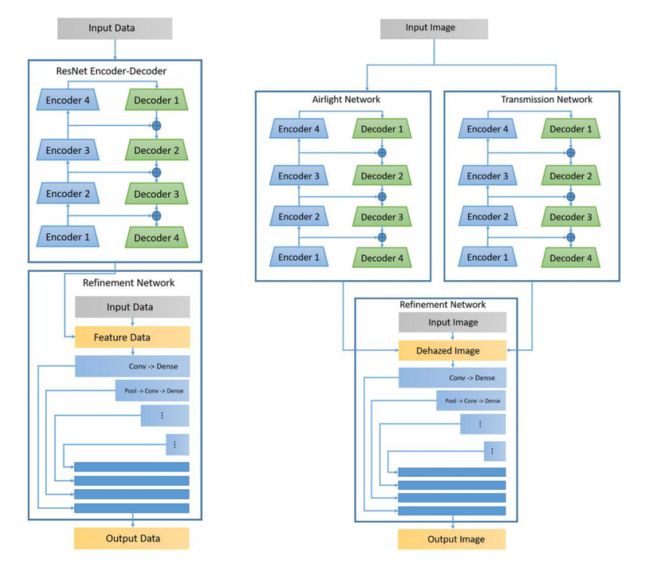

ref:https://github.com/hezhangsprinter/DCPDN
dataset:2019 NTIRE Image Dehazing Challenge
O-HAZE, I-HAZE, and DenseHaze datasets
?XLSor胸片肺部分割方法,利用了交叉注意力模块,并实现了异常放射数据的生成数据增强。 (from National Institutes of Health Clinical Center US,平安保险)
·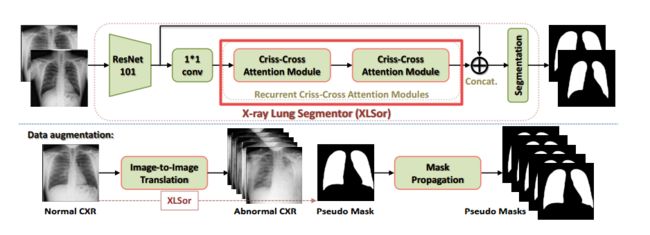
code:https://github.com/rsummers11/CADLab/tree/master/Lung_Segmentation_XLSor
dataset:NIH Chest X-ray dataset
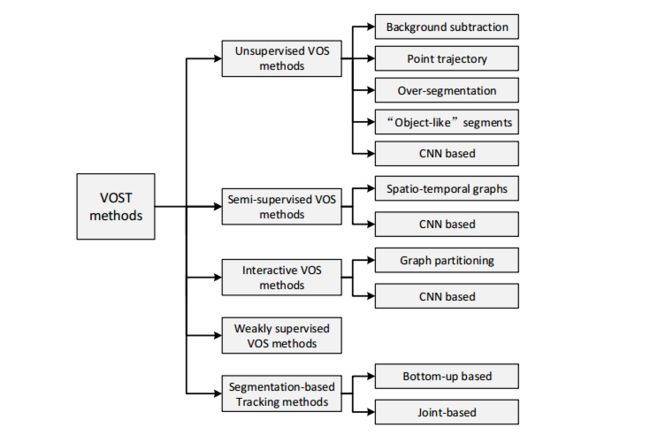
?**视频目标检测与跟踪综述,作为计算机视觉领域的复杂问题,同样需要面临遮挡、变形、运动模糊和尺度变化等影响。分割还需要解决均匀目标、重叠目标、边缘模糊和清晰度复杂性、而追踪则需要处理快速移动、脱离视野和实时处理的要求。video object segmentation and tracking (VOST)将这两个问题结合起来克服了先前方法的困难。这篇文章将综述先进的VOST方法,并对现有方法进行分类,识别出未来的趋势的研究方法。(from 矿大 南洋理工)
现有方法的分类:
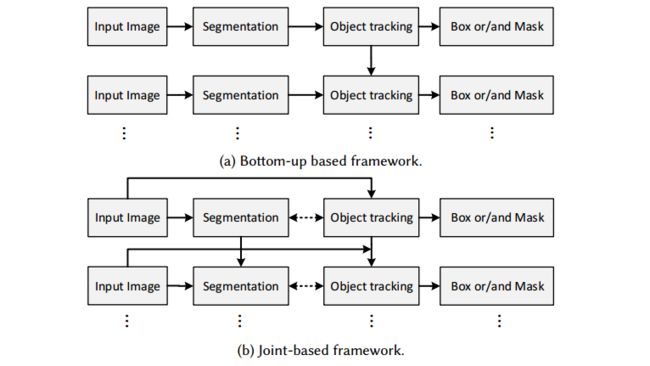
基于分割的追踪方法:
?**物体显著性检测Salient Object Detection的综述, 主要侧重于最近5年基于深度学习的SOD方法。(from 人工智能感知研究院阿联酋 香港中文)
SOD的发展历程:
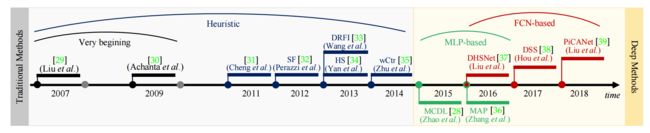
先前SOD领域的综述及侧重点:
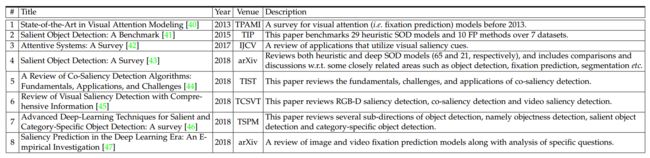
近年来基于深度学习方法的模型、架构和数据集:
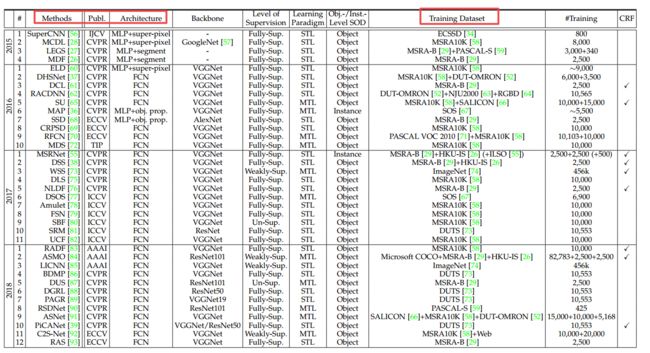
模型架构的细节:
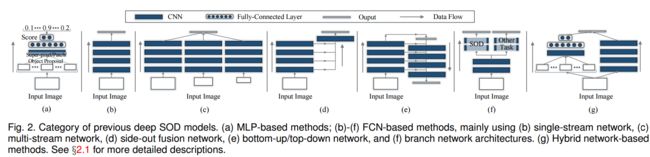
IIAI:http://www.inceptioniai.org/
github:https://github.com/wenguanwang/SODsurvey
dataset:
1. http://www.wisdom.weizmann.ac.il/∼vision/Seg_Evaluation_DB/dl.html
2. https://ivrlwww.epfl.ch/supplementary_material/RK_CVPR09/
3. http://elderlab.yorku.ca/SOD/
4. https://mmcheng.net/zh/msra10k/
5. http://www.cse.cuhk.edu.hk/leojia/projects/hsaliency
6. http://saliencydetection.net/dut-omron/
7. http://cbi.gatech.edu/salobj/
8. https://i.cs.hku.hk/∼gbli/deep_saliency.html
9. http://saliencydetection.net/duts/
10. http://cs-people.bu.edu/jmzhang/sos.html
11. http://cs-people.bu.edu/jmzhang/sos.html
12. http://www.sysu-hcp.net/instance-level-salient-object-segmentation/
13. http://cvteam.net/projects/CVPR17-ELE/ELE.html
14. http://mmcheng.net/SOCBenchmark/
?ProductNet, 一个高质量的产品表示学习数据集,用于产生多模态的产品嵌入表示、并加速标注过程。(from 亚马逊)
使用的标注工具:

多模态深度学习网络:
谷歌商品分类法:https://www.google.com/basepages/producttype/taxonomy.en-US.txt
?多模态文件意图识别, 通过引入了1299张Ins图片和相应的文字数据集MDID
(Multimodal Document Intent Dataset),并进行意图标注,建立了多模态分析方法.(from 康奈尔)
相关标注方法:
ELMo:https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md
?高噪声水平下的盲去噪, 图像盲去噪的基本任务是在未知相机参数/退化模型的情况下重建出清晰的结果。但在低光情况下长曝光造成的运动模糊和(高中等)噪声使得传统方法无法处理。研究人员基于l0梯度先验来估计模糊核,并利用解卷积的方法提高去噪性能。(from Université Paris-Saclay)

dataset from:Understanding and evaluating blind deconvolution algorithms
?建筑设备检测系统的开发和研发, (from 爱荷华州立)

?Deep Likelihood Network, 用于多种图像退化过程的图像修复过程。通过在修复网络中加入了简单有效的回归模块来从置信项解耦退化影响(from intel 清华 HIT)

?通过估计卷积核来量化微信图像的清晰度, 可计算清晰度的绝对量化指标,在进一步处理前对图像进行预处理。这种方法的优势还在于完全的盲去噪不需要先验知识。(from Kayrros France)

dataset:https://psg.gsfc.nasa.gov/ https://api.planet.com/ https://developers.planet.com/docs/api/
卫星图像:https://developers.planet.com/
Daily Computer Vision Papers
| STEP: Spatio-Temporal Progressive Learning for Video Action Detection Authors Xitong Yang, Xiaodong Yang, Ming Yu Liu, Fanyi Xiao, Larry Davis, Jan Kautz 在本文中,我们提出了Spatio TEmporal Progressive STEP动作检测器,这是一种用于视频中时空动作检测的渐进式学习框架。从一些粗略的提议长方体开始,我们的方法逐步完善了通过几个步骤采取行动的建议。以这种方式,通过利用先前步骤的回归输出,可以在后面的步骤中逐步获得高质量的提议,即遵守动作运动。在每一步,我们都会及时自适应地扩展提案,以纳入更多相关的时间背景。与在一次运行中执行动作检测的先前工作相比,我们的渐进式学习框架能够自然地处理动作管内的空间位移,因此为空间时间建模提供了更有效的方式。我们广泛评估了我们在UCF101和AVA上的方法,并展示了卓越的检测结果。值得注意的是,我们在具有3个渐进步骤的两个数据集上实现了75.0和18.6的mAP,并且分别仅使用了11个和34个初始提议。 |
| Fashion++: Minimal Edits for Outfit Improvement Authors Wei Lin Hsiao, Isay Katsman, Chao Yuan Wu, Devi Parikh, Kristen Grauman 如果有一件衣服,哪些微小的变化会最大程度地提高它的时尚性。这个问题提出了一个有趣的新视觉挑战。我们介绍时尚,这种方法对全身服装装置进行微调,对其时尚性产生最大影响。我们的模型由深度图像生成神经网络组成,该神经网络学习以每个服装编码学习的方式合成服装。潜在编码根据形状和纹理明确地分解,从而允许分别对拟合呈现和颜色图案材料进行直接编辑。我们将展示如何引导Web照片以自动训练时尚性模型,并开发激活最大化样式方法,将输入图像转换为更时尚的自我。编辑建议的范围从换穿新衣服到调整其颜色,如何穿着,例如卷起袖子,或者它的合身,例如,使裤子变得更加宽松。实验表明,Fashion根据自动化指标和人类观点提供了成功的编辑。项目页面位于 |
| XLSor: A Robust and Accurate Lung Segmentor on Chest X-Rays Using Criss-Cross Attention and Customized Radiorealistic Abnormalities Generation Authors Youbao Tang, Yuxing Tang, Jing Xiao, Ronald M. Summers 本文提出了一种新的胸部X射线肺部分割框架。它包括两个关键贡献,基于交叉注意的基于细分的网络和放射图像的胸部X射线图像合成,即对于数据增强在解剖学上看起来很逼真的合成射线照片。纵横交叉注意模块在所有像素的水平和垂直方向上捕获丰富的全局上下文信息,从而促进准确的肺部分割。为了减少手动注释负担并训练可以适应具有模糊肺部边界的病理性肺的稳健肺分割器,采用图像到图像转换模块来合成来自正常源的异常现象的异常CXR用于数据增强。合成异常CXR的肺部面罩从其正常对应物的分割结果传播,然后用作用于稳健分割器训练的伪掩模。此外,我们在一个更具挑战性的NIH胸部X射线数据集上注释了100个带有肺部面罩的CXR,其中包含后后视图和前后视图以进行评估。大量实验验证了所提框架的稳健性和有效性。代码和数据可以从中找到 |
| Visualizing the decision-making process in deep neural decision forest Authors Shichao Li, Kwang Ting Cheng 深度神经决策森林NDF通过决策树和深度表示学习相结合,在各种视觉任务上取得了显着的成绩。在这项工作中,我们首先跟踪该模型的决策过程并可视化显着性图,以了解输入的哪一部分对分类和回归问题的影响更大。然后,我们在多任务坐标回归问题上应用NDF,并演示路由概率的分布,这对于解释NDF至关重要,但对回归问题没有显示。预先训练的模型和可视化代码将在 |
| Video Object Segmentation and Tracking: A Survey Authors Rui Yao, Guosheng Lin, Shixiong Xia, Jiaqi Zhao, Yong Zhou 对象分割和对象跟踪是计算机视觉社区的基础研究领域。这两个主题很难处理一些常见的挑战,例如遮挡,变形,运动模糊和比例变化。前者包含异构对象,交互对象,边缘模糊和形状复杂性。而后者在处理快速运动,视野和实时处理方面存在困难。结合视频对象分割和跟踪VOST这两个问题可以克服各自的困难,提高性能。 VOST可广泛应用于许多实际应用,如视频摘要,高清视频压缩,人机交互和自动驾驶汽车。本文旨在全面回顾最新的跟踪方法,并将这些方法分为不同的类别,并确定新的趋势。首先,我们提供了分层分类现有方法,包括无监督VOS,半监督VOS,交互式VOS,弱监督VOS和基于分段的跟踪方法。其次,我们提供了不同方法的技术特征的详细讨论和概述。第三,我们总结了相关视频数据集的特征,并提供了各种评估指标。最后,我们指出了一系列有趣的未来作品并得出我们自己的结论。 |
| Realistic Hair Simulation Using Image Blending Authors Mohamed Attia, Mohammed Hossny, Saeid Nahavandi, Anousha Yazdabadi, Hamed Asadi 在这个展示的作品中,我们提出了一个逼真的头发模拟器,使用图像混合的皮肤镜像。该头发模拟器可用于毛发去除方法的基准和验证以及用于改进计算机辅助诊断工具的数据增强。我们采用了一种流行的图像混合实现方法,将逼真的发膜叠加到头发病变上。该方法能够根据预定义的头发蒙版生成逼真的头发蒙版。因此,所产生的头发图像和面具可以用作头发分割和去除方法的基础事实,其通过根据在无毛发区域上的预定毛发掩模修复毛发。此外,我们的现实主义得分等于1.65,相比之下,最先进的头发模拟器的1.59。 |
| Assessing the Sharpness of Satellite Images: Study of the PlanetScope Constellation Authors J r my Anger, Carlo de Franchis, Gabriele Facciolo 新的微卫星星座具有广泛的覆盖范围和较短的重访能力,可实现前所未有的系统监测应用。然而,他们生产的大量图像质量参差不齐,因此需要自动质量评估方法。在这项工作中,我们通过估算每个图像的模糊核来量化PlanetScope星座图像的清晰度。一旦估计了内核,就有可能计算出清晰度的绝对度量,这可以在任何进一步处理之前丢弃低质量图像并对模糊图像进行去卷积。该方法是完全盲目和自动的,并且由于它不需要任何卫星规范的知识,因此可以将其移植到其他星座。 |
| Efficient Blind Deblurring under High Noise Levels Authors J r my Anger, Mauricio Delbracio, Gabriele Facciolo 盲图像去模糊的目的是在不知道相机运动的情况下从模糊运动中恢复清晰图像。现有技术方法在没有噪声或非常低噪声水平的图像上具有非常好的性能。然而,考虑到低光条件是由于需要更长的曝光时间而存在运动模糊的主要原因,所以无噪声假设是不现实的。实际上,运动模糊和高到中等噪声经常一起出现。大多数工作通过首先估计模糊核k然后对噪声模糊图像进行去卷积来解决该问题。在这项工作中,我们首先表明,基于ell 0梯度先验的当前最先进的核估计方法可以适应于处理高噪声水平同时保持其效率。然后,我们表明,通过首先对模糊图像进行去噪,可以显着改善快速非盲去卷积方法。所提出的方法产生的结果等同于使用计算要求更高的方法获得的结果。 |
| A Scalable Handwritten Text Recognition System Authors R. Reeve Ingle, Yasuhisa Fujii, Thomas Deselaers, Jonathan Baccash, Ashok C. Popat 关于离线手写文本识别HTR系统的许多研究都集中在建立用于小型语料库上的线识别的最先进模型。然而,将HTR功能添加到大规模多语言OCR系统提出了新的挑战。本文讨论了构建此类系统数据,效率和集成的三个问题。首先,最大的挑战之一是获得足够数量的高质量培训数据。我们通过使用为大规模生产在线手写识别系统收集的在线手写数据来解决该问题。我们描述了我们的图像数据生成流程,并研究了如何使用在线数据来构建HTR模型。我们表明,在只有少量真实图像可用的情况下,数据显着改善了模型,这通常是HTR模型的情况。它使我们能够以更低的成本支持新脚本。其次,我们提出了一种基于神经网络的线路识别模型,没有循环连接。该模型与基于LSTM的模型实现了相当的精度,同时允许在训练和推理中实现更好的并行性。最后,我们提出了一种将HTR模型集成到OCR系统中的简单方法。这些构成了将HTR能力引入大规模OCR系统的解决方案。 |
| Salient Object Detection in the Deep Learning Era: An In-Depth Survey Authors Wenguan Wang, Qiuxia Lai, Huazhu Fu, Jianbing Shen, Haibin Ling 作为计算机视觉中的一个重要问题,图像中的显着物体检测SOD多年来一直吸引着越来越多的研究工作。毫不奇怪,SOD的最新进展主要由深度学习型解决方案引领,该解决方案名为深度SOD并且已被数百篇已发表的论文反映出来。为了便于深入理解深度SOD,在本文中,我们提供了一个全面的调查,涵盖从算法分类到未解决的开放问题的各个方面。特别是,我们首先从不同角度审视深度SOD算法,包括网络架构,监督级别,学习范式和对象实例级别检测。之后,我们总结了现有的SOD评估数据集和指标。然后,我们根据以前的工作仔细编制SOD方法的全面基准测试结果,并提供详细的比较结果分析。此外,我们通过构造具有丰富属性注释的新型SOD数据集,研究了SOD算法在不同属性下的性能,这些属性以前几乎没有被探索过。我们首次在该领域进一步分析深度SOD模型的稳健性和可转移性w.r.t.对抗性攻击。我们还研究了输入扰动的影响,以及现有SOD数据集的推广和硬度。最后,我们讨论了SOD的几个未解决的问题和挑战,并指出了未来可能的研究方向。所有显着性预测图,我们构建的带注释的数据集和评估代码都公开在 |
| Simple yet efficient real-time pose-based action recognition Authors Dennis Ludl, Thomas Gulde, Crist bal Curio 认识到人类行为是自治系统的核心挑战,因为它们直接与人类共享同一空间。系统必须能够实时识别和评估人类行为。为了训练相应的数据驱动算法,需要大量注释的训练数据。我们展示了一条探测人类的管道,估计它们的姿势,随着时间的推移跟踪它们并使用标准的单目相机传感器实时识别它们的动作。对于动作识别,我们将人体姿势编码为称为编码人类姿势图像EHPI的新数据格式,然后可以使用来自计算机视觉社区的标准方法对其进行分类。通过这个简单的程序,我们在基于姿势的动作检测中实现了竞争性的最先进性能,并且可以确保实时性能。此外,我们在自动驾驶的背景下展示了一个用例,以演示如何使用模拟数据训练这样的系统来识别人类行为。 |
| Deep Q Learning Driven CT Pancreas Segmentation with Geometry-Aware U-Net Authors Yunze Man, Yangsibo Huang, Junyi Feng, Xi Li, Fei Wu 胰腺分割对于医学图像分析很重要,但它面临着阶级不平衡,背景干扰和非刚性几何特征的巨大挑战。为了解决这些困难,我们引入了具有可变形U Net的Deep Q网络DQN驱动方法,通过明确地与上下文信息交互并从胰腺中提取各向异性特征来准确地分割胰腺。基于DQN的模型学习上下文自适应本地化策略以产生视觉上紧密且精确的胰腺定位边界框。此外,可变形U Net通过学习用于特征提取的几何可变形滤波器来捕获胰腺的几何感知信息。 NIH数据集上的实验验证了所提出的框架在胰腺分割中的有效性。 |
| SelFlow: Self-Supervised Learning of Optical Flow Authors Pengpeng Liu, Michael Lyu, Irwin King, Jia Xu 我们提出了一种用于光流的自监督学习方法。我们的方法从非遮挡像素中提取可靠的流量估计,并使用这些预测作为基础事实来学习幻觉遮挡的光流。我们进一步设计了一个简单的CNN,以利用来自多个帧的时间信息来更好地估计流量。这两个原则导致了一种方法,可以在包括MPI Sintel,KITTI 2012和2015在内的具有挑战性的基准测试中获得无监督光流学习的最佳性能。更值得注意的是,我们的自监督预训练模型为监督微调提供了出色的初始化。我们的微调模型可以在所有三个数据集上实现最先进的结果。在撰写本文时,我们在Sintel基准测试中实现了EPE 4.26,优于所有提交的方法。 |
| Listen to the Image Authors Di Hu, Dong Wang, Xuelong Li, Feiping Nie, Qi Wang 视觉到听觉感知替代装置可以通过将视觉信息转换成声音模式来帮助盲人感知视觉环境。为了提高翻译质量,盲人的任务表现通常用于评估不同的编码方案。与基于人类的辛苦评估相比,我们认为机器模型也可以用于评估,并且更有效。为此,我们首先提出两种截然不同的交叉模态感知模型w.r.t。晚期失明和先天失明的情况,旨在根据翻译的声音产生具体的视觉内容。为了验证所提出的模型的功能,两个新的优化策略w.r.t。提出了主要的编码方案。此外,我们进行了一系列基于人的实验,以评估并与交叉模态生成任务中基于机器的评估进行比较。他们高度一致的结果w.r.t.不同的编码方案表明,利用机器模型加速优化评估,降低实验成本在一定程度上是可行的,可以极大地促进编码方案的升级,从而有助于盲人提高视觉感知能力。 |
| Automated Segmentation of Pulmonary Lobes using Coordination-Guided Deep Neural Networks Authors Wenjia Wang, Junxuan Chen, Jie Zhao, Ying Chi, Xuansong Xie, Li Zhang, Xiansheng Hua 肺叶的鉴定在疾病诊断和治疗中具有重要意义。少数肺部疾病在肺叶水平有局部疾病。因此,肺叶的准确分割是必要的。在这项工作中,我们提出了使用胸部CT图像的协调引导深度神经网络自动分割肺叶。我们首先采用自动肺部分割从CT图像中提取肺部区域,然后利用体积卷积神经网络V net来分割肺叶。为了减少不同叶片的错误分类,我们因此采用协调引导的卷积层CoordConvs,其产生肺叶位置信息的附加特征图。所提出的模型在一些公开可用的数据集上进行训练和评估,并且已经达到了现有技术精度,平均Dice系数指数为0.947 pm 0.044。 |
| Deep Likelihood Network for Image Restoration with Multiple Degradations Authors Yiwen Guo, Wangmeng Zuo, Changshui Zhang, Yurong Chen 已经证明卷积神经网络在各种图像恢复任务中非常有效。然而,大多数现有技术解决方案使用具有单个特定退化水平的图像进行训练,并且当应用于一些其他退化设置时可能急剧恶化。在本文中,我们提出了一种称为深度似然网络DL Net的新方法,旨在推广现成的图像恢复网络,以便在保持其原始学习目标和核心架构的同时,在一系列降级设置上取得成功。特别是,我们通过附加一个简单但有效的递归模块来略微修改原始恢复网络,该模块源自保真度术语,用于解开降级的影响。图像修复,插值和超分辨率的广泛实验结果证明了我们DL Net的有效性。 |
| AMNet: Deep Atrous Multiscale Stereo Disparity Estimation Networks Authors Xianzhi Du, Mostafa El Khamy, Jungwon Lee 本文提出了一种新的立体视差估计深度学习架构。拟议的有害多尺度网络AMNet采用了一种高效的特征提取器,具有深度可分离的卷积和扩展的成本量,可在深度特征上部署新颖的立体匹配成本。提出了堆叠的有害多尺度网络,以从成本量聚集丰富的多尺度上下文信息,这允许在多个尺度上以高精度估计差异。 AMNet可以进一步修改为前景背景感知网络FBA AMNet,它能够在多个尺度上区分场景中的前景和背景对象。提出了一种迭代多任务学习方法,用于端到端训练FBA AMNet。所提出的差异估计网络AMNet和FBA AMNet显示出准确的差异估计并推进了具有挑战性的Middlebury,KITTI 2012,KITTI 2015和Sceneflow立体视差估计基准的最新技术水平。 |
| Weakly Supervised Adversarial Domain Adaptation for Semantic Segmentation in Urban Scenes Authors Qi Wang, Junyu Gao, Xuelong Li 语义分割是一种像素级视觉任务,通过使用卷积神经网络CNN快速发展。训练CNN需要大量标记数据,但手动注释数据很困难。对于解放人力,近年来发布了一些合成数据集。然而,它们仍然与真实场景不同,这导致在合成数据源域上训练模型不能在真实的城市场景目标域上实现良好的性能。在本文中,我们提出了一种弱监督的对抗域自适应,以改善从合成数据到真实场景的分割性能,其由三个深度神经网络组成。具体而言,用于短模型的检测和分割DS侧重于检测对象并且预测分割图,像素级域分类器PDC用于短暂尝试以区分图像特征从哪个域,对象级域分类器ODC用于简短区分对象。域并预测对象类。 PDC和ODC被视为鉴别器,DS被视为发生器。通过对抗性学习,DS应该学习域不变特征。在实验中,我们提出的方法在同一问题中产生了mIoU度量的新记录。 |
| LATTE: Accelerating LiDAR Point Cloud Annotation via Sensor Fusion, One-Click Annotation, and Tracking Authors Bernie Wang, Virginia Wu, Bichen Wu, Kurt Keutzer LiDAR光探测和测距是一种必不可少且广泛采用的自动驾驶汽车传感器,特别适用于L4 L5自主驾驶的车辆。最近的工作证明了基于LiDAR的检测的深度学习方法的前景。然而,深度学习算法非常耗费数据,需要大量标记点云数据进行培训和评估。由于以下问题,注释LiDAR点云数据具有挑战性.1 LiDAR点云通常稀疏且分辨率低,使得人类注释器难以识别物体。 2与2D图像上的注释相比,在LiDAR点云上绘制3D边界框甚至点标签的操作更加复杂和耗时。 3 LiDAR数据通常按顺序收集,因此连续帧高度相关,导致重复注释。为了应对这些挑战,我们提出了LATTE,一种用于LiDAR点云的开源注释工具。 LATTE具有以下创新之处1传感器融合我们利用基于图像的检测算法自动预标记校准图像,并将标签传输到点云。 2单击注释除了绘制3D边界框或点标签之外,我们将注释简化为只需单击目标对象,并自动生成目标的边界框。 3跟踪我们将跟踪整合到序列注释中,以便我们可以将标签从一个帧转移到后续帧,从而显着减少重复标记。实验表明,所提出的功能可以将注释速度提高6.2倍,并显着提高标签质量,实例级别精度和召回率分别为23.6和2.2,以及2.0更高的边界框IoU。 LATTE是开源的 |
| Advanced Deep Convolutional Neural Network Approaches for Digital Pathology Image Analysis: a comprehensive evaluation with different use cases Authors Md Zahangir Alom, Theus Aspiras, Tarek M. Taha, Vijayan K. Asari, TJ Bowen, Dave Billiter, Simon Arkell 深度学习DL方法一直在医学想象领域以不同的方式提供最先进的表现,包括数字病理学图像分析DPIA。在许多不同的DL方法中,深度卷积神经网络DCNN技术为分类,分割和检测任务提供了卓越的性能。 DPIA问题中的大部分任务都可以通过分类,分割和检测方法来解决。此外,有时应用前处理和后处理方法来解决某些特定类型的问题。最近,不同的DCNN模型包括初始残留复发CNN IRRCNN,密集连接递归卷积网络DCRCN,循环残余U网R2U网络和基于R2U网络的回归模型UD Net已经提出并提供了针对不同计算机视觉和医学图像的最新性能分析任务。然而,尚未探索这些先进的DCNN模型来解决与DPIA相关的不同问题。在本研究中,我们应用这些DCNN技术来解决不同的DPIA问题,并在数字病理学中针对七种不同任务的不同公开可用基准数据集进行评估,包括淋巴瘤分类,浸润性导管癌IDC检测,细胞核分割,上皮细胞分割,肾小管分割,淋巴细胞检测和有丝分裂检测。用不同的性能指标评估实验结果,例如灵敏度,特异性,准确度,F1评分,接收器操作特征ROC曲线,骰子系数DC和平均值误差MSE。与现有的机器学习和基于DCNN的方法相比,该结果表明了分类,分段和检测任务的卓越性能。 |
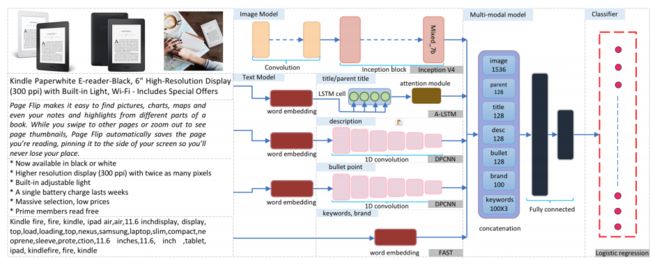
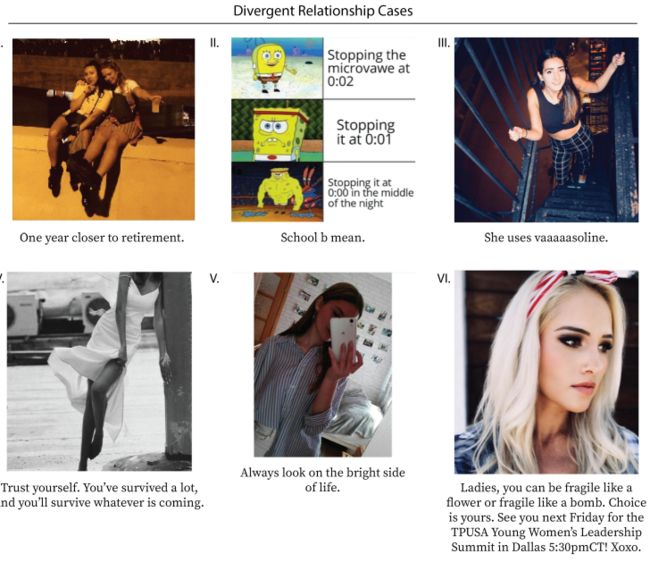
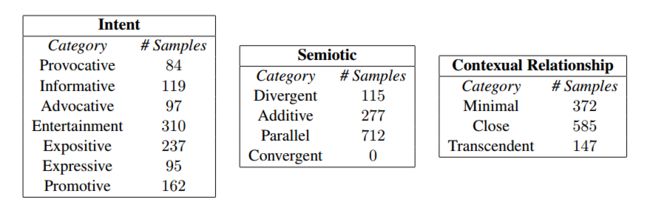
| Integrating Text and Image: Determining Multimodal Document Intent in Instagram Posts Authors Julia Kruk, Jonah Lubin, Karan Sikka, Xiao Lin, Dan Jurafsky, Ajay Divakaran 从诸如Instagram帖子之类的多模态数据计算作者意图需要对文本和图像之间的复杂关系进行建模。例如,标题可能反映在图像上,因此标题和图像都不是另一个的转录本。相反,他们通过所谓的意义乘法结合来创造一种新的意义,与文本和图像的字面意义有更复杂的关系。在这里,我们介绍了1299 Instagram帖子的多模态数据集,标记为三个正交分类法,图像标题对背后的作者意图,图像和标题的字面意义之间的上下文关系,以及图像和标题的表示意义之间的符号关系。我们构建了一个基线深度多模态分类器来验证分类法,表明与仅使用图像模态相比,同时使用文本和图像可以将意图检测提高8,从而证明了非交叉意义乘法的共性。我们的数据集为研究文本和图像配对带来的丰富含义提供了重要资源。 |
| Feature Forwarding for Efficient Single Image Dehazing Authors Peter Morales, Tzofi Klinghoffer, Seung Jae Lee 雾霾会降低内容并模糊图像信息,这会对实时系统中基于视觉的决策产生负面影响。在本文中,我们提出了一种高效的完全卷积神经网络CNN图像去雾方法,设计用于在边缘图形处理单元GPU上运行。我们利用我们架构的三种变体来探索去噪图像质量对参数计数和模型设计的依赖性。提出的前两个变体,小型和大型版本,使用单个有效的编码器解码器卷积特征提取器。最终变体利用一对编码器解码器用于大气光和透射图估计。每个变体以图像细化金字塔池化网络结束,以形成最终的去雾图像。对于单编码器网络的大变体,我们在NYU Depth数据集上展示了最先进的性能。对于小型变体,我们在超分辨率O I HAZE数据集上保持竞争性能,而无需图像裁剪。最后,我们研究了Dense Haze数据集在利用CNN架构进行密集雾度图像去雾和检查损耗函数选择对图像质量的影响时所呈现的一些挑战。包括基准以显示将此方法引入实时系统的可行性。 |
| Feature Fusion for Online Mutual Knowledge Distillation Authors Jangho Kim, Minsung Hyun, Inseop Chung, Nojun Kwak 我们提出了一个名为Feature Fusion Learning FFL的学习框架,它通过融合模块有效地训练强大的分类器,融合模块结合了并行神经网络生成的特征图。具体来说,我们将多个并行神经网络作为子网络进行训练,然后我们使用融合模块组合来自每个子网络的特征映射,以创建更有意义的特征映射。融合的特征图被传递到融合分类器中以进行整体分类。与现有的特征融合方法不同,在我们的框架中,子网络分类器的集合将其知识传递给融合分类器,然后融合分类器将其知识传递回每个子网络,以在线知识蒸馏方式相互教学。这种相互教学的系统不仅提高了融合分类器的性能,而且还获得了每个子网络的性能增益。此外,我们的模型更有益,因为每个子网络可以使用不同类型的网络。我们在多个数据集上进行了各种实验,如CIFAR 10,CIFAR 100和ImageNet,并证明了我们的方法在子网络和融合分类器的性能方面比其他替代方法更有效。 |
| Automated Focal Loss for Image based Object Detection Authors Michael Weber, Michael F rst, J. Marius Z llner 当前的现有技术对象检测算法仍然存在训练数据在对象类和背景上的不均衡分布的问题。最近的工作引入了一种称为焦点丢失的新损失函数来缓解这一问题,但代价是额外的超参数。为每个培训任务手动调整此超参数非常耗时。 |
| Human Motion Prediction via Pattern Completion in Latent Representation Space Authors Yi Tian Xu, Yaqiao Li, David Meger 受认知科学思想的启发,我们提出了一种新颖的通用方法,通过在学习的潜在表示空间上的模式完成来解决人体运动理解。我们的模型在许多任务中优于人类运动预测的当前最先进的方法,没有定制。为了构建各种长度的时间序列的潜在表示,我们提出了一种基于序列到序列学习的新的通用自动编码器。虽然传统的推理策略在输入和输出之间找到相关性,但我们使用模式完成,它将输入视为部分模式并预测最佳的相应完整模式。我们的结果表明,当与我们的自动编码器结合使用时,这种方法在解决人体运动预测,运动生成和动作分类方面具有优势。 |
| A Novel BiLevel Paradigm for Image-to-Image Translation Authors Liqian Ma, Qianru Sun, Bernt Schiele, Luc Van Gool 图像到图像I2I转换是像素级映射,其需要大量配对的训练数据并且经常遭受图像场景中的高度多样性和强类别偏差的问题。为了解决这些问题,我们提出了一种新颖的BiLevel BiL学习范例,它分别在一个特定的IS和一个通用GP级别上交替学习两个模型。在每个场景中,IS模型学习如何维护特定的场景属性。它由GP模型初始化,从所有场景中学习以获得可推广的翻译知识。该GP初始化为IS模型提供了一个有效的起点,从而使其能够快速适应具有稀缺训练数据的新场景。我们在人脸和街景数据集上进行了广泛的I2I翻译实验。定量结果验证了我们的方法可以显着提高经典I2I转换模型的性能,例如PG2和Pix2Pix。我们的可视化结果显示出更高的图像质量和更合适的实例特定细节,例如,人的翻译图像在身份方面看起来更像那个人。 |
| A deep learning based solution for construction equipment detection: from development to deployment Authors Saeed Arabi, Arya Haghighat, Anuj Sharma 本文旨在为研究人员和工程专业人员提供一种实用而全面的基于深度学习的解决方案,以检测施工设备从开发的最初阶段到最后一阶段的部署。本文重点介绍部署的最后一步。解决方案开发的第一阶段,涉及数据准备,模型选择,模型培训和模型评估。该研究的第二阶段包括模型优化,特定应用嵌入式系统选择和经济分析。提出并比较了几种嵌入式系统。对结果的回顾证实了解决方案具有优异的实时性能,并具有一致的90以上的准确率。目前的研究验证了基于深度学习的建筑场景物体检测解决方案的实用性。此外,本研究中提供的详细知识可用于多种目的,如安全监测,生产力评估和管理决策。 |
| Self-Supervised Audio-Visual Co-Segmentation Authors Andrew Rouditchenko, Hang Zhao, Chuang Gan, Josh McDermott, Antonio Torralba 在图像中分割对象并在音频中分离声源是具有挑战性的任务,部分原因是传统方法需要大量标记数据。在本文中,我们开发了一个用于视觉对象分割和声源分离的神经网络模型,通过自我监督从自然视频中学习。该模型是最近提出的将图像像素映射到声音的工作的扩展。在这里,我们介绍了一种学习方法,用于解开神经网络中的概念,并将语义类别分配给网络特征通道,以便在视频上进行视听培训后实现独立的图像分割和声源分离。我们的评估表明,解开模型在语义分割和声源分离方面优于几个基线。 |
| Exploring the Limitations of Behavior Cloning for Autonomous Driving Authors Felipe Codevilla, Eder Santana, Antonio M. L pez, Adrien Gaidon 驾驶需要对各种复杂的环境条件和代理行为做出反应。对每种可能的场景进行明确建模是不现实的。相比之下,模仿学习在理论上可以利用来自大型人力驱动车队的数据。特别是行为克隆已经成功地用于端到端地学习简单的视觉运动策略,但是扩展到全方位的驾驶行为仍然是一个未解决的问题。在本文中,我们提出了一个新的基准来实验性地研究行为克隆的可扩展性和局限性。我们表明行为克隆导致最先进的结果,包括在看不见的环境中,执行复杂的横向和纵向操作,而没有明确编程这些反应。然而,我们确认了由于数据集偏差和过度拟合而导致的众所周知的局限性,由于动态对象导致的新的泛化问题以及缺乏因果模型,以及在行为克隆可以逐渐转向现实世界驾驶之前需要进一步研究的训练不稳定性。所研究的行为克隆方法的代码可以在以下位置找到 |
| VoteNet: A Deep Learning Label Fusion Method for Multi-Atlas Segmentation Authors Zhipeng Ding, Xu Han, Marc Niethammer 深度学习DL方法是许多医学图像分割任务的现有技术。它们提供了许多优势,可以针对特定任务进行培训,计算速度快,测试时间快,分割质量通常很高。相比之下,先前流行的多图谱分割MAS方法相对较慢,因为它们依赖于昂贵的配准,并且即使已经提出了复杂的标签融合策略,DL方法通常优于MAS。在这项工作中,我们提出了一种基于DL的标签融合策略VoteNet,它在本地选择一组可靠的地图集,然后通过多次投票融合其标签。对3D脑MRI数据的实验表明,通过选择良好的初始图谱集,使用VoteNet的MAS显着优于许多其他标签融合策略以及直接DL分割方法。我们还提供了对我们的方法可实现的上限性能的实验分析。尽管在实践中不太可能实现,但这一限制为进一步提高性能提供了空间。最后,为了解决标准MAS的运行时缺点,我们所有的结果都使用了快速DL注册方法。 |
| RepGN:Object Detection with Relational Proposal Graph Network Authors Xingjian Du, Xuan Shi, Risheng Huang 基于区域的物体检测器实现了现有技术的性能,但很少考虑对提案的关系进行建模。在本文中,我们探索了从图学习角度对对象检测提议之间的关系进行建模的想法。具体来说,我们提出了在对象提议上定义的关系提议图网络RepGN以及被建模为边缘的语义和空间关系。通过将我们的RepGN模块集成到对象检测器中,将关系和上下文约束引入到区域的特征提取和边界框的回归和分类中。此外,我们提出了一种新的基于图切割的池化层,用于图的分层粗化,使RepGN模块能够以分层方式利用区域间相关性和场景描述。我们对COCO对象检测数据集进行了大量实验,并显示了有希望的结果。 |
| Class Specific or Shared? A Hybrid Dictionary Learning Network for Image Classification Authors Shuai Shao, Yan Jiang Wang, Bao Di Liu, Rui Xu, Ye Li 字典学习方法可以分为两类,i类特定字典学习ii类共享字典学习。这两个类别之间的区别在于如何使用判别信息。对于第一类,不同类的样本被映射到不同的子空间,这导致基矢量中的一些冗余。对于第二类,不能很好地描述每个特定类中的样本。此外,大多数类共享字典学习方法使用L0范数正则化项作为稀疏约束。在本文中,我们首先通过引入L1范数稀疏约束来代替LC KSVD方法中的常规L0范数正则化项,提出一种新的类共享字典学习方法,即标签嵌入字典学习LEDL。然后,我们提出了一种名为混合字典学习网络HDLN的新型网络,将类特定字典学习与类共享字典学习结合起来,充分描述该特性,提升分类性能。六个基准数据集的广泛实验结果表明,与几种传统分类算法相比,我们的方法能够实现卓越的性能。 |
| Knowledge Distillation via Route Constrained Optimization Authors Xiao Jin, Baoyun Peng, Yichao Wu, Yu Liu, Jiaheng Liu, Ding Liang, Xiaolin Hu 基于蒸馏的学习基于以下假设提高了小型化神经网络的性能:教师模型的表示可以用作结构化且相对弱的监督,因此可以通过小型化模型容易地学习。然而,我们发现聚合重模型的表示仍然是训练小学生模型的强约束,这导致同余损失的高下界。在这项工作中,受课程学习的启发,我们从路线学课程学习的角度考虑知识蒸馏。我们不是用融合的教师模型监督学生模型,而是使用从教师模型经过的参数空间中的路径中选择的一些锚点来监督它,我们称之为路径约束优化RCO。我们通过实验证明,这种简单的操作大大降低了知识蒸馏,提示和模仿学习的同余损失的下限。在CIFAR100和ImageNet等密集分类任务中,RCO分别将知识蒸馏提高了2.14和1.5。为了评估泛化,我们还在开放集面部识别任务MegaFace上测试RCO。 |
| ProductNet: a Collection of High-Quality Datasets for Product Representation Learning Authors Chu Wang, Lei Tang, Yang Lu, Shujun Bian, Hirohisa Fujita, Da Zhang, Zuohua Zhang, Yongning Wu ProductNet是高质量产品数据集的集合,可以更好地理解产品。在ImageNet的推动下,ProductNet旨在通过适当选择的分类法策划高质量的产品数据集来支持产品表示学习。在本文中,构建高质量产品数据集和学习产品表示的两个目标是以迭代的方式相互支持,产品嵌入是通过多模态深度神经网络主模型获得的,该模型旨在利用产品图像和目录信息,作为回报,嵌入通过主动学习本地模型来大大加速注释过程。对于标记数据,建议的主模型产生高分类精度94.7对1240类的前1精度,其可用作机器学习模型的搜索索引,分区键和输入特征。产品嵌入以及针对特定业务任务的精细调整的主模型也可用于各种传输学习任务。 |
| Evolving Deep Neural Networks by Multi-objective Particle Swarm Optimization for Image Classification Authors Bin Wang, Yanan Sun, Bing Xue, Mengjie Zhang 近年来,卷积神经网络CNN已经变得更深,以便在图像分类中实现更好的分类精度。然而,由于难以手动微调超参数以及分类精度和计算成本之间的折衷,因此难以部署用于工业用途的现有技术的深CNN。本文提出了一种新的多目标优化方法,用于在现实生活中应用最先进的CNN技术,自动演化出Pareto前沿的非主导解决方案。首先,设计了一种新的编码策略来编码最好的现有CNN之一。以分类精度和浮点运算次数为两个目标,开发了一种多目标粒子群优化算法。发展非主导解决方案最后但并非最不重要的是,新的基础架构旨在通过在多台机器上同时运行多个GPU上的实验来推动实验,并开发和发布Python库来管理基础架构。实验结果表明,所提出的算法找到的非主导解决方案形成了明确的Pareto前沿,并且所提出的基础设施能够几乎线性地减少运行时间。 |
| Automatic Target Detection for Sparse Hyperspectral Images Authors Ahmad W. Bitar, Jean Philippe Ovarlez, Loong Fah Cheong, Ali Chehab 本章介绍了一种用于高光谱图像的新型目标探测器。探测器独立于未知协方差矩阵,在大尺寸上表现良好,无分布,对大气效应不变,并且不需要构造背景字典。基于鲁棒主成分分析RPCA的修改,给定的高光谱图像HSI被视为由低秩背景HSI和稀疏目标HSI的总和构成,该稀疏目标HSI包含基于由学习者指定的预学习目标字典的目标。用户。稀疏分量即稀疏目标HSI直接用于检测,即,在稀疏目标HSI的非零条目处简单地检测目标。因此,开发了一种新颖的目标检测器,其仅仅是从原始HSI自动生成的稀疏HSI,但仅包含具有背景的目标被抑制。在真实实验中评估探测器,其结果证明了其对高光谱目标探测的有效性,特别是当目标具有与背景重叠的光谱特征时。 |
| DeepLocalization: Landmark-based Self-Localization with Deep Neural Networks Authors Nico Engel, Stefan Hoermann, Markus Horn, Vasileios Belagiannis, Klaus Dietmayer 我们依靠多模态感官信息解决基于地标的车辆自定位问题。我们的目标是根据地标测量和地图标志确定自主车辆的姿态。通过以离线方式从车辆视野中提取地标来构建地图,同时在推断期间以相同方式收集测量值。为了映射测量结果并将地标映射到车辆姿态,我们提出DeepLocalization,一种应对动态输入的深度神经网络。我们的网络对于由于动态环境而发生的缺失地标而言是健壮的,并且处理无序和自适应输入。在现实世界的实验中,我们评估了两种推理方法,以表明DeepLocalization可以与GPS传感器结合使用,并且与过滤方法(如扩展卡尔曼滤波器)互补。我们表明,我们的方法达到了最先进的精度,比相关工作快了十倍。 |
| Understanding Neural Networks via Feature Visualization: A survey Authors Anh Nguyen, Jason Yosinski, Jeff Clune 理解大脑的神经科学方法是寻找和研究高度激活单个细胞或细胞群的优选刺激。机器学习的最新进展使得一系列方法能够合成优选的刺激,这些刺激导致人工或生物脑中的神经元强烈地发射。这些方法称为激活最大化AM或通过优化的特征可视化。在本章中,我们回顾了文献中现有的AM技术2讨论了AM的概率解释,并回顾了AM在调试和解释网络中的应用。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com