图卷积网络(GCN)简单理解
1. 预备知识
1.1 图网络的种类、区别和联系
Graph Embedding
Graph Embedding指图嵌入,属于表示学习的范畴,也可以称为网络嵌入、图表示学习、网络表示学习等等。
具体可以参考博主之前整理的关于图嵌入相关内容的资料:链接。
Graph Neural Network (GNN)
GNN指神经网络在图上应用的模型的统称,根据采用的技术不同和分类方法的不同,又可以分为很多不同种类。如从传播的方式来看,图神经网络可以分为图卷积网络(GCN),图注意力网络(GAT)等。
具体来说GNN指的是神经网络模型在图领域所用到的方法的统称。
Graph Convolutional Network
GCN属于GNN的一类,是采用卷积操作的图神经网络。这种方法属于一类采用图卷积的神经网络,可以应用于图嵌入的方法中。
上述三者的关系可以用下图来表示:

1.2 离散卷积
离散卷积本质就是一种加权求和。如下图所示,CNN中的卷积本质上就是一个共享参数的过滤器,通过计算中心像素点及相邻像素点的加权来构成feature map实现空间特征的提取。
其中卷积核的系数,通过随机化初值,然后根据loss反向传播梯度下降迭代优化。卷积核的函数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。

1.3 为什么要研究GCN
CNN是计算机视觉领域的法宝,究其原因,是因为1.2中提到的,卷积核可以有效地提取出图像或视频数据中排列整齐的像素点矩阵,如下图所示。

相对应的,在科学研究中存在非欧式模型的数据,如下图所示,这是一个社交网络的数据结构。
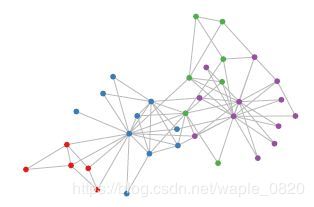
实际上,这样的网络结构就是图论中抽象意义上的拓扑图。所以,GCN中G代表用顶点和边建立相应关系的拓扑图。
研究GCN的主要原因有以下几点:
- CNN无法处理Non Euclidean Structure的数据,学术上的表达是传统的离散卷积在这类数据上无法保持平移不变性。通俗讲就是在拓扑图中每个顶点的相邻顶点数目都可能不同,无法使用同样尺寸的卷积核来进行运算。
- 我们希望在这种类似于拓扑图的结构上有效地提取空间特征来进行机器学习。
- 广义上来说任何问题在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想。这句话意思就是我们熟知的CV/NLP等问题实际上都可以通过建立拓扑关联转化为拓扑图的形式。所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
1.4 谱聚类
谱聚类(Spectral Clustering)是一种针对图结构的聚类方法,它跟其他聚类算法的区别在于,他将每个点都看作是一个图结构上的点,所以判断两个点是否属于同一类的依据就是,两个点在图结构上是否有边相连,可以是直接相连也可以是间接相连。举个例子,一个紧凑的子图(完全图)一定比一个松散的子图更容易聚成一类。
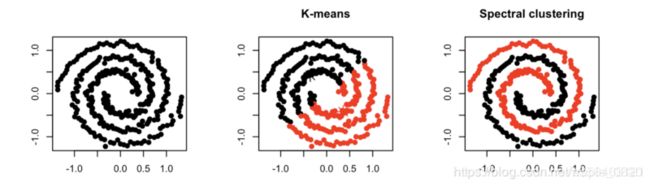
如上图,在k-means算法中会把空间分布距离较近的归为一类,而谱聚类则会把更紧凑的点聚为一类。
2. 图卷积预备定理
2.1 Motivation
图嵌入理论中我们说明了如果想把拓扑图转化为模型的输入,就必须将每个节点用其特征进行向量表示。而在试图得到节点表示的时候,容易想到的最方便的手段就是利用它周围的节点,也就是他的邻居节点等。
主要问题
- 我们需要按照什么条件去找neighbors?
- 确定感受野之后,按照什么方式处理包含不同数目的节点特征?
2.2 傅里叶变换
为了解决在拓扑图上无法有效地进行卷积计算的问题,我们需要了解Fourier变换的作用。
首先GCN中C(Convolution)的数学定义:
( f ∗ g ) ( t ) = ∫ ℜ f ( x ) g ( t − x ) d x (f*g)(t)=\int_{\Re}f(x)g(t-x)dx (f∗g)(t)=∫ℜf(x)g(t−x)dx
一般称g为作用在f上的filter或kernel
根据卷积定理,卷积公式还可以写成: f ∗ g = F − 1 { F { f } ⋅ F { g } } f*g=\mathcal{F}^{-1}\{\mathcal{F}\{f\}\cdot\mathcal{F}\{g\}\} f∗g=F−1{F{f}⋅F{g}}
这样我们只需要定义图上的傅里叶变换,就可以定义出图上的卷积变换。
到这里,我们首先需要推导上面的定理。
首先看看傅里叶变换的定义:
F { f } ( v ) = ∫ ℜ f ( x ) e − 2 π i x ⋅ v d x \mathcal{F}\{f\}(v) = \int_{\Re}f(x)e^{-2\pi ix\cdot v}dx F{f}(v)=∫ℜf(x)e−2πix⋅vdx
其逆变换(Inverse Fourier)则是:
F − 1 { f } ( x ) = ∫ ℜ f ( v ) e 2 π i x ⋅ v d x \mathcal{F}^{-1}\{f\}(x) = \int_{\Re}f(v)e^{2\pi ix\cdot v}dx F−1{f}(x)=∫ℜf(v)e2πix⋅vdx
根据Fourier变换及其逆变换的定义,我们可以证明卷积定理。定义h是f和g的卷积,那么:
h ( z ) = ∫ ℜ f ( x ) g ( z − x ) d x h(z)=\int_{\Re}f(x)g(z-x)dx h(z)=∫ℜf(x)g(z−x)dx
有:
F { f ∗ g } ( v ) = F { h } ( v ) = ∫ ℜ h ( z ) e − 2 π i z ⋅ v d z = ∫ ℜ ∫ ℜ f ( x ) g ( z − x ) e − 2 π i z ⋅ v d x d z = ∫ ℜ f ( x ) ( ∫ ℜ g ( z − x ) e − 2 π i z ⋅ v d z ) d z \begin{aligned} \mathcal{F}\{f*g\}(v) &= \mathcal{F}\{h\}(v) \\ &= \int_{\Re}h(z)e^{-2\pi iz\cdot v}dz \\ &= \int_{\Re}\int_{\Re}f(x)g(z-x)e^{-2\pi iz\cdot v}dxdz \\ & =\int_{\Re}f(x)(\int_{\Re}g(z-x)e^{-2\pi iz\cdot v}dz)dz \end{aligned} F{f∗g}(v)=F{h}(v)=∫ℜh(z)e−2πiz⋅vdz=∫ℜ∫ℜf(x)g(z−x)e−2πiz⋅vdxdz=∫ℜf(x)(∫ℜg(z−x)e−2πiz⋅vdz)dz
可以令 y = z − x ; d y = d z y=z-x; dy=dz y=z−x;dy=dz,得到:
F { f ∗ g } ( v ) = ∫ ℜ f ( x ) ( ∫ ℜ g ( y ) e − 2 π i ( y + x ) ⋅ v d y ) d x = ∫ ℜ f ( x ) e − 2 π i x ⋅ v ( ∫ ℜ g ( y ) e − 2 π i y ⋅ v d y ) d x = ∫ ℜ f ( x ) e − 2 π i x ⋅ v d x ∫ ℜ g ( y ) e − 2 π i y ⋅ v d y = F { f } ( v ) ⋅ F { g } ( v ) \begin{aligned} \mathcal{F}\{f*g\}(v) &= \int_{\Re}f(x)(\int_{\Re}g(y)e^{-2\pi i(y+x)\cdot v}dy)dx \\ &= \int_{\Re}f(x)e^{-2\pi ix\cdot v}(\int_{\Re}g(y)e^{-2\pi iy\cdot v}dy)dx \\ &= \int_{\Re}f(x)e^{-2\pi ix\cdot v}dx \int_{\Re}g(y)e^{-2\pi iy\cdot v}dy \\ &= \mathcal{F}\{f\}(v) \cdot \mathcal{F}\{g\}(v) \end{aligned} F{f∗g}(v)=∫ℜf(x)(∫ℜg(y)e−2πi(y+x)⋅vdy)dx=∫ℜf(x)e−2πix⋅v(∫ℜg(y)e−2πiy⋅vdy)dx=∫ℜf(x)e−2πix⋅vdx∫ℜg(y)e−2πiy⋅vdy=F{f}(v)⋅F{g}(v)
最后等式两边同时作用 F − 1 \mathcal{F}^{-1} F−1,得到:
f ∗ g = F − 1 { F { f } ⋅ F { g } } f*g=\mathcal{F}^{-1}\{\mathcal{F}\{f\}\cdot\mathcal{F}\{g\}\} f∗g=F−1{F{f}⋅F{g}}
2.3 Laplacian算子
一阶导数定义为:
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h f'(x)=\lim_{h\to 0}\frac{f(x+h)-f(x)}{h} f′(x)=h→0limhf(x+h)−f(x)
laplacian算子简单来说就是二阶导数:
Δ f ( x ) = lim h → 0 f ( x + h ) − 2 f ( x ) + f ( x − h ) h 2 \Delta f(x)=\lim_{h\to 0}\frac{f(x+h)-2f(x)+f(x-h)}{h^{2}} Δf(x)=h→0limh2f(x+h)−2f(x)+f(x−h)
在graph上,我们可以定义一阶导数为:
f ∗ g ′ ( x ) = f ( x ) − f ( y ) f'_{*g}(x)=f(x)-f(y) f∗g′(x)=f(x)−f(y)
其中y是x的邻居节点
那么对应的Laplacian算子可以定义为:
Δ ∗ g f ′ ( x ) = ∑ y ∼ x f ( x ) − f ( y ) \Delta_{*g}f'(x)=\sum_{y\sim x}f(x)-f(y) Δ∗gf′(x)=y∼x∑f(x)−f(y)
定义 D D D是 N × N N \times N N×N的度数矩阵(degree matrix)
D ( i , j ) = { d i i f i = j 0 o t h e r w i s e D(i,j)=\left\{ \begin{aligned} d_{i} \quad & if \quad i=j \\ 0 \quad & otherwise \end{aligned} \right. D(i,j)={di0ifi=jotherwise
定义 A A A为 N × N N\times N N×N的邻接矩阵(adjacency matrix)
A ( i , j ) = { 1 i f x i ∼ x j 0 o t h e r w i s e A(i,j)=\left\{ \begin{aligned} 1 \quad & if \quad x_{i}\sim x_{j} \\ 0 \quad & otherwise \end{aligned} \right. A(i,j)={10ifxi∼xjotherwise
这里的两个矩阵定义都可以参考2.4中的例子来理解。
那么拉普拉斯算子可以写成:
L = D − A L=D-A L=D−A
标准化之后可以得到:
L = I N − D − 1 / 2 A D − 1 / 2 L=I_{N}-D^{-1/2}AD^{-1/2} L=IN−D−1/2AD−1/2
定义Laplacian算子的目的是为了找到Fourier变换的基,比如传统的Fourier变换的基 e 2 π i x ⋅ v e^{2\pi ix\cdot v} e2πix⋅v就是Laplacian算法的一组特征向量:
Δ e 2 π i x ⋅ v = λ e 2 π i x ⋅ v \Delta e^{2\pi ix\cdot v}=\lambda e^{2\pi ix\cdot v} Δe2πix⋅v=λe2πix⋅v
其中 λ \lambda λ是一个常数。
那么上面的Fourier基就是 L L L矩阵的n个特征向量 U = [ u 1 , . . . , u n ] U=[u_{1},...,u_{n}] U=[u1,...,un], L L L可以分解为:
L = U Λ U T L=U\Lambda U^{T} L=UΛUT
其中 Λ \Lambda Λ是特征值组成的对角矩阵
| 传统Fourier变换 | Graph Fourier变换 | |
|---|---|---|
| Fourier变换基 | e − 2 π i x v e^{-2\pi i xv} e−2πixv | U T U^{T} UT |
| 逆Fourier变换基 | e 2 π i x v e^{2\pi ixv} e2πixv | U U U |
| 维度 | ∞ \infin ∞ | 点的个数 n n n |
那么Graph Fourier变换可以定义为:
G F { f } ( λ l ) = ∑ i = 1 n f ( i ) u l ∗ ( i ) \mathcal{GF}\{f\}(\lambda_{l})=\sum_{i=1}^{n}f(i)u_{l}^{*}(i) GF{f}(λl)=i=1∑nf(i)ul∗(i)
其中 f i f{i} fi可以看做是作用在第 i i i个点上的signal,用向量 x = ( f ( 1 ) … f ( n ) ) ∈ ℜ n x=(f(1)\dots f(n)) \in \Re^{n} x=(f(1)…f(n))∈ℜn来表示。 u l ∗ u_{l}^{*} ul∗是 u l u_{l} ul的对偶向量, u l ∗ u_{l}^{*} ul∗是矩阵 U T U^{T} UT的第 l l l行, u l u_{l} ul是矩阵 U U U的第 l l l行。
那么我们可以用矩阵形式来表示Graph Fourier变换:
G F { x } = U T x \mathcal{GF}\{x\}=U^{T}x GF{x}=UTx
类似的,Inverse Graph Fourier变换定义为:
I G F f ^ ( i ) = ∑ l = 0 n − 1 f ^ ( λ l ) u l ( i ) \mathcal{IGF} \hat{f}(i)=\sum_{l=0}^{n-1}\hat{f}(\lambda_{l})u_{l}(i) IGFf^(i)=l=0∑n−1f^(λl)ul(i)
它的矩阵形式表达为:
I G F { x } = U x \mathcal{IGF}\{x\} = Ux IGF{x}=Ux
2.4 相关矩阵定义

图中拉普拉斯矩阵就是由度矩阵D-邻接矩阵A构造出的。
3. 推导Graph Convolution
首先我们可以根据2中推导的卷积定理:
f ∗ g = F − 1 { F { f } ⋅ F { g } } f*g=\mathcal{F}^{-1}\{\mathcal{F}\{f\}\cdot\mathcal{F}\{g\}\} f∗g=F−1{F{f}⋅F{g}}
那么图的卷积公式可以表示为:
g ∗ x = U ( U T g ⋅ U T x ) g*x=U(U^{T}g\cdot U^{T}x) g∗x=U(UTg⋅UTx)
作为图卷积的filter函数 g g g,我们希望具有很好的局部性。就像CNN模型里的filter一样,只影响到一个像素附近的像素。那么我们可以把 g g g定义成一个laplacian矩阵的函数 g ( L ) g(L) g(L)。
作用一次laplacian矩阵相当于在图上传播了一次邻居节点。进一步我们可以把 U T g U^{T}g UTg看做是 g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ)一个laplacian特征值的函数。
改写上面的图卷积公式,我们就可以得到论文SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS(链接)的公式:
g θ ∗ x = U g θ U T x = U g θ ′ ( Λ ) U T x g_{\theta}*x=Ug_{\theta}U^{T}x=Ug_{\theta'}(\Lambda)U^{T}x gθ∗x=UgθUTx=Ugθ′(Λ)UTx
可以看到这个卷积计算的复杂度非常高,涉及到求Laplacian矩阵的特征向量,和大量的矩阵计算。下面我们考虑对filter函数做近似,目标是省去特征向量的求解:
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( Λ ~ ) g_{\theta'}(\Lambda)\approx\sum_{k=0}^{K}\theta_{k}'T_{k}(\tilde{\Lambda}) gθ′(Λ)≈k=0∑Kθk′Tk(Λ~)
其中 T k T_{k} Tk是Chebyshev多项式。这里可以把简单 g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ)简单看成是 Λ \Lambda Λ的多项式。
因为:
U Λ k U T = ( U Λ U T ) k = L k U\Lambda^{k}U^{T}=(U\Lambda U^{T})^{k}=L^{k} UΛkUT=(UΛUT)k=Lk
所以上面filter函数可以写成 L L L的函数:
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( L ~ ) g_{\theta'}(\Lambda) \approx \sum_{k=0}^{K}\theta_{k}'T_{k}(\tilde{L}) gθ′(Λ)≈k=0∑Kθk′Tk(L~)
设定 K = 1 K=1 K=1,卷积公式可以简化为:
g θ ′ ∗ x ≈ θ ( I N + L ) x = θ ( I N + D − 1 / 2 A D − 1 / 2 ) x \begin{aligned} g_{\theta'}*x & \approx \theta(I_{N}+L)x \\ & = \theta (I_{N}+D^{-1/2}AD^{-1/2})x \end{aligned} gθ′∗x≈θ(IN+L)x=θ(IN+D−1/2AD−1/2)x
令 A ~ = A + I N \tilde{A}=A+I_{N} A~=A+IN, D ~ i i = ∑ j A ~ i j \tilde{D}_{ii}=\sum_{j}\tilde{A}_{ij} D~ii=∑jA~ij可以得到:
g θ ′ ∗ x = θ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 ) x g_{\theta'}*x=\theta(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2})x gθ′∗x=θ(D~−1/2A~D~−1/2)x
那么再加上激活层,我们就可以得到最终的GCN公式:
H l + 1 = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{l+1}=\sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}H^{(l)}W^{(l)}) Hl+1=σ(D~−1/2A~D~−1/2H(l)W(l))
以上。