在轻松气氛中浅谈——Apache Kylin
我简书下同步更新此篇文章:https://www.jianshu.com/p/26c18e6a30c3
一.Kylin是什么?
我这个人不喜欢贴一大堆难懂的话,所以我不扯淡,直接和大家分享我的理解:Kylin是做大数据查询的!补充一下就是,可以帮助我们对大数据进行多维度的分析。提高查询效率。
二.Kylin架构
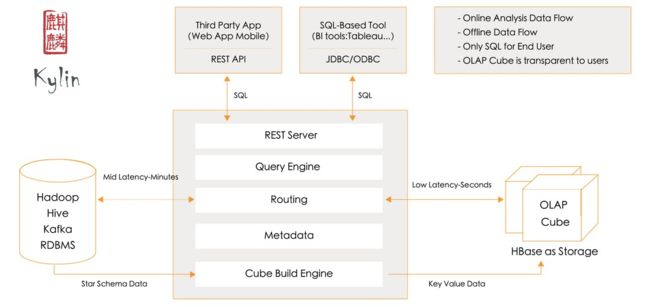
简单的讲解一下图片,以Hive或者Kafka作为数据源,里面保存着真实表,而Kylin做的就是将数据进行抽象,通过引擎实现Cube的构建。
将Hbase作为数据的仓库,存放Cube。因为Hbase的直接读取比较复杂,所以Kylin提供了近似SQL和HQL的形式,满足了数据读取的基本需求。对外提供了RestApi和JDBC/ODBC方便操作。
三.讲点不容易理解,但是比较重要的
首先需要问几个问题:
- 1.什么是数据仓库?
- 2.什么是维度?什么是度量?
- 3.事实表是啥?维度表又是啥?维度表有必要存在吗?
- 4.Hive是做啥的?那我们为啥不拿起Hive就开始查?
如果几个问题你知道答案,就可以跳过这段了~
好的,留下的一定是想继续看的,现在做些解答
1.数据仓库

对,根据图片我们可以把数据仓库理解成数据们居住的小房子。
利用数据仓库方式存的资料,所具备的特性是一旦存入,变不宜随着时间发生变动的特性。而且资料必定包含着时间的属性的。
如果你无法理解,可以在脑海中想象,数据是否可以进入小房子居住,取决于他是否满足以下的两个条件——首先,必须有身份证!也就是必须知道自己的出生日期。其次,本身不会经常的被修改,可以让新的住进来,但老的别天天变脸啊。
为啥要有这俩特性呢?答案是:是大数据啊!大数据的价值在于被分析,这样的结构有利于制定分析方式,发掘出准确有价值的咨询。
2.什么是维度?什么是度量?
维度: 度量:
度量:
维度和度量是数据分析中的两个基本概念。
- 维度代表着我们审视数据的角度
通常是数据记录的一个属性,时间是一种维度,地点是一种维度,状态是一种维度。 - 度量代表着基于数据所计算出来的考量值
通常是一个数值,比如这个月份的销售额,购买某产品的客户量。
所谓的数据分析,就是要结合若干维度去审查度量值,找到其中变化的规律。
3.事实表?维度表?
- 事实表是储存有事实记录的表,例如日志就是一种事实表,它一般在不断的动态增长,所以它的体积通常很大。
- 维度表是对应事实表的一种体现,保存了维度值,可以关联上事实表,相当于把事实表精细处理,然后生成的一张表。
如果事实表过于庞大笨重,可以考虑使用维度表。
举个栗子:我可以把一张事实表,拆开,生成两种表,一张日期表,日期表里面存储着日期对应的周、月、季度、年等时间属性。一张地点表,地点表里包含着国家、省、城市等属性。优点就是将事实表进行瘦身,便于维度的管理和维护,不至于破坏事实表。减少了工作量,大多数是重复的查询工作。
4.Hive是啥?为啥不直接用Hive查?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
上面的话是不是很枯燥?相信大家基本看完都是这个表情:
可惜,这就是网络上专业大牛的解释,在百度百科上(摊手)~说了一大段,还是没解释明白:这就要你拿起来Hive就开始用的理由???那我凭啥不用MySQL呢?!
可能我比较直白吧,要问我啥是Hive,我这样说:Hive是存大数据的,是一种数据仓库!!!
。。。。。。
诶诶诶!你们先别动手!!!我话还没说完,大家想一想,为啥不提倡用MySQL存大数据?
答案就在前文提到过的——大数据两个特性,一是具备时间属性,二是数据不经常变动。第二点就是答案!数据库是面向事务去设计的,而数据仓库是面向主题的。
我们在MySQL存储的数据是围绕着事务展开的,这就代表着,它可能会经常的变动,而且不应该过于冗余,还应该尽量避免数据的冗余!
但是对于数据仓库Hive来说,我们就是要数据尽量的去冗余!!数据大了才叫大数据,才可以去分析!才有价值啊!数据本来就没几条,还天天变化,没事还给我删点,那我分析个啥啊!Hive支持的HQL基本和SQL差不多,功能上稍微的少了一丢丢,但是足够了。
可能有同学就开始了:
“那我全存Hive里不就行了??反正是数据越多越好!还用啥MySQL啊?咱全换Hive吧!”
“emmmmmmmmm!”
Hive实在是太慢了,要是全换成了Hive,还查业务吗???
简单给大家说说为啥Hive查的慢:
- 首先,是数据格式的问题,Hive没有专门去定义数据格式,格式是用户指定的,MySQL人家存储引擎里自己- 定义完数据格式了,人家的数据都是有组织有纪律的!
- 其次,索引的问题,Hive是一点都不给你处理数据的机会啊,还索引呢,扫描都不给你做!我们查值的时候,Hive是暴力的全走查一遍,本来数据量就打,即使在MapReduce帮助下,Hive支持并行访问了。但是这个MapReduce就有意思了,它不是Hive本身的引擎,它去执行Hive查询的动作还有延迟呢! 在速度上拿什么和关系型数据库比?!
总结一下:Hive是分析大数据用的。mysql是捕获数据在业务场景使用的,各有各的用武之地。
4.Kylin核心——Cube到底是怎么让查询变快的
我们从上文得知,Hive的查询很慢,那么我们怎么去多维度分析Hive上的数据呢?难道只有等待吗?
当然不是!!!
相信大家会有一个思路——我们每天定时将hive的数据进行聚合然后更新到MySQL上,这不就完事了吗?
对!我们之前就是这么做的,这么做看似解决了问题,实际上依然有很多缺陷:
- 首先,数据从Hive转回MySQL,中间要通过代码设置很多环节,尤其还要使用到Sqoop。不灵活。
- 其次,因为最后是存在MySQL上。前面说过了,MySQL上是避免存放过于冗余的数据的,这就是又把好不容易解决的数据冗余问题抛回来了嘛!
- 最后,也是很严重的问题,由于不灵活,导致我们在得到的MySQL上可分析的方向受到了限制。之前只支持单维度的!或者说双维度,也就是时间加某一种维度,当面临着多维度分析的挑战,继续依靠mysql将显得力不从心。
此时,我们急需一种,可以快速查询数据仓库的大数据工具!!!!!!!

问得好!这个时候Kylin就出现了~
Kylin有两个法宝:预加载 和 Cube
预加载,稍微好理解点吧?就是我趁你们睡觉的时候,把东西算好了,等你问我的时候,我不去现场计算了,我去直接找就好了嘛!
Cube,给你们一张图,图片来源于网络:
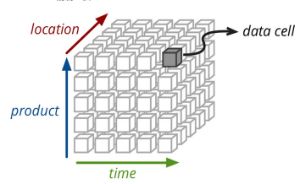
这张图是Cube的一种便于观察的展现方式,并不是说,它就是正方体的!!!因为正方体是三维图形,而人类更能接受三维及三维以下的图形。。。咳咳,扯远了,这我不讲了,想了解去研究一下数学去!!!
三个维度,依次是时间、产品、地点。维度线上面,就是维度值。度量是上面的小块块。
可以清楚的看到,图形内确定了三个维度,一定可以获取到一个小方块。这个小方块就是最后我们想要的值。这就是Cube的核心。即:我不去大量计算了,你的维度值组合已经牢牢的被我Cube给提前背下来了,Kylin可以拿出这个块,骄傲的说:“我有法宝!”
这里真的理解了吧?那么为了不让大家觉得Cube就是个正方体,给大家看一下Cube其他情况下的样子,上面是三维,给大家看一个,比如说。。。四维:
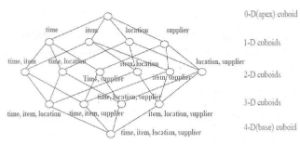
形象仅仅是一种展示形式,只是皮囊。我们看一下组合方式
比如说有四个维度 time 、item 、location 、supplier
那么有多少组合呢?答案是:2的四次幂=16种
零维:[] 1种
一维:[ time ] 、[ item ] 、[ location ] 、[ supplier ] 4种
二维:[time、item] 、[time、location]、[time、supplier]、[item、location]、[item、supplier]、[location、supplier] 6种
三维:[time、item、location]、[time、item、supplier]、[item、location、supplier]、[time、location、supplier] 4种
四维:[time、item、location、supplier] 1种
但是Kylin提供了更加方便的构建策略,在这个基础上进一步的减少组合!一共有三个策略!这里先不细说,有兴趣的同学可以来私信我讨论,当然后面心情好就更新。

这时候可能又有同学站出来了:
“那我全存Hive里,用Kylin不就行了?反正数据多,还查的快! 还用啥MySQL啊?咱全换Hive+Kylin吧!” “emmmmmmmmm!”
Kylin快是快!!!但那可是要预加载的啊!!!要提前准备数据的!!!
都说了MySQL是用来查实时的! 实时的!!实时的!!!!!
实时的!!实时的!!!!!
让客户今天去查昨天算出来的数据???
5.总结
Kylin解决了大数据下,数据分析和查询的效率问题,但是技术和工具从来不是抓着同一个东西就往死里用。Kylin有他的优势,也有它的局限。通过配合,最大化的发挥各种工具的价值才是硬道理~多嘴提一句,kylin主要是把预计算的东西存在Hbase里了。
6.最后
总之就当我是把自己最近学大数据,和对大数据的理解写上来,基本是一堆胡言乱语,如果对大家有启发那是我的荣幸,如果有哪些地方不对希望也可以指正~很多东西觉得不好用语言描述,没有全写下来,心情好就可以继续更新这类文章。