Azkaban三种模式部署
简介
Azkaban是LinkedIn开源的任务调度框架,类似于JavaEE中的JBPM和Activiti工作流框架。
如ETL的过程,Sqoop在凌晨1点从RDBMS中抽取数据(E),在凌晨2点用Hadoop或Spark转换数据(T),在凌晨3点用Sqoop再把结果数据加载(L)进RDBMS或NOSQL,假设没有Azkaban这样的调度框架,一般用crontab+shell,但crontab+shell虽然简单易用,但也有明显的缺点,如任务的依赖处理、任务监控、任务流的可视化等,就需要一个调度框架来统一。
常见的任务调度框架有Apache Oozie、LinkedIn Azkaban、Apache Airflow、Alibaba Zeus,由于Azkaban具有轻量可插拔、友好的WebUI、SLA告警、完善的权限控制、易于二次开发等优点,也得到了广泛应用。
本文以Azkaban为例,总结Azkaban基本原理,以及三种模式的部署和测试。
Azkaban原理
Azkaban架构
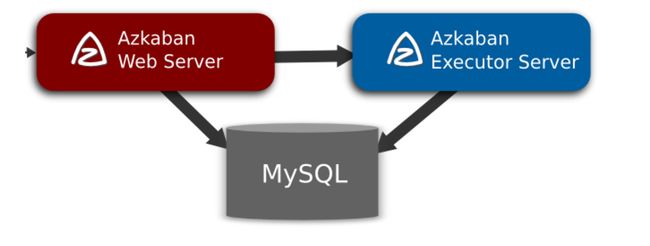
Azkaban三个关键组件的作用
Relational Database:存储元数据,如项目名称、项目描述、项目权限、任务状态、SLA规则等。
AzkabanWebServer:项目管理、权限授权、任务调度、监控executor。
AzkabanExecutorServer:作业流执行的Server。
Azkaban三种部署模式
solo-server模式
DB使用的是一个内嵌的H2,Web Server和Executor Server运行在同一个进程里。这种模式包含Azkaban的所有特性,但一般用来学习和测试。
two-server模式
DB使用的是MySQL,MySQL支持master-slave架构,Web Server和Executor Server运行在不同的进程中。
分布式multiple-executor模式
DB使用的是MySQL,MySQL支持master-slave架构,Web Server和Executor Server运行在不同机器上,且有多个Executor Server。
Azkaban三种模式安装前准备
Azkaban3.x在安装前需要自己编译成二进制包。
(1)编译环境
git => [root@node1 ~]#yum install git
g++ => [root@node1 ~]# yum install gcc-c++(2)下载源码&解压
[root@node1 ~]# wget https://github.com/azkaban/azkaban/archive/3.42.0.tar.gz
[root@node1 ~]# mv 3.42.0.tar.gz azkaban-3.42.0.tar.gz
[root@node1 ~]# tar -zxvf azkaban-3.42.0.tar.gz
[root@node1 ~]# ls
azkaban-3.42.0 azkaban-3.42.0.tar.gz(3)编译
[root@node1 ~]# cd azkaban-3.42.0
[root@node1 azkaban-3.42.0]# ./gradlew build installDist -x test #Gradle是一个基于Apache Ant和Apache Maven的项目自动化构建工具。-x test 跳过测试(4)编译后生成的安装包路径
[root@node1 azkaban-3.42.0]# pwd
/root/azkaban-3.42.0
#solo-server模式安装包路径
[root@node1 azkaban-3.42.0]# ls azkaban-solo-server/build/distributions/
#two-server模式和multiple-executor模式web-server安装包路径
[root@node1 azkaban-3.42.0]# ls azkaban-web-server/build/distributions/
#two-server模式和multiple-executor模式exec-server安装包路径
[root@node1 azkaban-3.42.0]# ls azkaban-exec-server/build/distributions/solo-server模式部署
(1)节点规划
| HOST | 角色 |
|---|---|
| node1 | Web Server和Executor Server同一进程 |
(2)解压
[root@node1 ~]# tar -zxvf /root/azkaban-3.42.0/azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C .(3)配置
[root@node1 ~]# vim /root/azkaban-solo-server-0.1.0-SNAPSHOT/conf/azkaban.properties
default.timezone.id=Asia/Shanghai #修改时区(4)启动
[root@node1 ~]# cd /root/azkaban-solo-server-0.1.0-SNAPSHOT/
[root@node1 azkaban-solo-server-0.1.0-SNAPSHOT]# bin/azkaban-solo-start.sh
注:启动/关闭必须进到/root/azkaban-solo-server-0.1.0-SNAPSHOT/目录。(5)验证是否启动成功
[root@node1 ~]# jps
AzkabanSingleServer(对于Azkaban solo‐server模式,Exec Server和Web Server在同一个进程中)
访问Web Server=>http://node1:8081/(6)测试带有依赖的任务
A、创建job
[root@node1 ~]# mkdir -p azkaban_jobs/solo_job
#在solo_job目录创建两个文件one.job two.job,内容如下
[root@node1 solo_job]# cat one.job
type=command
command=echo "this is job one"
[root@node1 solo_job]# cat two.job
type=command
dependencies=one
command=echo "this is job two"
#打包成zip包
[root@node1 azkaban_jobs]# zip -r solo_job.zip solo_job/B、Azkaban WebUI创建工程并执行
http://node1:8081/index登录=>Create Project=>Upload 上一步生成的zip包 =>execute flow执行一步步操作即可
注:在Azkaban项目中,任务的名称是以最后一个Job名来命名的。B_1、创建工程
B_2、上传job zip文件
B_3、执行
B_4、结果
two-server模式部署
(1)节点规划
| HOST | 角色 |
|---|---|
| node1 | web‐server和exec‐server不同进程 |
| node2 | MySQL |
(2)解压web‐server和exec‐server
#web-server
[root@node1 ~]# tar -zxvf /root/azkaban-3.42.0/azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C .
#exec‐server
[root@node1 ~]# tar -zxvf /root/azkaban-3.42.0/azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C .(3)将Azkaban源码中的create-all-sql脚本拷贝到Mysql所在节点node2
[root@node1 ~]# scp /root/azkaban-3.42.0/azkaban-db/build/install/azkaban-db/create-all-sql-0.1.0-SNAPSHOT.sql root@node2:~(4)Mysql上创建对应的库、增加权限、创建表
mysql> CREATE DATABASE azkaban_two_server; #创建数据库
mysql> use azkaban_two_server;
mysql> CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';#创建用户
mysql> GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban_two_server.* to 'azkaban'@'%' WITH GRANT OPTION;#给用户授权
mysql> source create-all-sql-0.1.0-SNAPSHOT.sql;#创建表(5)生成ssl
[root@node1 ~]# keytool -keystore keystore -alias jetty -genkey -keyalg RSA
注:密码和最后确认需要输入,其他默认即可。(6)设置web‐server
拷贝conf目录和log4j.properties
[root@node1 ~]# cp -r /root/azkaban-solo-server-0.1.0-SNAPSHOT/conf /root/azkaban-web-server-0.1.0-SNAPSHOT/
[root@node1 ~]# find azkaban-3.42.0 -name 'log4j*'
[root@node1 ~]# cp azkaban-3.42.0/azkaban-web-server/src/test/resources/log4j.properties azkaban-web-server-0.1.0-SNAPSHOT/conf/
[root@node1 ~]# vim azkaban-web-server-0.1.0-SNAPSHOT/conf/azkaban.properties
#需要修改的地方
default.timezone.id=Asia/Shanghai
#database.type=h2
#h2.path=./h2
#h2.create.tables=true
database.type=mysql
mysql.port=3306
mysql.host=node2
mysql.database=azkaban_two_server
mysql.user=azkaban
mysql.password=azkaban
mysql.numconnections=100
jetty.keystore=/root/keystore #keytool生成的keystore路径
jetty.password=1234567 #keytool中设置的密码
jetty.keypassword=1234567
jetty.truststore=/root/keystore
jetty.trustpassword=1234567添加azkaban.native.lib=false 和 execute.as.user=false属性
[root@node1 azkaban-web-server-0.1.0-SNAPSHOT]# mkdir -p plugins/jobtypes
[root@node1 jobtypes]# cat commonprivate.properties
azkaban.native.lib=false
execute.as.user=false(7)启动web-serrver并验证
[root@node1 ~]# cd azkaban-web-server-0.1.0-SNAPSHOT/
[root@node1 azkaban-web-server-0.1.0-SNAPSHOT]# bin/azkaban-web-start.sh
验证:
jps=>AzkabanWebServer
webUI=>http://node1:8081/index(8)从web-server拷贝conf目录、plugins目录并启动executor‐server
[root@node1 ~]# cd azkaban-exec-server-0.1.0-SNAPSHOT/
[root@node1 azkaban-exec-server-0.1.0-SNAPSHOT]# cp -r ../azkaban-web-server-0.1.0-SNAPSHOT/conf/ .
[root@node1 azkaban-exec-server-0.1.0-SNAPSHOT]# cp -r /root/azkaban-web-server-0.1.0-SNAPSHOT/plugins/ .
[root@node1 azkaban-exec-server-0.1.0-SNAPSHOT]# bin/azkaban-executor-start.sh(9)测试带有依赖的任务
注:Hadoop、Spark的命令尽量用全路径。
A、创建带有hadoop 和spark 且有依赖的Job
[root@node1 ~]# cd azkaban_jobs/
[root@node1 azkaban_jobs]# mkdir two_server_job
[root@node1 two_server_job]# cat mr.job
type=command
command=hadoop jar /usr/hdp/2.6.4.0-91/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.6.4.0-91.jar wordcount /data/mr_test_data.txt /result_mr/
[root@node1 two_server_job]# cat spark.job
type=command
dependencies=mr
command=/usr/hdp/2.6.4.0-91/spark2/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 5
40M --num-executors 1 /usr/hdp/2.6.4.0-91/spark2/examples/jars/spark-examples_2.11-2.2.0.2.6.4.0-91.jar 100
[root@node1 azkaban_jobs]# zip -r two_server_job.zip two_server_job/B、创建工程two_server_dependency上传zip文件
C、运行
D、MapReduce Spark运行结果
分布式multiple-executor模式
(1)节点规划
| HOST | 角色 |
|---|---|
| node1 | web-server、exec-server |
| node2 | mysql |
| node3 | exec-server |
(2)拷贝exec-server到node3
[root@node1 ~]# scp -r azkaban-exec-server-0.1.0-SNAPSHOT/ root@node3:~(3)在node3 exec-server 重新生成keystore
[root@node3 ~]# keytool -keystore keystore -alias jetty -genkey -keyalg RSA(4)在azkaban web-server中azkaban.properties配置文件添加配置
#启用multiple-executor模式
azkaban.use.multiple.executors=true
#在每次分发job时,先过滤出满足条件的executor,然后再做比较筛选
#如最小剩余内存,MinimumFreeMemory,过滤器会检查executor空余内存是否会大于6G,如果不足6G,则web-server不会将任务交由该executor执行。可参考Azkaban Github源码
#如CpuStatus,过滤器会检查executor的cpu占用率是否达到95%,若达到95%,web-server也不会将任务交给该executor执行。可参考Azkaban Github源码。
#参数含义参考官网说明http://azkaban.github.io/azkaban/docs/latest/#configuration
#由于是虚拟机,不需要过滤,只需要比较即可
#azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
#某个任务是否指定了executor id
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
#内存
azkaban.executorselector.comparator.Memory=1
#最后一次被分发
azkaban.executorselector.comparator.LastDispatched=1
#CPU
azkaban.executorselector.comparator.CpuUsage=1(4)在azkaban_two_server库executors表中添加executor
mysql> insert into executors(host,port,active) values("192.168.222.101",12321,1);
mysql> insert into executors(host,port,active) values("192.168.222.103",12321,1);
注:这里把active设置为1(激活状态)。(5)启动node1 web-server、node1 exec-server、node3 exec-server
先启动exec-server,再启动 web-server
(6)创建工程名multiple-executor上传job文件
#solo_job.zip文件内容
one.job 内容
type=command
command=echo "this is job one"
two.job 内容
type=command
dependencies=one
command=echo "this is job two"(7)关闭node1 上的exec-server 执行job
[root@node1 azkaban-exec-server-0.1.0-SNAPSHOT]# bin/azkaban-executor-shutdown.sh可以看到,在node1 exec关闭后,任务被提交到了node3 exec,最终执行成功。
同理,关闭node3 exec,任务会被调度到node1 exec。
Azkaban 企业级部署HA
Azkaban WebServer挂掉,不影响已经提交的任务执行,主要是不能通过WebUI查看Job、管理Job、跟踪Job状态。
因此,对于这个架构,主要是要解决MySQL HA和ExecutorServer HA。官方支持ExecutorServer HA,我们只需要配一个MySQL HA就行了。