C++面试之Linux操作系统
1、 Linux的I/O模型介绍以及同步异步阻塞非阻塞的区别
1、IO
IO(输入/输出)即数据的读取或者写入操作,通常用户进程的一个完整的IO操作包含:用户<-->内核,内核,<--->设备空间。IO有内存IO、网络IO和磁盘IO三种,我们所说的IO一般值得是后两者。

Linux中进程无法直接操作IO设备,必须通过系统调用请求kernel来协助完成IO动作,内核会为IO设备维护一个缓冲区。 对于一个输入操作来说,进程IO系统调用后,内核会先看缓冲区有没有相应的缓存数据,没有的话再到设备中读取,因为设备IO一般速度较慢,需要等待。对于网络输入操作通常有两个不同阶段:
1、等待数据到达网卡-->读取到内核缓冲区,数据准备好
2、从内核缓冲区复制数据到进程空间2、5种IO模型
阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动IO模型、异步IO模型。
2.1、阻塞IO模型
概念:进程发起IO系统调用后,进程被阻塞,转到内核处理,整个IO处理完毕后返回进程。操作成功则进程获取数 据。
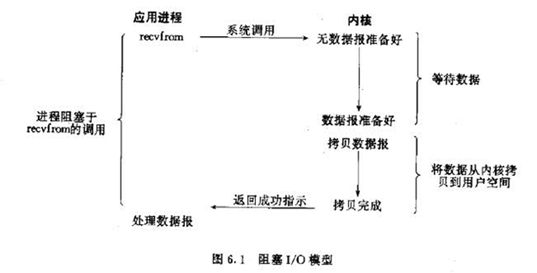
特点:(1)进程阻塞挂起不消耗CPU资源,及时响应每个操作
(2)实现难度低、开发应用较容易
(3)适用并发量小的网络应用开发
2.2、非阻塞IO模型
概念:进程发起IO系统调用后,如果内核缓冲区没有数据,需要到IO设备读取,进程返回一个错误而不会被阻塞;进程发起IO 系统调用后,如果缓冲区有数据,内核就会把数据返回进程。
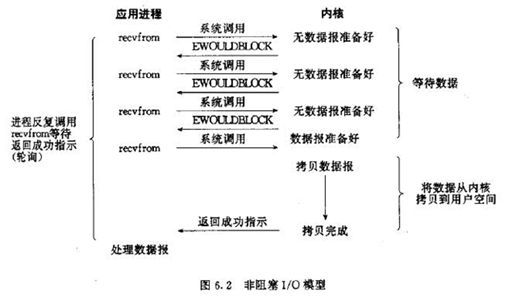
特点:(1)进程轮询调用,消耗CPU的资源
(2)实现难度低、开发应用相对阻塞IO较难
(3)适用于并发量小、且不需要及时响应的网络应用开发
2.3、IO复用模型
概念:多个进程的IO可以注册到一个复用器(例如select)上,然后用一个进程调用该复用器,复用器会监听所有注册进来的 IO;如果监听的IO在内核都没有可读数据,复用器调用进程会被阻塞,当任意IO有数据,复用器调用就会返回;而后复用器调用进 程可以自己通知另外的进程来发起读取IO,读取内核中准备好的数据。
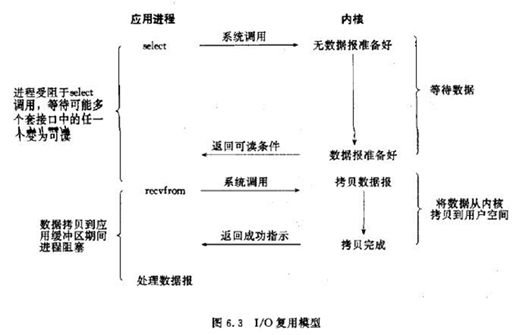
应用:select、poll、epoll三种方案
Linux中IO复用的实现方式主要有select、poll、epoll三种:
(1)select:注册IO、阻塞扫描、监听的IO最大连接数不能多于FD_SIZE;
(2)poll :原理与select相似,没有数量限制,但是IO数量大扫描线性性能下降
(3)epoll : 事件驱动不阻塞,mmap实现内核与用户控件的消息传递,数量大。特点:(1)专一进程解决多个进程IO的阻塞问题
(2)实现开发难度大
(3)适用高并发应用程序开发;一个进程响应多个请求
2.4、信号驱动IO模型
概念:当进程发起一个IO操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进 程,进程便在信号处理函数中调用IO读取数据。
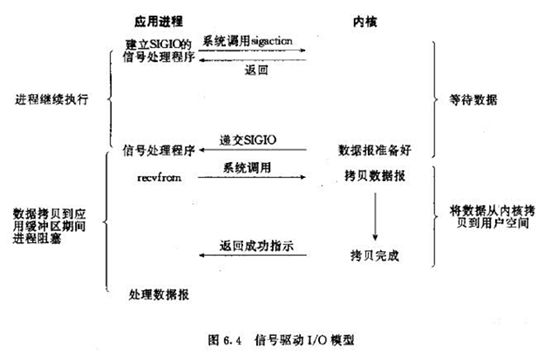
2.5、异步IO模型
概念:当进程发起一个IO操作,进程返回(不阻塞),但也不能返回结果;内核把整个IO处理完后,便会通知进程结果。如果 操作成功则进程直接获取到数据。
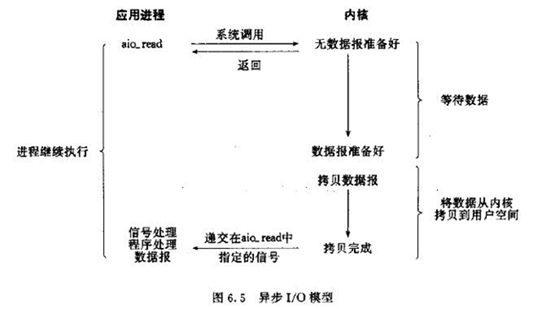
3、阻塞IO调用和非阻塞IO调用,阻塞IO模型和非阻塞模型
注意这里的阻塞IO调用和非阻塞IO调用不是指阻塞IO模型和非阻塞IO模型
(1)阻塞IO模型是一个阻塞IO调用,而非阻塞IO模型是多个非阻塞IO调用+一个阻塞IO调用,因为多个IO检查会立即返回错误,不会阻塞进程。
(2)而上面也说过了,非阻塞IO模型对于阻塞IO模型来说区别就是,内核数据没准备好需要进程阻塞的时候,就返回一个错误,以使得进程不被阻塞。| 阻塞IO调用 | 在用户进程(线程)中调用执行的时候,进程会等待该IO操作,而使得其他操作无法执行。 |
| 非阻塞IO调用 | 在用户进程中调用执行的时候,无论成功与否,该IO操作会立即返回,之后进程可以进行其他操作(当然如果是读取到数据,一般就接着进行数据处理)。 |
| 同步IO | 导致请求进程阻塞,直到I/O操作完成。 |
| 异步IO | 不导致请求进程阻塞。 |
| 同步IO | 用户进程发出IO调用,去获取IO设备数据,双方的数据要经过内核缓冲区同步,完全准备好后,再复制返回到用户进程。而复制返回到用户进程会导致请求进程阻塞,直到I/O操作完成。 |
| 异步IO | 用户进程发出IO调用,去获取IO设备数据,并不需要同步,内核直接复制到进程,整个过程不导致请求进程阻塞。 |
2、文件系统的理解(EXT4,XFS,BTRFS)
文件系统无非就是组织文件如何储存。主要用于控制所有程序在不使用数据时如何存储数据、如何访问数据以及有什么其它信息(元数据)和数据本身相关,等等
Linux系统文件系统管理:
Linux文件系统:ext2,ext3,ext4,xfs,btrfs,reiserfs,jfs,swap
swap:交换分区,是一种比较特殊的文件系统,将硬盘当内存用
windows:fat32,ntfs
unix:FFS,UFS,JFS2
网络文件系统:NFS,CIFS
集群文件系统:GFS2,OCFS
分布式文件系统:CEPH,MOOSEFS
根据是否支持日志功能:
日志型文件系统:ext3,ext4,xfs
非日志型文件系统:ext2,vfat
关于日志:
我们往电脑上下载一个电影,系统会先建立电影的元数据,再存储电影,传着传着断电了,那么之前存的一半数据就不能用了, 那么检查这些损坏文件非常麻烦,还很慢,这就是非日志型文件系统;
日志型文件系统会先将元数据存放在日志区,电影下完了没问题,再转移到元数据区,若是中途断电了,只需要在日志区寻找日 志文件就可以了;
所以,日志型文件系统,系统检测非常快,但是需要将日志区的元数据转移到元数据区,等于多了一次I/O操作,性能上会比非日 志文件系统差一些,但是现在这些差异已经微乎其微了。所以,推荐使用日志型文件系统
3、文件处理grep,awk,sed这三个命令必知必会
http://www.cnblogs.com/zhang-jun-jie/p/9266791.html
4、IO复用的三种方法(select,poll,epoll)深入理解,包括三者区别,内部原理实现?
5、Epoll的ET模式和LT模式(ET的非阻塞)
6、查询进程占用CPU的命令(注意要了解到used,buf,cache代表意义)
可以直接使用top命令后,查看%MEM的内容。可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用如下的命令:
(1)top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
可以直接使用top命令后,查看%MEM的内容。可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用如下的命令:
$ top -u oracle
内容解释:
PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
常用的命令:
P:按%CPU使用率排行
T:按MITE+排行
M:按%MEM排行
(2)pmap
可以根据进程查看进程相关信息占用的内存情况,(进程号可以通过ps查看)如下所示:
$ pmap -d 14596
(3)ps
如下例所示:
$ ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' 其中rsz是是实际内存
$ ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' | grep oracle | sort -nrk5
其中rsz为实际内存,上例实现按内存排序,由大到小
7、linux的其他常见命令(kill,find,cp等等)
8、shell脚本用法
9、硬连接和软连接的区别
10、文件权限怎么看(rwx)
11、文件的三种时间(mtime, atime,ctime),分别在什么时候会改变
1、访问时间(atime->access time):读一次这个文件的内容,这个时间就会更新。比如对这个文件运用 more、cat等命令。ls、stat命令都不会修改文件的访问时间。
2、修改时间(mtime->modifiy time):修改时间是文件内容最后一次被修改时间。比如:vi后保存文件。ls -l列出的时间就是这个时间。
3、状态改动时间(ctime->change time):ctime是在写入文件、更改所有者、权限或链接设置时随i节点的内容更改而更改的,是该文件的i节点最后一次被修改的时间,通过chmod、chown命令修改一次文件属性,这个时间就会更新。
4、ls命令簇
1) ls -lc filename 列出文件的 ctime (最后状态更改时间)
2) ls -lu filename 列出文件的 atime(最后访问时间)
3) ls -l filename 列出文件的 mtime (最后修改时间)
5、stat命令
stat命令可以一次性更精确的看到文件的三种时间属性。
6、操作对三种时间属性的影响:
1、cat、less等只访问文件,不修改文件的操作,只会修改atime的值。
2、chmod、chown等修改文件权限、所有者等的操作,会修改atime和ctime的值。
3、vim、emacs等修改文件内容的操作,会修改atime、ctime、mtime的值。