IntelliJ IDEA搭建Hadoop开发环境
前言
这是关于Hadoop的系列文章。
Hadoop基本概念指南
Eclipse搭建Hadoop开发环境二三事
IntelliJ IDEA搭建Hadoop开发环境
Hadoop文件存储系统-HDFS详解以及java编程实现
准备
事实上,我前面搭建的关于Hadoop的开发环境已经够用了。可是那始终是提交到本地的,任务在本地跑,总让人感觉怪怪的。而且还依赖着HADOOP_HOME这样的环境变量,还得选中依赖的jar包以及依赖所谓的插件。所以我想可不可以用maven来管理我们需要的jar,然后通过一定的设置让我们的任务提交到远程去呢!
我先来说说本次项目的搭建需要依赖的东西:
就只是maven,没错,就只是maven。好了,废话不多说迅速的开始干活!
依赖的jar
这里的话实际上我们只需要依赖hadoop的核心jar包即可。如下所示是我的pom中的全部依赖:
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.6.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.6.1version>
dependency>
<dependency>
<groupId>commons-cligroupId>
<artifactId>commons-cliartifactId>
<version>1.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>2.6.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-jobclientartifactId>
<version>2.6.1version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-examplesartifactId>
<version>2.6.1version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.6version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.8version>
dependency>
dependencies> 之所以要依赖这个examples只是要看Hadoop为我们提供的一些基本的例子,实际上Hadoop为我们提供了非常多的例子,大家只需要搜索最著名的WordCount就可以在同一个包下发现非常丰富的例子,实际上对这些例子只要能熟练的掌握那么就可以很好的掌握基本知识了。毕竟官方的资料才是最好的。
好了,下面我们来看代码,从windows向Hadoop的linux集群提交是有问题的,你上网一搜索,有很多帖子都会说要改什么源代码啊之类的,实际上,在早期的1.X版本确实存在这样的情况。因为那时候的Hadoop从windows向linux提交存在一个bug。而现在,2.X版本已将修复。但是需要额外的设置。好了,我们来一点点的看代码,看和上一篇的代码的不同。我大致分为了两个方面:
第一个方面就是说我们要将我们集群的配置文件设置到这里来,这是非常重要的,实际上如果你通过断点调试就会发现,Hadoop为我们设置了默认的配置文件。如下图:
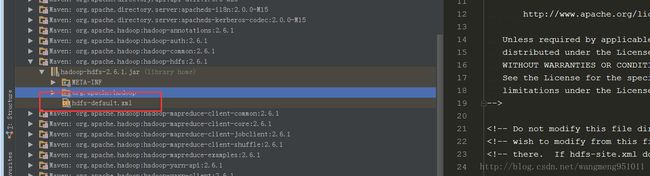
我们可以看到,在jar包里面就有,实际上对应的四个配置文件都有的。所以说当你不做任何事情的时候,当然是按照人家的来喽!结果就是任务提交到本地。当然,我们可以自己设置,设置如下:
private static void setProties(JobConf conf) throws FileNotFoundException {
conf.addResource("/core-site.xml");
conf.addResource("/hdfs-site.xml");
conf.addResource("/mapred-site.xml");
conf.addResource("/yarn-site.xml");
}有了上面的设置,我们就可以提交到远程linux了吗?当然不行。下面进入第二步,设置一些其他的参数,我前面有讲到过,跨平台提交在1.x版本是一个bug,而后修复,但是需要通过配置的方式才可以正常提交。配置如下:
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.job.ubertask.enable", "true");
conf.setUser("hadoop");
conf.set("mapreduce.job.jar", "E:\\github\\hadoop\\target\\fulei-1.0-SNAPSHOT.jar"); 我们可以很清晰的看出来,第一个设置的参数cross-platform明显就是跨平台的意思啊,阿偶!当然后面的设置jar包也非常重要,因为你要提交任务到远端,所以必须制定本地jar的位置,啊哈!这样的话,我们快就可以提交任务到远端了。当然,这里的远端大部分时候指的还是我们的虚拟机而已。当然,如果你有云服务器的,就更好了。啊哈!
当然,我们还需要在marped-site.xml配置如下内容,这是我从默认的配置文件中摘出来的。
<property>
<description>If enabled, user can submit an application cross-platform
i.e. submit an application from a Windows client to a Linux/Unix server or
vice versa.
description>
<name>mapreduce.app-submission.cross-platformname>
<value>falsevalue>
property>
<property>
<description>CLASSPATH for MR applications. A comma-separated list
of CLASSPATH entries. If mapreduce.application.framework is set then this
must specify the appropriate classpath for that archive, and the name of
the archive must be present in the classpath.
If mapreduce.app-submission.cross-platform is false, platform-specific
environment vairable expansion syntax would be used to construct the default
CLASSPATH entries.
For Linux:
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*.
For Windows:
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*.
If mapreduce.app-submission.cross-platform is true, platform-agnostic default
CLASSPATH for MR applications would be used:
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/*,
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/lib/*
Parameter expansion marker will be replaced by NodeManager on container
launch based on the underlying OS accordingly.
description>
<name>mapreduce.application.classpathname>
<value>value>
property> 这个上面已经说得非常明白,如果设置了cross-platform的话,就要设值集群上的jar的位置,否则Hadoop在提交任务后会报Classnotfound的问题。到了这里,我们可以说已经配置完了。
我们现在来看看运行的效果如何:
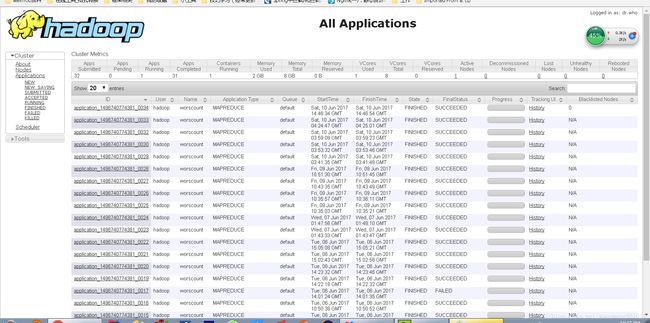
任务已经成功的运行,好了,我们现在就可以使用这一个项目随处运行了,再也不用担心环境问题了。哈哈
总结
阿福才疏学浅,可能有说的不够到位的地方,希望大家看出指正!
到了这里我们的环境基本上来说就可以确定就用这一套东西了,接下来就是mr的处理详解了。下一篇讲给大家带来mr的处理流程。
好了,各位晚安!有什么不懂的欢迎在评论区提问啊!