大数据ETL实践探索(9)---- 使用pandas sqlalchemy 以及多进程进行百万级 postgresSQL 数据入库
文章大纲
- 0.基础性工作
- 连接类
- sqlclchemy 基础操作
- sqlalchemy 数据库shema 表 样例
- pandas 加速读取 excel
- 2.psycopg2 原生 api
- 3.pgAdmin 导入
- 4.pandas 数据清洗与to_sql方法录入数据
- 数据清洗
- 数据类型转换
- 数据脱敏
- 增加自增列
- to_sql 数据录入
- 5.使用 sqlalchemy 批量录入方法
- sqlalchemy 参数性能调优
- PostgreSQL 参数优化
- sqlalchemy DBsession 批量入数据
- 6.多进程 配合 sqlalchemy 录入数据
- 7.使用cProfile 进行性能分析
- cProfile
- snakeviz可视化 性能分析结果
- 参考文献
最近有个需求,需要将100W 40个字段左右的 excel 格式数据录入 postgreSQL 数据库。 我想了几种办法:
- 使用psycopg2 原生 api
- 使用pgAdmin 页面 建立好table 直接导入csv
- 使用pandas to_sql 方法
- 使用 sqlalchemy 批量录入方法
- 使用python 多进程,pandas 数据清洗后用 sqlalchemy 批量录入方法
先说一下结论吧,我实验的流程是读取3个文件大小分别是3000行,30万行,70万行,清洗合并后是一个111万行40 个字段的宽表。 使用最后一种多进程批量入数据的方式,基本测试结果是,数据加载及清洗将近6分钟,数据入库6分钟。
我机器是i7 7500U 运行上述程序时候 睿频加速到3.5GHz 左右,cpu 占用40%, 数据清洗时候内存占用500-600MB 拆分入库阶段,内存占用飙升到2000MB - 4000MB 其中包含每个子进程单独占用70MB 左右。
后面且听我娓娓道来
0.基础性工作
连接类
主要作用是是数据库链接时候进行数据库链接字符串的管理
# data_to_database.py
class connet_databases:
def __init__(self):
'''
# 初始化数据库连接,使用pymysql模块
#
'''
_host = ''
_port = 5432
_databases = '' # 'produce' #
_username = ''
_password = ''
self._connect = r'postgres+psycopg2://{username}:{password}@{host}:{port}/{databases}'.format(
username=_username,
password=_password,
host=_host,
port=_port,
databases=_databases)
sqlclchemy 基础操作
需要注意的一个细节是,sqlclchemy 对数据库的操作无论是 engine 这个客户端级别的还是 DBsession 这个级别的,在做完操作的时候,都应该 关闭数据库链接。这在操作大量数据时候非常容易忽视。
使用:
DBSession.remove()
engine.dispose()
def init_sqlalchemy(dbname='',
Echo=True,
Base=declarative_base(),
DBSession=scoped_session(sessionmaker())):
# 主要用来建立表
print(dbname)
engine = create_engine(dbname,
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=2, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置)
echo=True)
try:
# engine = create_engine(dbname, echo=Echo)
DBSession.remove()
DBSession.configure(bind=engine, autoflush=False, expire_on_commit=False)
Base.metadata.drop_all(engine)
Base.metadata.create_all(engine)
DBSession.flush()
DBSession.commit()
except Exception as e:
error = traceback.format_exc()
Multiprocess_loaddata_toDatabase.log.logger.error(error)
finally:
DBSession.remove()
engine.dispose()
def get_conn(dbname, Echo=True):
# 获取链接
try:
engine = create_engine(dbname, echo=Echo)
DBSession = scoped_session(sessionmaker())
#DBSession.remove()#scoped_session 本身是线程隔离的,这块不需要remove
DBSession.configure(bind=engine, autoflush=False, expire_on_commit=False)
return DBSession
except:
DBSession.rollback()
raise
sqlalchemy 数据库shema 表 样例
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy import Column, TEXT, String, Integer, DateTime,Float
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class DetailsOfDrugsItems(Base):
'''
# 定义诊疗项目明细对象:
'''
__tablename__ = 'details_of_drugs_items'
# 表的结构:
id = Column(String(64), primary_key=True)
结算编号 = Column(String(64), index=True)
单价 = Column(Float)
数量 = Column(Float)
总金额 = Column(Float)
结算日期 = Column(DateTime)
def __init__(self):
pass
pandas 加速读取 excel
发现是应该可以加速读取csv,当然csv 怎么都快,使用modin 的pandas 比传统的快4倍 其实就是加了个多进程或者线程,难点是加速读取大的excel,没有看到有效的解决方案。
官方文档:https://pypi.org/project/modin/
参考文档:https://www.jiqizhixin.com/articles/2019-04-13-2
pip install modin[dask]
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
2.psycopg2 原生 api
文档链接:https://www.psycopg.org/docs/module.html
3.pgAdmin 导入
文档:https://www.pgadmin.org/docs/pgadmin4/development/import_export_data.html
导入文件支持3中方式:
binary for a .bin file.
csv for a .csv file.
text for a .txt file.

具体导入速度待测试
4.pandas 数据清洗与to_sql方法录入数据
数据清洗
pandas 数据清洗细节可以参考我的文章:
大数据ETL实践探索(5)---- 大数据ETL利器之 pandas
数据类型转换
# pandas_to_postgresql.py
def change_dtypes(col_int, col_float, df):
'''
AIM -> Changing dtypes to save memory
INPUT -> List of column names (int, float), df
OUTPUT -> updated df with smaller memory
------
'''
df[col_int] = df[col_int].astype('int32')
df[col_float] = df[col_float].astype('float32')
def convert_str_datetime(df):
'''
AIM -> Convert datetime(String) to datetime(format we want)
INPUT -> df
OUTPUT -> updated df with new datetime format
------
'''
df.insert(loc=2, column='timestamp', value=pd.to_datetime(df.transdate, format='%Y-%m-%d %H:%M:%S.%f'))
from sqlalchemy import Column, TEXT, String, Integer, DateTime, Float
# 定义函数,自动输出DataFrme数据写入oracle的数类型字典表,配合to_sql方法使用(注意,其类型只能是SQLAlchemy type )
def mapping_df_types(df):
dtypedict = {}
for i, j in zip(df.columns, df.dtypes):
if "object" in str(j):
dtypedict.update({i: String(64)})
if "float" in str(j):
dtypedict.update({i: Float})
if "int" in str(j):
dtypedict.update({i: Float})
return dtypedict
数据脱敏
几个数据脱敏的样例:
姓名脱敏
def desensitization_name(name):
new_name = str(name)[0] + '**'
return new_name
工作单位或者住址的脱敏
import random
def desensitization_location(location):
length = random.randint(2, len(location))
str_desensitization = ''
for i in range(0, length):
str_desensitization = str_desensitization + '*'
temp_str = location[0:length - 1]
new_location = location.replace(temp_str, str_desensitization)
return new_location
#基本敏感信息进行脱敏
明细['姓名'] = 明细['姓名'].apply(pandas_to_postgresql.desensitization_name)
明细['单位名称'] = 住院明细['单位名称'].apply(pandas_to_postgresql.desensitization_location)
增加自增列
为了配合 sqlalchemy 的model 要求,每张表必须有主键,我们可以使用pandas 的dataframe 已经存在的 index 作为主键,或者使用一个自增的id。
使用index 作为id
pdf.rename(columns={'index': 'id'}, inplace=True)
需要注意的是,index 在join 或者 连接操作后会带有dataframe 各自的信息,这会引起,主键不能重复的错误,所以,如果你的dataframe 直接从文件而来,不是拼接或者生成的 可以直接使用index 如果是2次生成的,应该使用以下的方法生成自增唯一id
pdf = pdf.reset_index()
pdf['id'] = range(len(pdf))
to_sql 数据录入
参考文档:to_sql 方法文档
from sqlalchemy.types import Integer
engine = create_engine(data_to_database.connet_databases()._connect, echo=False)
df.to_sql('integers', con=engine, index=False,
dtype={"A": Integer()})
5.使用 sqlalchemy 批量录入方法
不得不说的是sqlalchemy这个玩意的文档可读性真的很差。
- sqlalchemy orm1.3 参考文档:https://docs.sqlalchemy.org/en/13/orm/index.html
- PostgreSQL 支持参考文档 (Support for the PostgreSQL database.):https://docs.sqlalchemy.org/en/13/dialects/postgresql.html#module-sqlalchemy.dialects.postgresql.psycopg2
sqlalchemy 参数性能调优
其实本质就是加个create_engine参数:executemany_mode, 别小看了这个参数,100万数据级别加上这个参数4个进程大概300s 入库完成,不加参数,4个进程入数据得将近一个小时,差了将近十倍。
简直是魔幻现实。
https://www.psycopg.org/docs/extras.html#fast-execution-helpers
Modern versions of psycopg2 include a feature known as Fast Execution Helpers , which have been shown in benchmarking to improve psycopg2’s executemany() performance, primarily with INSERT statements, by multiple orders of magnitude. SQLAlchemy allows this extension to be used for all executemany() style calls invoked by an Engine when used with multiple parameter sets, which includes the use of this feature both by the Core as well as by the ORM for inserts of objects with non-autogenerated primary key values, by adding the executemany_mode flag to create_engine():
engine = create_engine(
"postgresql+psycopg2://scott:tiger@host/dbname",
executemany_mode='batch')
Possible options for executemany_mode include:
None - By default, psycopg2’s extensions are not used, and the usual cursor.executemany() method is used when invoking batches of statements.
‘batch’ - Uses psycopg2.extras.execute_batch so that multiple copies of a SQL query, each one corresponding to a parameter set passed to executemany(), are joined into a single SQL string separated by a semicolon. This is the same behavior as was provided by the use_batch_mode=True flag.
‘values’- For Core insert() constructs only (including those emitted by the ORM automatically), the psycopg2.extras.execute_values extension is used so that multiple parameter sets are grouped into a single INSERT statement and joined together with multiple VALUES expressions. This method requires that the string text of the VALUES clause inside the INSERT statement is manipulated, so is only supported with a compiled insert() construct where the format is predictable. For all other constructs, including plain textual INSERT statements not rendered by the SQLAlchemy expression language compiler, the psycopg2.extras.execute_batch method is used. It is therefore important to note that “values” mode implies that “batch” mode is also used for all statements for which “values” mode does not apply.
For both strategies, the executemany_batch_page_size and executemany_values_page_size arguments control how many parameter sets should be represented in each execution. Because “values” mode implies a fallback down to “batch” mode for non-INSERT statements, there are two independent page size arguments. For each, the default value of None means to use psycopg2’s defaults, which at the time of this writing are quite low at 100. For the execute_values method, a number as high as 10000 may prove to be performant, whereas for execute_batch, as the number represents full statements repeated, a number closer to the default of 100 is likely more appropriate:
engine = create_engine(
"postgresql+psycopg2://scott:tiger@host/dbname",
executemany_mode='values',
executemany_values_page_size=10000, executemany_batch_page_size=500)
PostgreSQL 参数优化
sqlalchemy DBsession 批量入数据
def insert_list(list_obj, DBSession):
try:
DBSession.add_all(list_obj)
DBSession.flush()
DBSession.commit()
except:
DBSession.rollback()
raise
def bulk_insert(df_dict_list,DBSession,class_obj, BULK_SIZE):
"""
将 pandas dataframe 转化成的字典,进行清洗后按照批次入库
"""
try:
nrows = len(df_dict_list)
print(nrows)
dataset = []
for i in range(0,nrows):
# 直接使用 类对象内置的__dict__方法,对实例初始化
temp_obj = class_obj()
line = df_dict_list[i]
temp_obj.__dict__.update(line)
dataset.append(temp_obj)
if len(dataset) == BULK_SIZE:
data_to_database.insert_list(dataset,DBSession)
print('成功录入 %s 条记录'%(len(dataset)))
Multiprocess_loaddata_toDatabase.log.logger.debug('成功录入 %s 条记录'%(len(dataset)))
print(datetime.datetime.now())
dataset = []
if dataset:
data_to_database.insert_list(dataset,DBSession)
Multiprocess_loaddata_toDatabase.log.logger.debug('成功录入 %s 条记录' % (len(dataset)))
print('录入完成')
print(datetime.datetime.now())
except Exception as e:
error = traceback.format_exc()
Multiprocess_loaddata_toDatabase.log.logger.error(error)
return 0
finally:
DBSession.close()
6.多进程 配合 sqlalchemy 录入数据
主要步骤有以下几个:
- pandas 加载excel 中的数据
- 数据清洗,合并,过滤
- dataframe 转化为dict 的list,并按照进程数进行分片
#pandas dataframe 转化为dict 的list,每行转化为单独的dict
pdf_dictList = pdf.to_dict(orient='records')
# 按照步长进行分片,步长实际上是 每次 录入的数据量
def get_fragmentation_lists(length, bulk_num):
"""获取所有对象 按照 bulk_num 拆分后的 下标列表
length: 总记录数
bulk_num: 拆分的步长
"""
n = int(length / bulk_num)
print("共计拆分的分片数量 : %s" %n)
Fragmentation_list = []
for i in range(0, length, bulk_num):
temp_list = []
temp_list.append(i)
if i + bulk_num - 1 >= length:
temp_list.append(length)
else:
temp_list.append(i + bulk_num - 1)
Fragmentation_list.append(temp_list)
return Fragmentation_list
- 每个进程从队列中获取 dict_list[分片] 进行数据入库
import os
import time
import datetime
from sqlalchemy import create_engine
import multiprocessing
import pandas as pd
import traceback
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker
from multiprocessing import Pool
PROCESS_POOL = 4
BULK_NUM = 1000
def insert_pg(dbname,class_obj,BULK_SIZE,df_dict_list):
#
print(dbname)
engine = create_engine(dbname,
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=2, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置)
executemany_mode='values',
#executemany_values_page_size=10000, executemany_batch_page_size=500,
echo=True)
try:
#
DBSession = scoped_session(sessionmaker())
DBSession.configure(bind=engine, autoflush=False, expire_on_commit=False)
print('insert_pg 开始插入 数据----')
log.logger.debug('insert_pg 开始插入 数据----')
pandas_to_postgresql.bulk_insert(df_dict_list,DBSession,class_obj, BULK_SIZE)
DBSession.remove()
#con.close()
except Exception as e:
error = traceback.format_exc()
log.logger.error(error)
finally:
engine.dispose()
def run_insert_pool(df_dict,class_obj):
'''
传入的参数为 dataframe 转化为 dict
'''
start = time.time()
print("开始切分 pandas dataframe dict")
log.logger.debug('run_insert_pool 开始入库------')
length = len(df_dict)
fragmentation_list = get_fragmentation_lists(length, BULK_NUM)
p = Pool(PROCESS_POOL)
for fragmentation in fragmentation_list:
log.logger.debug("多进程入库 %s"% str(fragmentation))
tmp_dict_list = df_dict[fragmentation[0]:fragmentation[1]+1]
p.apply_async(insert_pg, (data_to_database.connet_databases()._connect,class_obj,BULK_NUM,tmp_dict_list))
print("---- run_insert_pool start----")
p.close()
p.join()
end = time.time()
print("Finish to insert data to pg spend:{}s".format(end - start))
7.使用cProfile 进行性能分析
cProfile
python profile 分析器
cProfile 和 profile 提供了 Python 程序的 确定性性能分析 。 profile 是一组统计数据,描述程序的各个部分执行的频率和时间。这些统计数据可以通过 pstats 模块格式化为报表。
Python 标准库提供了同一分析接口的两种不同实现:
对于大多数用户,建议使用 cProfile ;这是一个 C 扩展插件,因为其合理的运行开销,所以适合于分析长时间运行的程序。该插件基于 lsprof ,由 Brett Rosen 和 Ted Chaotter 贡献。
profile 是一个纯 Python 模块(cProfile 就是模拟其接口的 C 语言实现),但它会显著增加配置程序的开销。如果你正在尝试以某种方式扩展分析器,则使用此模块可能会更容易完成任务。该模块最初由 Jim Roskind 设计和编写。
注解 profiler 分析器模块被设计为给指定的程序提供执行概要文件,而不是用于基准测试目的( timeit 才是用于此目标的,它能获得合理准确的结果)。这特别适用于将 Python 代码与 C 代码进行基准测试:分析器为Python 代码引入开销,但不会为 C级别的函数引入开销,因此 C 代码似乎比任何Python 代码都更快。
主函数使用
if __name__ == '__main__':
multiprocessing.freeze_support()
cProfile.run('main()', filename='result.out')
import pstats
p = pstats.Stats('result.out')
# 按照运行时间和函数名进行排序
# p.strip_dirs().sort_stats("cumulative", "name").print_stats(0.5)
p.strip_dirs().sort_stats("cumulative", "name").print_stats(30)
Finish to insert data to pg spend:364.9579029083252s
Thu Jun 18 10:41:48 2020 result.out
785784290 function calls (785779755 primitive calls) in 765.932 seconds
Ordered by: cumulative time, function name
List reduced from 2347 to 30 due to restriction <30>
ncalls tottime percall cumtime percall filename:lineno(function)
47/1 0.000 0.000 765.933 765.933 {built-in method builtins.exec}
1 1.498 1.498 765.933 765.933 Multiprocess_loaddata_toDatabase.py:345(main)
1 0.208 0.208 764.433 764.433 Multiprocess_loaddata_toDatabase.py:245(insert_join_table)
1 0.026 0.026 364.957 364.957 Multiprocess_loaddata_toDatabase.py:101(run_insert_pool)
1 0.000 0.000 363.166 363.166 pool.py:550(join)
17 362.958 21.350 362.958 21.350 {method 'acquire' of '_thread.lock' objects}
6 0.000 0.000 362.937 60.490 threading.py:1000(join)
6 0.000 0.000 362.937 60.490 threading.py:1038(_wait_for_tstate_lock)
3 0.000 0.000 304.676 101.559 _base.py:270(read_excel)
3 0.000 0.000 284.175 94.725 _base.py:812(__init__)
3 0.000 0.000 284.174 94.725 _xlrd.py:11(__init__)
3 0.000 0.000 284.165 94.722 _base.py:339(__init__)
3 0.000 0.000 284.164 94.721 _xlrd.py:29(load_workbook)
3 0.034 0.011 284.164 94.721 __init__.py:33(open_workbook)
3 0.039 0.013 284.102 94.701 xlsx.py:784(open_workbook_2007_xml)
4 18.369 4.592 282.878 70.720 xlsx.py:543(own_process_stream)
34955476 5.731 0.000 197.262 0.000 ElementTree.py:1219(iterator)
41510 0.062 0.000 163.220 0.004 ElementTree.py:1263(feed)
41522 0.092 0.000 163.199 0.004 ElementTree.py:1627(feed)
41541 50.586 0.001 163.107 0.004 {method 'Parse' of 'pyexpat.xmlparser' objects}
1 0.000 0.000 82.747 82.747 frame.py:1304(to_dict)
1 9.112 9.112 82.742 82.742 frame.py:1428(<listcomp>)
34957080 47.454 0.000 72.091 0.000 ElementTree.py:1544(_start)
1117359 48.202 0.000 66.051 0.000 xlsx.py:622(do_row)
48962848 14.969 0.000 57.198 0.000 frame.py:1428(<genexpr>)
50075640 37.530 0.000 47.326 0.000 common.py:85(maybe_box_datetimelike)
34955468 14.041 0.000 40.430 0.000 ElementTree.py:1512(handler)
34957080 14.921 0.000 23.842 0.000 ElementTree.py:1556(_end)
3 0.000 0.000 20.501 6.834 _base.py:829(parse)
3 0.045 0.015 20.501 6.834 _base.py:390(parse)
Process finished with exit code 0
-
ncalls
调用次数 -
tottime
在指定函数中消耗的总时间(不包括调用子函数的时间) -
percall
是 tottime 除以 ncalls 的商 -
cumtime
指定的函数及其所有子函数(从调用到退出)消耗的累积时间。这个数字对于递归函数来说是准确的。 -
percall
是 cumtime 除以原始调用(次数)的商(即:函数运行一次的平均时间)
snakeviz可视化 性能分析结果
SnakeViz is a viewer for Python profiling data that runs as a web application in your browser. It is inspired by the wxPython profile viewer RunSnakeRun.
snakeviz 文档
本地会启动一个页面,进行性能分析文件的展示
snakeviz result.out
可见 函数的很大部分时间用来 读取excel 了。
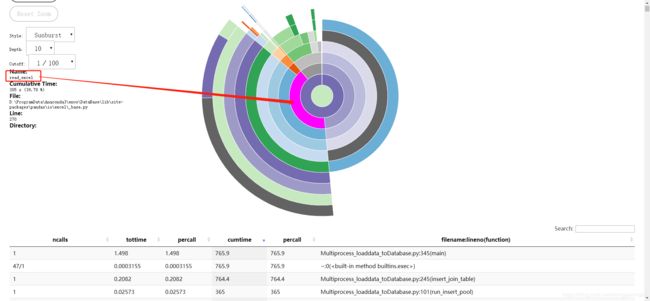
参考文献
Python大型文件数据读取及并行高效写入MongoDB代码分享
Python 多进程导入数据到 MySQL
性能分析与提升
好用的 Python Profile(性能/耗时分析)工具