【LOSS】语义分割的各种loss详解与实现
前言:
在参加Kaggle的比赛中,有时遇到的分割任务是那种背景所占比例很大,但是物体所占比例很小的那种严重不平衡的数据集,这时需要谨慎的挑选loss函数。
Loss:
1.Log loss
log loss其实就是TensorFlow中的 tf.losses.sigmoid_cross_entropy 或者Keras的 keras.losses.binary_crossentropy(y_true, y_pred)
![]()
其中: ![]() ,
, ![]()
乍看上去难以理解loss函数的意义,也就是说不明白为什么这个函数可以当做损失函数。
其实我们可以对上面的公式进行拆分:
![]()
第一行:当y=1 时,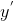 越大就与y越接近,即预测越准确,loss越小;
越大就与y越接近,即预测越准确,loss越小;
第二行:当y=0 时,越小就与y越接近,即预测越准确,loss越小;
最终的loss是y=0和y=1两种类别的loss相加,这种方法有一个明显缺点,当正样本数量远远小于负样本的数量时,即y=0的数量远大于y=1的数量,loss函数中y=0的成分就会占据主导,使得模型严重偏向背景。
所以对于背景远远大于目标的分割任务,Log loss效果非常不好。
2、Dice Loss
首先定义两个轮廓区域的相似程度,用A、B表示两个轮廓区域所包含的点集,定义为:
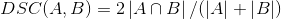
那么loss为:
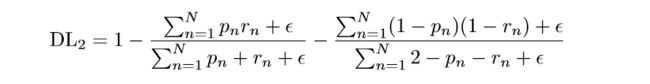
可以看出,Dice Loss其实也可以分为两个部分,一个是前景的loss,一个是物体的loss,但是在实现中,我们往往只关心物体的loss,Keras的实现如下:
def dice_coef(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3])
return K.mean( (2. * intersection + smooth) / (union + smooth), axis=0)
def dice_coef_loss(y_true, y_pred):
1 - dice_coef(y_true, y_pred, smooth=1)
上面的代码只是实现了2分类的dice loss,那么多分类的dice loss又应该是什么样的呢?
注:正确性还没验证。。。
# y_true and y_pred should be one-hot
# y_true.shape = (None,Width,Height,Channel)
# y_pred.shape = (None,Width,Height,Channel)
def dice_coef(y_true, y_pred, smooth=1):
mean_loss = 0;
for i in range(y_pred.shape(-1)):
intersection = K.sum(y_true[:,:,:,i] * y_pred[:,:,:,i], axis=[1,2,3])
union = K.sum(y_true[:,:,:,i], axis=[1,2,3]) + K.sum(y_pred[:,:,:,i], axis=[1,2,3])
mean_loss += (2. * intersection + smooth) / (union + smooth)
return K.mean(mean_loss, axis=0)
def dice_coef_loss(y_true, y_pred):
1 - dice_coef(y_true, y_pred, smooth=1)
3、FOCAL LOSS
大名鼎鼎的focal loss,先看它是如何改进的:注意下面这个可不是完整的Focal Loss
![]()
其中gamma>0
在Focal Loss中,它更关心难分类样本,不太关心易分类样本,比如:
若 gamma = 2,
对于正类样本来说,如果预测结果为0.97那么肯定是易分类的样本,所以![]() 就会很小;
就会很小;
对于正类样本来说,如果预测结果为0.3的肯定是难分类的样本,所以![]() 就会很大;
就会很大;
对于负类样本来说,如果预测结果为0.8那么肯定是难分类的样本,![]() 就会很大;
就会很大;
对于负类样本来说,如果预测结果为0.1那么肯定是易分类的样本,![]() 就会很小。
就会很小。
另外,Focal Loss还引入了平衡因子alpha,用来平衡正负样本本身的比例不均,完整的Focal Loss如下:

alpha取值范围0~1,当alpha>0.5时,可以相对增加y=1所占的比例。实现正负样本的平衡。
虽然何凯明的试验中,lambda为2是最优的,但是不代表这个参数适合其他样本,在应用中还需要根据实际情况调整这两个参数。
def focal_loss(y_true, y_pred):
gamma=0.75
alpha=0.25
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
pt_1 = K.clip(pt_1, 1e-3, .999)
pt_0 = K.clip(pt_0, 1e-3, .999)
return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) * K.pow( pt_0, gamma) * K.log(1. - pt_0))
在实际应用中,我们可以使用多种loss函数相互组合得到更好的结果
4、Focal Loss + DICE LOSS
Focal Loss 和 Dice Loss的结合需要注意把两者缩放至相同的数量级,使用-log放大Dice Loss,使用alpha缩小Focal Loss
def mixedLoss(y_ture,y_pred,alpha)
return alpha * focal_loss(y_ture,y_pred) - K.log(diceA_loss(y_true,y_pred))5.BCE + DICE LOSS
def bce_logdice_loss(y_true, y_pred):
return binary_crossentropy(y_true, y_pred) - K.log(1. - dice_loss(y_true, y_pred))6、WEIGHTED BCE LOSS
相比dice loss增加了参数 weight,没看明白怎么个意思,我以为weight会是个数组呢,包含w1和w2,分别与y_pred和y_true相乘呢....待改日查查论文
def weighted_dice_loss(y_true, y_pred, weight):
smooth = 1.
w, m1, m2 = weight, y_true, y_pred
intersection = (m1 * m2)
score = (2. * K.sum(w * intersection) + smooth) / (K.sum(w * m1) + K.sum(w * m2) + smooth)
loss = 1. - K.sum(score)
return loss7、WEIGHTED BCE DICE LOSS
def weighted_bce_dice_loss(y_true, y_pred):
y_true = K.cast(y_true, 'float32')
y_pred = K.cast(y_pred, 'float32')
# if we want to get same size of output, kernel size must be odd
averaged_mask = K.pool2d(
y_true, pool_size=(50, 50), strides=(1, 1), padding='same', pool_mode='avg')
weight = K.ones_like(averaged_mask)
w0 = K.sum(weight)
weight = 5. * K.exp(-5. * K.abs(averaged_mask - 0.5))
w1 = K.sum(weight)
weight *= (w0 / w1)
loss = weighted_bce_loss(y_true, y_pred, weight) + dice_loss(y_true, y_pred)
return loss8、 Mean IOU
mean IOU字面理解就是平均的IOU,不过计算时需要设置多个阈值(0.5, 1.0, 0.05),是指在阈值范围内分别计算IOU,取均值。
def mean_iou(y_true, y_pred):
prec = []
for t in np.arange(0.5, 1.0, 0.05):
y_pred_ = tf.to_int32(y_pred > t)
score, up_opt = tf.metrics.mean_iou(y_true, y_pred_, 2)
K.get_session().run(tf.local_variables_initializer())
with tf.control_dependencies([up_opt]):
score = tf.identity(score)
prec.append(score)
return K.mean(K.stack(prec), axis=0)
2019/1/16补充:
一般在分割模型中我们有时会用intersection over union去衡量模型的表现,按照IOU的定义,比如对predicted instance和actual instance的IOU大于0.5算一个positive,在这个基础上再做一些F1,F2之类其他的更宏观的metric。
所以如果能优化IOU就能提高分数啦,那么怎么优化呢?
一般直接使用BCE去训练,但是优化BCE并不等于优化IOU,可以参考 http://cn.arxiv.org/pdf/1705.08790v2,直观上来说一个minibatch中的没有pixel的权重其实是不一样的。两张图片,一张正样本有1000个pixels,另一张只有4个,那么第二张1个pixel带来的IOU得损失就能顶的上第一张中250pixel的损失。
如果直接使用IOU作为Loss Function,也不是最好的,因为训练过程是不稳定的。一个模型从坏到好,我们希望监督它的loss的过渡是平滑的。
所以推荐使用Lovasz-Softmax loss,效果不错,github上有源码。