Java爬虫-WebCollector爬虫Demo微讲解
Java爬虫-WebCollector爬虫Demo微讲解
工作三年,第一次有时间并且有兴致写博客,文笔可能不太好并且个人是个青铜级别开发,有错误的地方请及时帮忙纠正一下,谢谢。
首先贴个WebCollector的开源地址:链接: https://github.com/CrawlScript/WebCollector.
关于WebCollector,我就不多做介绍了,百度一大堆,下面推荐一下写的比较全的:
链接: https://blog.csdn.net/wangmx1993328/article/details/81662001.(转)
链接: https://www.oschina.net/p/webcollector.(转)
开发文档
由于WebCollector的开发文档是打不开的(不知道是不是我的打开方式不对),所以用的时候都是靠自己一路摸索,看源码用的。后面如果有人有开发文档的话,麻烦给我发一份,谢谢。
个人理解版(可以先往下看,开发不懂时再看回来):
1.爬虫网站指定:addSeed();addSeedAndReturn();
2.网页重新指向:page.links();(自带有a标签href的读取,要读取src时需要第二入参)
/**
* 获取满足选择器的元素中的链接 选择器cssSelector必须定位到具体的超链接 例如我们想抽取id为content的div中的所有超链接,这里
* 就要将cssSelector定义为div[id=content] a
*
* @param cssSelector
* @return
*/
public Links links(String cssSelector, boolean parseSrc) {
Links links = new Links().addBySelector(doc(), cssSelector,parseSrc);
return links;
}
public Links links(String cssSelector) {
return links(cssSelector,false);
}
/**
* 添加ele中,满足选择器的元素中的链接 选择器cssSelector必须定位到具体的超链接
* 例如我们想抽取id为content的div中的所有超链接,这里 就要将cssSelector定义为div[id=content] a
*
*/
public Links addBySelector(Element ele, String cssSelector, boolean parseSrc) {
Elements as = ele.select(cssSelector);
for (Element a : as) {
if (a.hasAttr("href")) {
String href = a.attr("abs:href");
this.add(href);
}
if(parseSrc){
if(a.hasAttr("src")){
String src = a.attr("abs:src");
this.add(src);
}
}
}
return this;
}
3.下一个深度跳转:next.add();(这个需要深度设置为 >1)
4.页面元素取值:page.selectText();(参数为CSS选择器)
CSS选择器链接: https://www.w3school.com.cn/cssref/css_selectors.ASP.
5.各种页面数据获取方法:
public ArrayList<String> selectTextList(String cssSelector){
ArrayList<String> result = new ArrayList<String>();
Elements eles = select(cssSelector);
for(Element ele:eles){
result.add(ele.text());
}
return result;
}
public String selectText(String cssSelector, int index){
return ListUtils.getByIndex(selectTextList(cssSelector),index);
}
public String selectText(String cssSelector) {
return select(cssSelector).first().text();
}
6.Page.html,Page.doc:记录了页面的静态资源,当你在F12查看元素时看到元素,而CSS选择器选择不到(报空指针)时,可以Debug查看一下这两个参数。
进入正题
首先我们得从git上拿去源码,当然你也可以maven直接添加,因为是Demo,我就直接从上面拿了
maven添加方式:
<dependency>
<groupId>cn.edu.hfut.dmic.webcollector</groupId>
<artifactId>WebCollector</artifactId>
<version>2.73-alpha</version>
</dependency>
git拿(还不会git的,请自行百度):

拿到后,我们可以看到已经有很多的Demo了,下面解释一下这些Demo都是用来干嘛的
1.AbuyunDynamicProxyRequester:WebCollector使用阿布云代理的Http请求插件,就是一个代理的使用Demo,因为现在有很多网站已经有防爬虫的机制,所以我们后面爬豆瓣时,我们也会用到代理去爬(如果不用的话,好像一天只能爬200条左右,登陆后是500条左右)。
这里需要特别说明一下,因为git上面的代码比较老了,阿布云已经更新了,所以代码需要稍作修改才可以跑起来(大学老师说:没有任何代码是拿过来就可以跑的,别人给你的代码总是有坑的)
阿布云接入说明链接: https://www.abuyun.com/http-proxy/dyn-manual.html.
根据说明我将代理的地址改了:
// String proxyHost = "proxy.abuyun.com";
String proxyHost = "http-dyn.abuyun.com";
另外说明一下username和password是申请的密钥(在阿布云注册一下,然后申请可以免费使用):
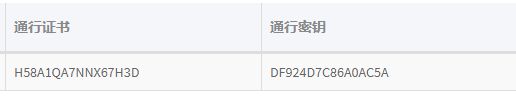
final String username = "H58A1QA7NNX67H3D";
final String password = "DF924D7C86A0AC5A";
AbuyunDynamicProxyRequester requester = new AbuyunDynamicProxyRequester(username, password);
Annotated是下面Demo的一个升级版,主要是后面作者把一些常用的方法进行了丰富以及封装,使用标签去替代一些又长又臭的代码。
2.DemoAnnotatedAutoNewsCrawler(DemoAutoNewsCrawler):github博客新闻的爬取,主要是想讲解一下addRegex的使用,例子比较简单可以参考
/**
* 添加URL正则约束
*
* @param urlRegex URL正则约束
*/
public void addRegex(String urlRegex) {
regexRule.addRule(urlRegex);
}
3.DemoAnnotatedBingCrawler(DemoBingCrawler):实现了一个爬取Bing搜索前n页结果的爬虫,爬虫的结果直接输出到标准输出流。
搜索器的爬虫Demo,有空可以改了爬一下百度、搜狗,Google等
4.DemoAnnotatedDepthCrawler:Demo为深度爬虫的展示,一些爬取需求希望加入深度信息,即遍历树中网页的层。(深度是好东西)
5.DemoAnnotatedMatchTypeCrawler:Demo为豆瓣图书的爬取,从第一页爬到第三页,第一页为:https://book.douban.com/tag/,自己可以打开看看,结合代码大概就会懂了。
public DemoAnnotatedMatchTypeCrawler(){
//meta是CrawlDatum的附加信息,爬虫内核并不使用meta信息
//在解析页面时,往往需要知道当前页面的类型(例如是列表页还是内容页)或一些附加信息(例如页号)
//然而根据当前页面的信息(内容和URL)并不一定能够轻易得到这些信息
//例如当在解析页面 https://book.douban.com/tag/ 时,需要知道该页是目录页还是内容页
//虽然用正则可以解决这个问题,但是较为麻烦
//当我们将一个新链接(CrawlDatum)提交给爬虫时,链接指向页面的类型有时是确定的(例如在很多任务中,种子页面就是列表页)
//如果在提交CrawlDatum时,直接将链接的类型信息(type)存放到meta中,那么在解析页面时,
//只需取出链接(CrawlDatum)中的类型信息(type)即可知道当前页面类型
addSeedAndReturn("https://book.douban.com/tag/").type("taglist");
/*可以设置每个线程visit的间隔,这里是毫秒*/
getConf().setExecuteInterval(1000);
/*设置线程数*/
setThreads(30);
}
@MatchType(types = "taglist")
public void visitTagList(Page page, CrawlDatums next) {
//可以确定抽取到的链接都指向内容页
//因此为这些链接添加附加信息(meta):type=content
next.addAndReturn(page.links("table.tagCol td>a")).type("booklist");
}
@MatchType(types = "booklist")
public void visitBookList(Page page, CrawlDatums next) {
next.addAndReturn(page.links("div.info>h2>a")).type("content");
}
@MatchType(types = "content")
public void visitContent(Page page, CrawlDatums next) {
//处理内容页,抽取书名和豆瓣评分
String title=page.select("h1>span").first().text();
String score=page.select("strong.ll.rating_num").first().text();
System.out.println("title:"+title+"\tscore:"+score);
}
6.DemoAnnotatedRedirectCrawler:页面重定向Demo,当遇到响应代码为301, 302时,就会爬去新的地址。

7.DemoPostCrawler:post和get的爬虫Demo,有部分网站由于是异步加载的,如果好像上面那些直接爬指定元素的话,是获取不到的,所以这时候直接爬网络请求会比较好。
/**
*
* 假设我们要爬取三个链接 1)http://www.A.com/index.php 需要POST,并需要POST表单数据username:John
* 2)http://www.B.com/index.php?age=10 需要POST,数据直接在URL中 ,不需要附带数据 3)http://www.C.com/
* 需要GET
*/
public DemoPostCrawler(final String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
addSeed(new CrawlDatum("http://www.A.com/index.php")
.meta("method", "POST")
.meta("username", "John"));
addSeed(new CrawlDatum("http://www.B.com/index.php")
.meta("method", "POST"));
addSeed(new CrawlDatum("http://www.C.com/index.php")
.meta("method", "GET"));
setRequester(new OkHttpRequester(){
@Override
public Request.Builder createRequestBuilder(CrawlDatum crawlDatum) {
Request.Builder requestBuilder = super.createRequestBuilder(crawlDatum);
String method = crawlDatum.meta("method");
// 默认就是GET方式,直接返回原来的即可
if(method.equals("GET")){
return requestBuilder;
}
if(method.equals("POST")){
RequestBody requestBody;
String username = crawlDatum.meta("username");
// 如果没有表单数据username,POST的数据直接在URL中
if(username == null){
requestBody = RequestBody.create(null, new byte[]{});
}else{
// 根据meta构建POST表单数据
requestBody = new MultipartBody.Builder()
.setType(MultipartBody.FORM)
.addFormDataPart("username", username)
.build();
}
return requestBuilder.post(requestBody);
}
//执行这句会抛出异常
ExceptionUtils.fail("wrong method: " + method);
return null;
}
});
}
还有很多,我也没看完,后续继续补充。