Deeplearning4j 实战 (10):迁移学习--ImageNet比赛预训练网络VGG16分类花卉图片
Eclipse Deeplearning4j GitChat课程:https://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f
Eclipse Deeplearning4j 系列博客:https://blog.csdn.net/wangongxi
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
在最新发布的Deeplearning4j 0.8.0的版本中,开始支持深度神经网络的迁移学习模型。严格来说,这种迁移的方式是一种模型迁移。在具体操作的时候,将一个预先训练好的神经网络,用新数据集重新训练网络中的一小部分,从而完成在新数据集上建立的算法任务,即完成了神经网络的迁移学习。在给出具体的案例之前,先简单讨论下迁移学习的相关内容。
迁移学习是被认为可以解决标注数据不足的情况下训练模型的问题。举监督学习的例子,大量标注数据的收集是训练模型的必要条件。如果标注数据不足或质量不高,那模型的泛化能力会大大下降,原因就在于标注数据的缺失将无法刻画数据在特征空间的分布情况,不准确的分布自然难以拟合测试数据,预测就不准确了。但很多时候,标注数据本身确实很难大量获得,那么是否有其他办法来解决这种情况下模型泛化能力的问题呢?其中一个可行的方法就是利用迁移学习。试想一下,如果两个任务的情形比较类似,比如,一个是做各种猫的图片分类,另一个是做各种猎豹的图片分类,由于这两种动物都是猫科动物,很多特征比如眼睛、胡须、牙齿等都比较相似,所以可以考虑用已经训练好的分类各种猫的模型,在用少量猎豹的数据重新训练网络的部分参数后,来分类猎豹。如果用的是卷积神经网络的话,比如,AlexNet,VGG等,那么前几层的卷积+池化层就可以认为是提取猫科动物共同特征的,后几层全连阶层用于提取各自任务中的不同特征来分类。当然这样的描述未必准确,但迁移学习的思想可以从这个例子中做些类比。
那么迁移学习有什么缺点呢?其实任务迁移的假设、迁移的效果都很难保证。比如,很多情况下,两个任务之间是否相似,是否可以迁移,这个在理论上比较难界定。还有就是,负迁移的情况时有发生。也就是说,迁移以后算法效果反而变差了。这些问题有一些研究成果,但在实际生产环境中,还是比较难解决。
更多的迁移学习的资料,可以参考杨强教授的个人主页:http://www.cse.ust.hk/~qyang/
tutorial/survey性质的文章就可以参考杨强教授的文章:《A Survey on Transfer Learning》。
下面就在最新版本Deeplearning4j的基础上,给出一个迁移学习的例子作为入门之用。例子的主要内容是将ImageNet数据集训练的分类模型VGG16,迁移到几种花卉图片的分类问题中。ImageNet数据集中共有~1000类的图片集,涵盖了动物、植物、物品等图片。这里,VGG16的模型是事先用Keras训练好的。我们要做的事情,就是在该模型的基础上,用新任务中的花卉图片重新训练网络的一小部分,从而迁移到新的任务上。这里,对重新训练网络的一部分做些解释:
1. 可以将网络中的若干层神经元连接权重重新训练
2. 可以将网络中的若干层直接移除,添加新的网络层,从而重新训练这个新添加的网络层
这就是基于神经网络的迁移学习的一些可行的做法。下面就结合之前说的这两种策略,给出基于Deeplearning4j的实现代码:
首先给出第一种策略的代码实现逻辑:
FineTuneConfiguration fineTuneConf = new FineTuneConfiguration.Builder()
.learningRate(3e-5)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.ADAM)
.seed(seed)
.build();
//Construct a new model with the intended architecture and print summary
ComputationGraph vgg16Transfer = new TransferLearning.GraphBuilder(vgg16)
.fineTuneConfiguration(fineTuneConf)
.setFeatureExtractor(featureExtractionLayer) //the specified layer and below are "frozen"
.removeVertexKeepConnections("predictions") //replace the functionality of the final vertex
.addLayer("predictions",new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nIn(4096).nOut(numClasses)
.weightInit(WeightInit.DISTRIBUTION)
.dist(new NormalDistribution(0,0.2*(2.0/(4096+numClasses)))) //This weight init dist gave better results than Xavier
.activation(Activation.SOFTMAX).build(), "fc2")
.build();
System.out.println(vgg16Transfer.summary());这里简单解释下代码。FineTuneConfiguration是定义重新训练的一些参数,和训练整个网络的参数类似。TransferLearning是迁移学习的主要类。removeVertexKeepConnections的作用是保证网络结构,但是那一层的网络权重要重新训练。setFeatureExtractor的作用是做迁移学习的时候,冻结部分网络参数。之后打印出网络的结构就一目了然了:

从图片中我们看出,setFeatureExtractor设置的参数冻结了包括fc2往下的所有网络层,即这部分网络连接的权重参数在迁移学习训练的过程中保持不变,即所谓的frozen(图片中绿框圈出的部分)。而removeVertexKeepConnections的设置保证了fc2这一层和predictions的连接保持不变,即keep connection。因此,可训练的参数的数量,就是4096*5+5=20485个。其中,5是最后分类的花卉的品种数量,也是bias的数量。以上就是Deeplearning4j提供的第一种迁移学习的策略,保持新添加层和之前网络层的连接的前提下,根据任务要求重新训练部分网络参数。下面介绍第二种迁移学习的策略:整个移除网络层,不保留该层和之前的连接。代码如下:
FineTuneConfiguration fineTuneConf = new FineTuneConfiguration.Builder()
.activation(Activation.LEAKYRELU)
.weightInit(WeightInit.RELU)
.learningRate(5e-5)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS)
.dropOut(0.5)
.seed(seed)
.build();
//Construct a new model with the intended architecture and print summary
// Note: This architecture is constructed with the primary intent of demonstrating use of the transfer learning API,
// secondary to what might give better results
ComputationGraph vgg16Transfer = new TransferLearning.GraphBuilder(vgg16)
.fineTuneConfiguration(fineTuneConf)
.setFeatureExtractor(featureExtractionLayer) //"block5_pool" and below are frozen
.nOutReplace("fc2",1024, WeightInit.XAVIER) //modify nOut of the "fc2" vertex
.removeVertexAndConnections("predictions") //remove the final vertex and it's connections
.addLayer("fc3",new DenseLayer.Builder().activation(Activation.TANH).nIn(1024).nOut(256).build(),"fc2") //add in a new dense layer
.addLayer("newpredictions",new OutputLayer
.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(256)
.nOut(numClasses)
.build(),"fc3") //add in a final output dense layer,
// note that learning related configurations applied on a new layer here will be honored
// In other words - these will override the finetune confs.
// For eg. activation function will be softmax not RELU
.setOutputs("newpredictions") //since we removed the output vertex and it's connections we need to specify outputs for the graph
.build();
log.info(vgg16Transfer.summary());
从图中可以看出,可第一种策略不同的是,这一种策略添加了fc3这一层,并且与fc2连接的权重重新训练,相当于完全移除了fc2这一层。因此可以重新训练的参数的数量也就变成了最后三层全连阶层+输出层。
以上即为Deeplearning4j现在已经实现了的在深度学习基础上对迁移学习的支持。
在这里,我们的任务是将ImageNet比赛数据训练好的VGG16模型迁移到5中花卉的训练问题上。这五种花卉的训练数据集的地址: http://download.tensorflow.org/example_images/flower_photos.tgz
模型的导入,直接调用Deeplearning4j中Keras模型的导入接口就行了:
ComputationGraph vgg16 = KerasModelImport.importKerasModelAndWeights("/home/wangongxi/transferlearning/VGG16.json", "/home/wangongxi/transferlearning/vgg16_weights_th_dim_ordering_th_kernels.h5", false);
VGG16模型的下载地址为:
https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_th_dim_ordering_th_kernels.h5
https://raw.githubusercontent.com/deeplearning4j/dl4j-examples/f9da30063c1636e1de515f2ac514e9a45c1b32cd/dl4j-examples/src/main/resources/trainedModels/VGG16.json
最后,再给出图片读取和模型训练以及评估的代码逻辑。这一部分和之前博客的内容非常相似,所以就不再做过多的解释了。
FlowerDataSetIterator.setup(batchSize,trainPerc);
DataSetIterator trainIter = FlowerDataSetIterator.trainIterator();
DataSetIterator testIter = FlowerDataSetIterator.testIterator();
Evaluation eval;
eval = vgg16Transfer.evaluate(testIter);
System.out.println("Eval stats BEFORE fit.....");
System.out.println(eval.stats() + "\n");
testIter.reset();
System.out.println("Start Training");
//
final int numEpoch = Integer.parseInt(args[0]);
for( int i = 0; i < numEpoch; ++i ){
vgg16Transfer.fit(trainIter);
System.out.println("Evaluate model at epoch "+ i + " ....");
eval = vgg16Transfer.evaluate(testIter);
System.out.println(eval.stats());
testIter.reset();
}
System.out.println("Model build complete");
FlowerDataSetIterator是可以读取这些花卉图片的的迭代器包装类。trainPerc是训练数据和测试数据的比例。后面就是模型训练和评估的代码了。我们直接来看下50轮左右训练的结果:
策略一:

策略二:
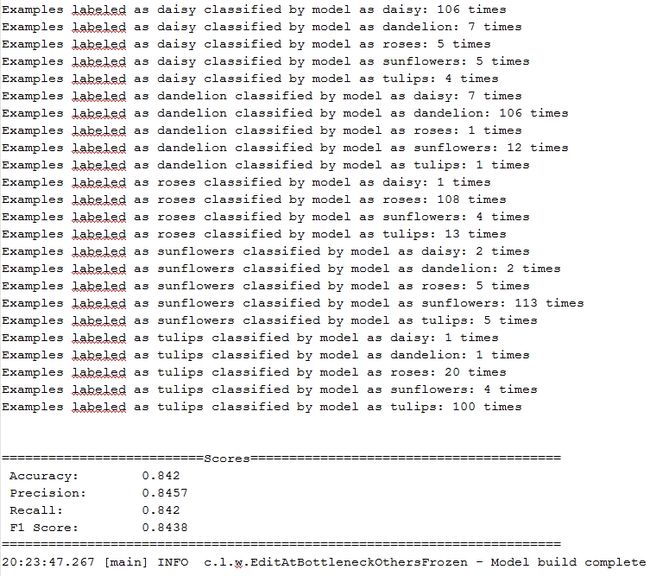
可以看到,两种迁移的策略最后可以达到的准确率也就在85%左右,不算非常高。不过这里面原因也是多方面的,比如这些花本身就比较容易混淆(至少我本人不太善于辨别这些花卉),还有就是我们这些迁移学习的工作都放在的全连接层上面,如果适当重新训练下卷积层+池化层,也许效果还会更好,这些个工作都留待后续去完成。最后,还要说明的一点是,本次迁移学习的模型训练全部在GPU上完成,使用的公司的单机4卡的K80机器完成的。我只用了K80单核心来完成,并没有配置并行训练。训练的时长大概在1天左右。GPU的代码这里就不给出了,和我之前专门写的一篇关于Deeplearning4j+GPU的博客里的内容是类似的。
最后做下简单点的总结。这里主要讲了迁移学习在Deeplearning4j中的应用。从根本上来将,神经网络的迁移学习主要在于固定某些层已经事先训练好的参数,然后,利用新的数据重新训练部分新的网络连接权重。由于不是训练整个网络,因此训练的参数数量大大减少了。当然迁移学习不一定是基于神经网络的,其他传统模型经过适当改造也可以适应迁移学习的要求。最后需要再次指出的是,迁移训练本身的效果一般不会比用训练数据重新训练整个网络来得好,尤其是在两个算法任务不相似的情况下,这个情况更容易出现。但在没有条件训练大网络的情况下,用迁移学习的思想调优部分参数还是非常有价值的!