HEVC视频编码部分概念整理
部分摘录https://blog.csdn.net/qq_21747841/article/details/73332394,感谢 慢慢积累不怕寂寞。在此,学习一下。
部分摘录 https://blog.csdn.net/HEVC_CJL/article/details/8170646 感谢作者作者:hevc_cjl 。
对于一个完整的HM解决方案来说,总共包含了7个工程:1. TAppCommon 2. TAppDecoder 3. TAppEncoder 4. TLibCommon 5. TLibDecoder 6. TLibEncoder 7. TLibVideoIO
其中,'T'代表'Test'(这一个的理解可能有误),'App'代表'Application',表明该工程主要包含一些应用函数,'Lib'代表'Library',表明该工程主要包含一些库函数,这里顺便提一下,应用函数与库函数的主要区别是:前者是面向用户的,主要是通过调用若干库函数实现更为丰富和复杂的功能,而后者是面向程序设计者的,或者说对用户是不可见的,它由程序设计者来实现,主要是对一些基本的功能进行底层设计与实现,对于用户来说,只关心这些库函数的接口以及如何调用,不需也不应该关心它的实现。'Common'表明该工程包含的一些函数是编码器和解码器共用的,'Decoder'表明该工程包含的函数是解码器使用的,而'Encoder'表明该工程包含的函数是编码器使用的。'VideoIO'工程主要是实现对YUV文件的读写操作。
ISO/IEC Moving Picture Experts Group(MPEG)
树形编码单元(coding tree units,CTUs)其又可以分为亮度和色度的
树形编码块(coding tree blocks,CTBs)
预测单元(prediction units,PUs)
变换单元(transform units,TUs)
并行处理工具:
波前编码(Wavefront parallel processing ,WPP)
熵编码
上下文自适应的二进制算数编码CABAC
环路滤波器
HEVC指定了两种环路滤波器,即去块滤波器(deblocking filter,DBF)和采样自适应偏移滤波器(sample adaptive offset,SAO)
HEVC的档次
2013年1月的HEVC草案定义了三种档次:Main,Main 10和main静态图像档次。这三个档次的限制条件如下:
(1)只支持4:2:0色度采样信号;(2)使用了tiles便不能使用WPP,每一个tile的亮度分辨率至少要为256×64;(3)Main和静态图像档次仅支持8位像素,Main10档次支持10位像素;(4)静态图像档次不支持帧间预测。
目前,HEVC定义了13个不同的级别,分别支持从QCIF到8k多种分辨率的图像。图像宽高受到该级别定义参数MaxLumaPS参数的限制。对第四级及更高级,可支持两个层。
IDR(Instantaneous Decoding Refresh)——即时解码刷新
non-IDR(non-Instantaneous Decoding Refresh)——非即时解码刷新
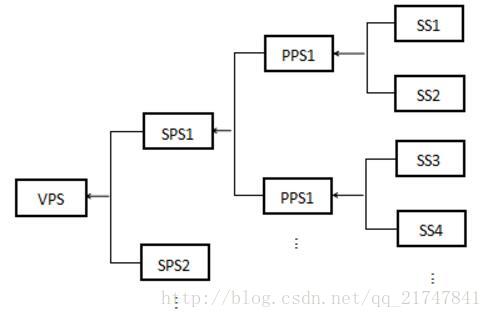
SS(Slice Segment)——片段
SEI(Supplement Enhancement Information)——补充增强信息
CVS(Coded Video Sequence)——编码视频序列
SPS(Sequence Parameter Set)——序列参数集:一个CU的最小尺寸在SPS中标记,其取值范围可以从8×8一直到CTU的大小。当一个子块的大小达到SPS所规定的最小CU大小时,则该子块自动不再进行下一次分割。因此,如果一个低复杂度编码器规定只采用某个大小以上的CU尺寸,那么可以在SPS中指定,这样可以避免编码多余的split_cu_flag的标识。在常用的编码器设置中,CU的大小通常设置为从8×8到64×64。
PPS(Picture Parameter Set)——图像参数集
VPS(Video Parameter Set)——视频参数集
VPS主要用于传输视频分级信息,有利于兼容标准在可分级视频编码或多视点视频的扩展,对于一个视频序列,无论它每一层的SPS是否相同,都参考相同的VPS。SPS为包含一个CVS(GOP)中所有编码图像的共享编码参数。包含一幅图像所用的公共参数,即一幅图像中所有片段SS(Slice Segment)引用同一个PPS。
QP(Quantization Parameter)——量化参数
NAL(Network Abstract Layer)——网络抽象层
NALU(Network Abstract Layer Unit)——网络适配单元
VCLU(VCL NALU)——承载视频片压缩数据的NALU
VCL (Video Coding Layer)——视频编码层
HRD(Hypothetical Reference Decoder)——虚拟参考解码器
BLA(Broken Link Access)——断链访问
CRA(Clean Random Access)——完全随机获取
VUI(Video Usability Information)——视频可视化可用信息
POC(Picture order count)——图像序列计数
SAO(Sample Adaptive Offset)——样点自适应补偿
IRAP(Intra Random Access Point)——随机接入点
AU(Access Unit)——接入单元
SAP(Sample Adaptive intra-Prediction)——自适应预测
RQT(residual quardtree)——四叉树结构
SAD(Sum of Absolute Difference)=SAE(Sum of Absolute Error)即绝对误差和
SATD(Sum of Absolute Transformed Difference)即hadamard变换后再绝对值求和
SSD(Sum of Squared Difference)=SSE(Sum of Squared Error)即差值的平方和
MAD(Mean Absolute Difference)=MAE(Mean Absolute Error)即平均绝对差值
MSD(Mean Squared Difference)=MSE(Mean Squared Error)即平均平方误差
如果不用率失真最优化,选择SATD+delta×r(mv,mode)作为模式选择的依据。运动估计中,整象素搜索用SAD,而亚象素用SATD,帧内模式选择要用SATD?
SAD即绝对误差和,仅反映残差时域差异,影响PSNR值,不能有效反映码流的大小。SATD即将残差经哈德曼变换的4×4块的预测残差绝对值总和,可以将其看作简单的时频变换,其值在一定程度上可以反映生成码流的大小。因此,不用率失真最优化时,可将其作为模式选择的依据。
一般帧内要对所有的模式进行检测,帧内预测选用SATD的原因同上。
在做运动估计时,一般而言,离最优匹配点越远,匹配误差值SAD越大,这就是有名的单一平面假设,现有的运动估计快速算法大都利用该特性。但是,转换后SATD值并不满足该条件,如果在整象素中运用SATD搜索,容易陷入局部最优点。而在亚象素中,待搜索点不多,各点处的SAD差异相对不大,可以用SATD选择码流较少的匹配位置。