Image-Text Matching and VQA
Attention!
我的Dr.Sure项目正式上线了,主旨在分享学习Tensorflow以及DeepLearning中的一些想法。期间随时更新我的论文心得以及想法。
Github地址:https://github.com/wangqingbaidu/Dr.Sure
CSDN地址:http://blog.csdn.net/wangqingbaidu
个人博客地址:http://www.wangqingbaidu.cn/
Image-Text Matching and VQA
图文匹配以及图像的QA是图像与文本多模态融合的前沿领域。前者需要将图像与文本都映射到一个相同的语义空间,然后通过距离对他们的相似度进行判断;后者则要解决的是在所有的候选集中寻找到合适的答案,其核心思想是让图像的Attention的位置随着问题进行变化。
这里Dr.Sure就分享几篇关于这两个方面的工作。
Convolutional Neural Network Architectures for Matching Natural Language Sentences,这篇论文是Image-Text Matching任务普遍使用的对文本处理的办法,相当于是一片自然语言处理的经典工作。
Multimodal Convolutional Neural Networks for Matching Image and Sentence,这个工作与上面的文章系出同门,都是华为诺亚方舟实验室的成果。多模态融合的技术,有别于以往的多模态融合要么只关心word,要么只关心phase,要么只关心sentence,这篇文章对着三种不同的文本语义信息进行了融合。做到了当时的stateofart。
Dual-Path Convolutional Image-Text Embedding,双路卷积(图像、文本),但是在文本的卷积网络引入了Residual的思想,也就是这双路卷积都是Residual Net。损失函数方面,引入了Instance Loss + Ranking Loss。最有趣的是作者引入了两阶段模型训练,在不同的阶段使用不同的训练策略。
Dual Attention Networks for Multimodal Reasoning and Matching,这个是把Attention的机制引入到了Matching以及VQA的任务中。不同的文本信息需要对应到图像中的不同位置,也就是说需要Attention机制让他们映射到相同的语义空间。
一、Convolutional Neural Network Architectures for Matching Natural Language Sentences
其核心思想是将卷积操作应用到文本,这篇文章要解决的问题是Text之间的匹配问题。
1. Text Convolutional
首先说说文本的卷积操作:将离散的文本信息进行Embedding之后,就会得到文本的连续特征,也就是一个word可以用一个vector进行表示,这时候它就跟图像十分相似。一个word相当于是图像中的一个像素,一个sentence就是有若干的这样的word构成。在具体的实现中可以将Embedding的特征维度等效于图像的通道数,这样将单词首尾相连,最后构成一个长度1×N(文本单词个数)的图像,此时使用1d的卷积核对文本信息进行处理就可以实现文本的卷积网络。
图像可以通过线性差值或者其它差值方法,将不同尺寸的图像resize到一个相同的大小,但是文本却没有这种操作,所以文本的卷积一般使用的是一种Gated的Convolutional Layer, 也就是说,对于不够长度的句子,强制为0,如下图:
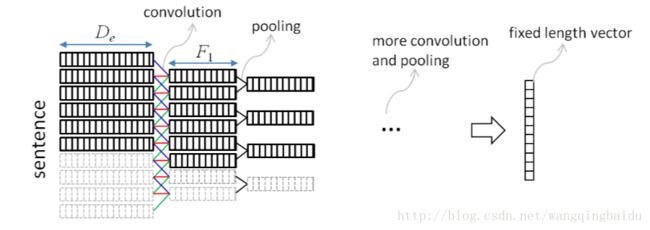
另外一个需要注意的点就是,一般文本的Pooling方式都会选择Maxpooling,这样能让局部特征得到最大化的相应。
2. Architecture
文中提出两种网络结构,一种是匹配的后融合技术,即在两个待匹配的Text,通过CNN获得他们的向量表示,然后在进行拼接,加几层全连接对最后匹配进行预测。
Arc-I的网络结构图如图:

从图中可以看到它对encode的特征处理方式属于特征的后融合,而且非常的naive。在这样的网络模型中,他没有考虑到不同句子,单词顺序之间的相关性,也就是硬生生地将两个句子映射到了一个语义空间,为了解决这个问题,作者了第二处理方法:
Arc-II的网络结构图如图:

作者将两个句子的所有单词位置进行了一个组合,每一个位置使用下面的公式进行表示:
x,y分别代表待匹配的句子,通过上面的公式,两个句子会构成一个正方形的FM1,FM1的每一个位置由2k1个vector构成。也就是其实他是一个4维的结构构成[#Sentence × #Sentence × 6 × #Embd_size]。使用后面两维进行一维的卷积,会形成layer-2的一个三维的feature map。
然后后面的网络结构就是图像中常见的模型了。
3. Conclusion
- 卷积网络处理文本数据,将位置信息引入到卷积网络
- 中,构成一个3d的特征图。Gated Convolution,在句子不够长的时候,确保不会影响梯度。
- MaxPooling,保证局部特征的最大化响应。
二、Multimodal Convolutional Neural Networks for Matching Image and Sentence
这篇工作需要解决的是图像与文本的匹配问题,图像特征没有太大的创新,就是CNN网络提取的特征。与以前工作不同的是,他将图像特征与文本特征前融合,直接输入到卷积网络中进行匹配,而且关注到了不同粒度的文本信息。
作者处理特征的方式是直接将特征进行Concatenate。
1. Word-level Matching CNN
最细粒度的匹配问题。网络结构如下图:

其计算公式如下:
2. Phase-level Matching CNN
词语粒度的匹配,网络结构如下图:

公式如下:
短语级别的Matching CNN与word相似,只不过是位置不同而已,作者在文中使用了两种不同粒度的短语,一个是2个单词,一个是4个单词。
在这个里面有一个非常有用的概念就是感受野,也就是对应着一个神经元是由几个单词计算得来,这个概念与图像中的感受野概念相同。
3. Sentence-level Matching CNN
句子级别的匹配,网络结构如下图:

句子级别的匹配就是使用最后的特征进行拼接。
4. Result

可以看到最终Ensemble的效果是最好的,但是单模型的表现一般。
三、Dual-Path Convolutional Image-Text Embedding
这个工作要解决的问题同样是图文匹配的问题,与上两篇工作不同的是,它没有采用前融合(一般是前融合的效果好于后融合)。但是引入了一些比较有意思的idea。
1. Architecture

这个网络结构的最大的特点就是在Text的encoder中引入了Residual,后融合地对图像以及文字解决匹配问题。
2. Loss function
作者在loss function中引入了一个instance loss,那instance loss是什么东西呢?
所谓instance loss,就是在做图文匹配的任务重,每一个pair都作为一个instance,然后通过一个softmax分类器,去学习这个损失函数。
这个想法其实就是将算法去适应数据,也就是将匹配问题,转化成了一个分类问题。
这种转化风险是相当大的,因为我们的Query是多种多样的,我们永远无法穷尽所有的Query和Image的pair,所以一个最基本的想法是做成Multi-Task。
在讲Multi-Task的loss之前,先要讲一下Ranking Loss。
一般的Ranking Loss定义如下:
S为相似度计算函数,μ为需要保证相似度里面的最小margin。这样的Ranking Loss只考虑到了x作为匹配对象的损失,但是没有考虑到y,既然x和y是一个pair,所以需要有一个双路的损失。
基于这个问题,作者提出了下面的Ranking loss损失函数:
前面的部分是Image的Ranking Loss,后面部分是Text的Ranking Loss。
所以最后作者的loss一共包括3个部分,分别是Ranking loss,视觉的Instance loss,文本的Instance loss。
3. Some Interesting Tricks
这篇工作包含很多有意思的trick,或者不叫trick,应该说是训练模型的经验比较好。
- 使用word2vec初始化的模型Embedding模型比随机初始化。
- Sentence的jittering,作者在句子的开头和结尾随机添加了一定量的zero padding。
- Instance Loss最后公用一个相同的权重参数,保证两种不同模态的信息,映射到一个相同的空间。
Two Stage训练,Dr.Sure感觉这个想法最有趣了。
Stage-I,在这个阶段,作者首先训练Text的Residual网络,并且把Ranking Loss和图像CNN的模型Fix住,这样可以训练好Text的CNN。作者这样干是因为,Text的网络是随机初始化的,如果加入Ranking Loss因为一开始图像和文本肯定不在一个相同的语义空间,怕把这个损失带入到Text的网络。Fix图像CNN,是因为不想让图像的梯度与文本梯度相互干扰。
Stage-II,当Text的CNN训练的收敛的时候,将Ranking Loss和图像的CNN添加到模型中,一起端到端地训练,最终效果最好。
四、Dual Attention Networks for Multimodal Reasoning and Matching
这篇工作最主要的点是将Attention机制引入到网络模型中,这个出发点比较明显:图文匹配终极问题是整个Text与整个Image的匹配问题,但是这个问题比较难以解决,所以一个最基本的想法就是把这个问题拆分开来,Text由不同的单词构成,Image由不同的区域构成,如果能把Text的单词与Image的区域进行一个匹配,那么这个问题就会变得比较简单。
一个基本的思路就是使用Attention机制,在网络中自动匹配文本单词与图像区域进行匹配。作者引用了两种Attention机制,分别是:Visual Attention以及Text Attention。
这两种Attention都是使用前面一种的状态,决定下一个状态需要Attention的”位置”。
1. Visual Attention
视觉Attention的公式如下:
公式中所有的W都是网络需要学习的参数,h为隐藏状态,m为memory向量。
2. Textual Attention
文本Attention的公式如下:
两种Attention的步长K是超参,作者在实验中证明K=2效果是最好的。
3. Visual and Textual Representation
视觉特征使用的就是第二层的Resnet或者VGG的特征,文本特征使用的是双向RNN(LSTM)的特征,其中视觉特征表示如下图所示:

4. VQA & Image-Text Matching
文中作者解决了两种不同的问题,两种不同的问题,都用到了前面的Attention机制,但是不同的问题,对Attention的使用方法不尽相同。
A. Visual Question and Answer
在VQA的数据集中,所有的答案是一个单词,所以本质上来说,这个问题是一个分类问题,即需要知道最后Question是Answer集合中的哪一个。
它的网络结构图如下图:
从图中可以看到,它使用最后memory向量进行分类。
Memory Vectory计算公式如下:
m(k)=m(k−1)+v(k)⊙u(k) m ( k ) = m ( k − 1 ) + v ( k ) ⊙ u ( k )不同参数的初始化如下图:
m(0)=v(0)⊙u(0) m ( 0 ) = v ( 0 ) ⊙ u ( 0 )
m(0)=v(0)⊙u(0)wherev(0)=tanh(p(0)1N∑nvn) m ( 0 ) = v ( 0 ) ⊙ u ( 0 ) w h e r e v ( 0 ) = t a n h ( p ( 0 ) 1 N ∑ n v n )
u(0)=1N∑tut u ( 0 ) = 1 N ∑ t u t

由于是图像问答的任务,所以需要将文本特征与图像特征在每一个Attention的步骤进行融合,最后进行输出,根据最后融合的特征,使用一个softmax分类器即可。
B. Image-Text Matching
图文匹配问题与VQA最大的不同就是,他要解决的是一个Rank问题,所以需要比对两种特征之间的距离,因此就不能共享一个相同的Memory Vector。
对应Image和Text都有自己的Memory Vector, 他们的计算公式如下:
m(k)v=m(k−1)v+v(k) m v ( k ) = m v ( k − 1 ) + v ( k )
m(k)u=m(k−1)u+u(k) m u ( k ) = m u ( k − 1 ) + u ( k )其网络结构如下:

最终实验中作者使用的是与上一篇工作相同的Ranking Loss,有一点不同的是每一步的Attention都会产生一个匹配的向量,这里做的是把所有的S进行相加。
五、One More Thing
纵观这几篇论文,所有的模型都是在处理图文融合,也就是多模态融合,他的一个最基本的出发点就是文本和图像的encoder模型都要足够的好,也就是第一篇文章中的卷积(好像也可以使用RNN)。
有了优秀的encoder,接下来要做的就是特征的融合,目前有两种融合特征的方式,一个是前融合一个是后融合。前融合将图像信息与文本信息一通输入到一个网络进行进一步的encoder,最后再使用任务相关的网络;后融合就是图像文本的encoder出来的特征直接concat,然后输入到任务相关的网络,一般来说前融合的网络要好于后融合。
图文匹配是一个全部句子与全部图像的匹配问题,直接去解这个问题可能相对来说比较困难,所以有些时候需要将这些数据拆分成components,这就是第2篇和第4片文章最主要的出发点。
另外一个就是模型训练中有很多的trick,有些时候或者说大多时候不是因为我们的idea不够优秀,而是因为我们对于模型的训练经验不足,所以就告诉我们训练模型一定要有耐心,如果认为自己的路是对的,就可以坚持走下去,最后肯定有好的效果。