WebCollector 页面附件信息 metaData 与 MatchType
目录
本文导读
MetaData 概述
MatchType 概述
爬取豆瓣评分
需求分析
标签页
列表页
内容页
代码实现
爬取结果
本文导读
1、本文学习 webCollector 官网的 DemoMetaCrawler 示例,这个例子可以在开发包 cn.edu.hfut.dmic.webcollector.example m=目录下找到
2、《WebCollector 自动探测 URL 地址》中的例子就是通过正则表达式的方式来过滤需要的网址,从而获得需要的内容,对于一个复杂的网站(例如层级较深、页面URL类型多样,抓取搜索引擎等),虽然用多个正则表达式也能匹配过滤出来,但是此时使用 MetaData 确实更加明智的选择。《WebCollector 自动探测 URL 地址》中正则表达式匹配当前 URL 的方式如下:
@Override
public void visit(Page page, CrawlDatums next) {
//如果是博客内容页(根据URL正则判断),则获取它的内容,否则不做处理
if (page.matchUrl("http://blog.csdn.net/.*/article/details/.*")) {
//抽取代码
}
}
MetaData 概述
1、WebCollector 的 MetaData 是提升爬虫开发效率最好的特性之一,MetaData 特别适合复杂爬取任务的开发。
2、例如当爬虫需要解析多种异构页面时,可通过 MetaData 功能为每个页面标注类别。网页的类别往往在网页被探测到时容易获取,在解析时难以获取,而 MetaData 正好提供了在探测网页时为网页标注类别的功能。
3、例如抓取电商网站,电商入口页的左栏是热销商品链接,右栏是热门店家信息,在解析首页时,就可以利用 MetaData 特性将左栏中探测到的 URL 标上” kind ”:”商品”,将右栏中探测到的URL标上”kind”:”店家”,将它们一起放入后续任务(next)中。当爬虫成功获取商品或店家页面的源码并将其交给解析程序时,开发者可以直接通过 page.meta("kind") 来获取页面的类型,而不需要通过 UR L的正则匹配等方法来处理该问题,且很多场景中,一些异构页面的 URL 利用正则难以区分。
MatchType 概述
1、MetaData 特性使得 WebCollector 在注入或探测链接时为其添加附属信息,提升开发效率,在附属信息中,页面类型信息是一个及其重要的信息。这里所说的页面类型不是 Http 协议中的 Content-Type 信息,而是用户自定义的用于区分不同解析方案的信息,例如在采集豆瓣图书时,会遇到标签页、列表页和图书详情页,只有知道页面的类型,才可以选取对应的抽取及新链接探测方案。
2、大多数 Java 爬虫都会通过网页 URL 的正则匹配来判断页面类型(如《WebCollector 自动探测 URL 地址》),但正则匹配并不能解决所有的问题,对于一些网站,可能不同类型的页面享有相同的 URL 模式。
3、本文将会以爬取 豆瓣读书 为例进行详细说明,当设计豆瓣图书爬虫时(手动解析),有如下的关系:
A.注入种子页(标签页)
B.从标签页中解析获得列表页的 URL
C.从列表页中解析获得内容页的 URL
4、与其根据 URL 正则获得页面的类型,倒不如直接在上述A(注入)、B(探测)、C(再探测)时直接将页面类型标记在链接(CrawlDatum)中,在新版本 WebCollector 中,可通过如下几种形式为链接(CrawlDatum)添加 MetaData 信息:
1、CrawlDatum datum = new CrawlDatum("网页URL", "页面类型");
2、CrawlDatum datum = new CrawlDatum("网页URL").type("页面类型");
3、在 Crawler 中注入时:addSeed("网页URL", "页面类型");
4、在visit中往 next 中添加探测到的链接时:next.add("网页URL", "页面类型");5、在解析时,可直接通过 page.matchType("页面类型") 来判断网页是否符合指定的页面类型。
6、注意:页面类型信息本质是 MetaData 中一个 key 为 ”type” 的附属信息,建议开发者在使用 MetaData 特性时不要将自定义的附属信息的 key 设置为 ”type”,以免发生冲突。(意思就是 webCollector 已经内置了一个 key 为 type,程序员可以自己直接赋值取值)
7、matchType 可以参考官网例子 DemoTypeCrawler,位于 cn.edu.hfut.dmic.webcollector.example.DemoTypeCrawler。
爬取豆瓣评分
需求分析
标签页
1、爬取豆瓣读书 的 图书 名称 以及 评分,标签页地址:https://book.douban.com/tag/?view=type&icn=index-sorttags-all
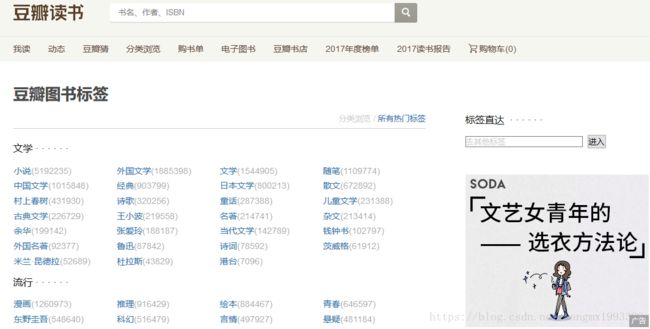
如下所示是 标签页右击查看源码的部分内容,重点是它的 小说名 超链接地址 规则
......
文学 · · · · · ·
小说(5192235)
外国文学(1885398)
文学(1544905)
随笔(1109774)
中国文学(1015848)
经典(903799)
日本文学(800213)
散文(672892)
村上春树(431930)
诗歌(320256)
童话(287388)
儿童文学(231388)
古典文学(226729)
王小波(219558)
名著(214741)
杂文(213414)
余华(199142)
张爱玲(188187)
当代文学(142789)
钱钟书(102797)
外国名著(92377)
.....
列表页
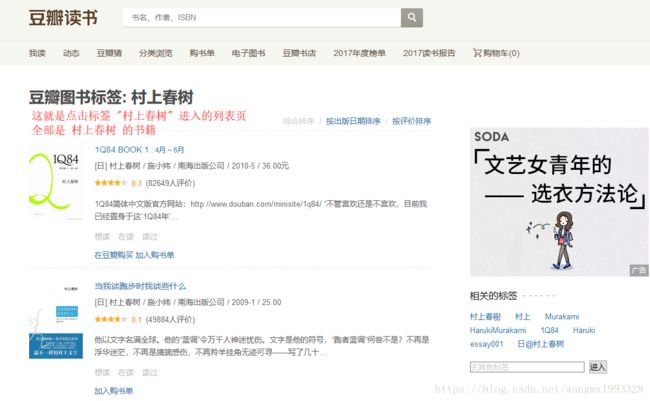
如下所示为 列表页的部分源码,重点是 超链接的规则

当我谈跑步时我谈些什么
[日] 村上春树 / 施小炜 / 南海出版公司 / 2009-1 / 25.00
(49884人评价)
他以文字名满全球。他的“蓝调”令万千人神迷忧伤。文字是他的符号,“跑者蓝调”何尝不是?不再是浮华迷茫,不再是旖旎感伤,不再羚羊挂角无迹可寻——写了几十...
内容页


代码实现
提示:爬取豆瓣时,豆瓣服务器有简单的反爬取机制,当短时间内请求次数超出人为的正常值时,对方会拒绝处理请求返回403错误。
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.ram.RamCrawler;
/**
* WebCollector 2.x 版本的 tutorial(教程) (2.20以上)
* 2.x版本特性:
* 1)自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
* 2)可以为每个URL设置附加信息( MetaData ),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST参数传递、增量更新等。
* 3)使用插件机制,WebCollector内置两套插件。
* 4)内置一套基于内存的插件(RamCrawler<内存爬虫>),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
* 5)内置一套基于 Berkeley DB(BreadthCrawler<广度爬虫>)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
* 6)集成 selenium,可以对 javascript 生成信息进行抽取
* 7)可轻松自定义 http 请求,并内置多代理随机切换功能。 可通过定义 http 请求实现模拟登录。
* 8)使用 slf4j 作为日志门面,可对接多种日志
*
* 可在 cn.edu.hfut.dmic.webcollector.example 包中找到例子(Demo)
*
* @author hu
*/
public class DemoMetaCrawler extends RamCrawler {
/** 为指定 autoParse 参数时,父类默认为 true ,即会自动解析页面中的所有超链接
*因为没有使用 crawler.addRegex() 正则匹配,所以 为 true 也不会影响,等同于手动*/
/**
* 实际使用时建议按照 DemoTypeCrawler 的方式操作,该教程目的为阐述 meta 的原理
*
* 可以往 CrawlDatums 中添加希望后续爬取的任务,任务可以是 URL 或者 CrawlDatum
* 爬虫不会重复爬取任务,从 2.20 版之后,爬虫根据 CrawlDatum 的 key 去重,而不是URL
* 因此如果希望重复爬取某个URL,只要将 CrawlDatum 的 key 设置为一个历史中不存在的值即可
* 例如增量爬取,可以使用 爬取时间+URL作为key。
*
* 新版本中,可以直接通过 page.select(css选择器)方法来抽取网页中的信息,等价于
* page.getDoc().select(css选择器)方法,page.getDoc()获取到的是Jsoup中的
* Document对象,细节请参考Jsoup教程
*
*/
@Override
public void visit(Page page, CrawlDatums next) {
/** 获取页面类型
* page 既能为当前爬取页面存放 meta 信息
* 也能获取当前页面的 meta 信息(底层就是:crawlDatum.meta(key))
* 注意值不存在时 返回 null
* */
String type = page.meta("type");
System.out.println("页面类型:" + type);
if (type.equals("taglist")) {
/**如果是标签页,则抽取其中的列表页链接,放入后续任务中
* 同时为这些新链接添加附加信息(meta):type=booklist
* 因为使用的是 page.links("table.tagCol td>a") 精确匹配所有列表页链接地址,所以直接添加附加信息
*
* */
next.addAndReturn(page.links("table.tagCol td>a")).meta("type", "booklist");
} else if (type.equals("booklist")) {
/**
* 如果是列表页,则抽取其中的内容页链接,放入后续任务中
* 同时为这些链接添加附加信息(meta):type=content,key 和value 都是自定义即可
* 精确匹配超链接
*/
next.addAndReturn(page.links("div.info>h2>a")).meta("type", "content");
} else if (type.equals("content")) {
/**
* 处理内容页,抽取书名和豆瓣评分
*/
String title = page.select("h1>span").first().text();
String score = page.select("strong.ll.rating_num").first().text();
System.out.println("书名:" + title + " >>>评分:" + score);
}
}
/**
* 该 Demo 爬虫需要应对豆瓣图书的三种页面:
* 1)标签页(taglist,包含图书列表页的入口链接)
* 2)列表页(booklist,包含图书详情页的入口链接)
* 3)图书详情页(content)
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
/** 为指定 autoParse 参数时,父类默认为 true ,即会自动解析页面中的所有超链接
*因为没有使用 crawler.addRegex() 正则匹配,所以 为 true 也不会影响,等同于手动*/
DemoMetaCrawler crawler = new DemoMetaCrawler();
/**
* meta 是 CrawlDatum 的附加信息,爬虫内核并不使用 meta 信息
* 在解析页面时,往往需要知道当前页面的类型(例如是标签页、列表页、内容页)或一些附加信息(例如页号)
* 然而根据当前页面的信息(内容和URL)并不一定能够轻易得到这些信息
* 例如当在解析页面 https://book.douban.com/tag/ 时,需要知道该页是目录页还是内容页
* 虽然用正则也可以解决这个问题,但是相比之下使用 meta 会更加快捷
* 当我们将一个新链接(CrawlDatum)提交给爬虫时,链接指向页面的类型有时是确定的(例如在很多任务中,种子页面就是列表页)
* 如果在提交CrawlDatum时,直接将链接的类型信息(type)存放到meta中,那么在解析页面时,
* 只需取出链接(CrawlDatum)中的类型信息(type)即可知道当前页面类型
*/
CrawlDatum seed = new CrawlDatum("https://book.douban.com/tag/").meta("type", "taglist");
crawler.addSeed(seed);
crawler.setThreads(30);
crawler.start(3);
}
}
爬取结果
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 1
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - start merge
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge fetch database
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge link database
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - end merge
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - init segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.ram.RamDBManager
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - create generator:cn.edu.hfut.dmic.webcollector.plugin.ram.RamGenerator
2018-08-17 10:34:21 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - use generatorFilter:cn.edu.hfut.dmic.webcollector.crawldb.StatusGeneratorFilter
页面类型:taglist
2018-08-17 10:34:22 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=1, spinWaiting=0, fetchQueue.size=0
2018-08-17 10:34:22 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/ (URL: https://book.douban.com/tag/)
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=0, spinWaiting=0, fetchQueue.size=0
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - depth 1 finish:
total urls: 1
total time: 2 seconds
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 2
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - start merge
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge fetch database
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge link database
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - end merge
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - init segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.ram.RamDBManager
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - create generator:cn.edu.hfut.dmic.webcollector.plugin.ram.RamGenerator
2018-08-17 10:34:23 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - use generatorFilter:cn.edu.hfut.dmic.webcollector.crawldb.StatusGeneratorFilter
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/张小娴 (URL: https://book.douban.com/tag/张小娴)
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/中国历史 (URL: https://book.douban.com/tag/中国历史)
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/散文 (URL: https://book.douban.com/tag/散文)
页面类型:booklist
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/成长 (URL: https://book.douban.com/tag/成长)
页面类型:booklist
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/营销 (URL: https://book.douban.com/tag/营销)
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/经典 (URL: https://book.douban.com/tag/经典)
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/策划 (URL: https://book.douban.com/tag/策划)
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/管理 (URL: https://book.douban.com/tag/管理)
页面类型:booklist
2018-08-17 10:34:24 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/tag/交互 (URL: https://book.douban.com/tag/交互)
页面类型:booklist
.......省略几百行......
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - depth 2 finish:
total urls: 145
total time: 12 seconds
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 3
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - start merge
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge fetch database
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - merge link database
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.crawldb.DBManager - end merge
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - init segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.ram.RamDBManager
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - create generator:cn.edu.hfut.dmic.webcollector.plugin.ram.RamGenerator
2018-08-17 10:34:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - use generatorFilter:cn.edu.hfut.dmic.webcollector.crawldb.StatusGeneratorFilter
页面类型:content
书名:不疯魔不成活 >>>评分:9.0
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/27072051/ (URL: https://book.douban.com/subject/27072051/)
页面类型:content
书名:这就是二十四节气 >>>评分:8.6
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/26738072/ (URL: https://book.douban.com/subject/26738072/)
页面类型:content
书名:宗子维城 >>>评分:8.8
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/27054319/ (URL: https://book.douban.com/subject/27054319/)
页面类型:content
书名:新参者 >>>评分:8.4
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/6746289/ (URL: https://book.douban.com/subject/6746289/)
页面类型:content
书名:性别战争 >>>评分:8.0
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/4846032/ (URL: https://book.douban.com/subject/4846032/)
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=30, spinWaiting=0, fetchQueue.size=970
页面类型:content
书名:诗的八堂课 >>>评分:8.3
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/26893046/ (URL: https://book.douban.com/subject/26893046/)
页面类型:content
书名:从历史中醒来 >>>评分:9.1
2018-08-17 10:34:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/26848651/ (URL: https://book.douban.com/subject/26848651/)
.......省略几千行......
页面类型:content
书名:东霓 >>>评分:8.1
2018-08-17 10:36:01 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://book.douban.com/subject/4874131/ (URL: https://book.douban.com/subject/4874131/)
2018-08-17 10:36:02 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=0, spinWaiting=0, fetchQueue.size=0
2018-08-17 10:36:02 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - clear all activeThread
2018-08-17 10:36:02 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - close generator:cn.edu.hfut.dmic.webcollector.plugin.ram.RamGenerator
2018-08-17 10:36:02 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - close segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.ram.RamDBManager
2018-08-17 10:36:02 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - depth 3 finish:
total urls: 2023
total time: 87 seconds
Process finished with exit code 0
你可能感兴趣的:(WebCollector)