Tensorflow-吴恩达老师课程笔记
参考:https://study.163.com/my#/smarts
神经网络和深度学习
改善深层神经网络:超参数调试、正则化以及优化
结构化机器学习项目
0、总结
参考:http://cs231n.stanford.edu/
X is of size[N x D] (N is the number of data, D is their dimensionality).
Mean subtraction
X -= np.mean(X, axis = 0)Normalization
X /= np.std(X, axis = 0)+1e-5PCA and Whitening
# Assume input data matrix X of size [N x D]
X -= np.mean(X, axis = 0) # zero-center the data (important)
cov = np.dot(X.T, X) / X.shape[0] # get the data covariance matrix
U,S,V = np.linalg.svd(cov)
Xrot = np.dot(X, U) # decorrelate the data
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced becomes [N x 100]
# whiten the data:
# divide by the eigenvalues (which are square roots of the singular values)
Xwhite = Xrot / np.sqrt(S + 1e-5)Weight Initialization
W = 0.01* np.random.randn(D,H),
w = np.random.randn(n) / sqrt(n), where n is the number of its inputs.
w = np.random.randn(n) * sqrt(2.0/n)lr
steps
batch_size 2^n(16~512)
隐藏节点数(满足2^n)
神经层数 重复以上4步
1、激活函数
tanh总比 sigmoid 效果好(隐藏层使用激活函数时)
使用tanh代替sigmoid
但是,sigmoid只用于最后输出层(二分类情况)
隐藏层 一般选Relu 修正的Relu
- 分类:
输出层 使用sigmoid(二分类)、softmax(多分类包括二分类)或者不使用任何激活函数; 隐藏层使用 relu、tanh等除sigmoid、softmax以外的激活函数
- 回归:
输出层 不使用任何激活函数 ; 隐藏层使用 relu、tanh等除sigmoid、softmax以外的激活函数
2、随机初始化
w=np.random.randn([2,2])*0.01
b=np.zero([2])
w不能初始化为0,应该初始化为比较小的数
b可以初始化为0
3、为什么使用深层表示
解决问题思路:
logistic 回归 —》 1~2层隐藏层—》调节参数+增加隐藏节点数—》加深层数和隐藏节点数
4、参数 VS 超参数
参数:
w,b
超参数:
learning rate
迭代次数
隐藏层数,隐藏单元数(隐藏节点数)
激活函数
minibatch_size
正则化参数
5、训练 、 开发 、 测试集
训练、验证、测试集划分
数据量较小 比例 60%:20%:20%, 如果只有训练和验证集(这种情况验证集也被称为测试集) 比例 70%:30%
数据量比较大,验证、测试集可以占总样本数的20%或10%以下
如果训练数据分辨率高,后期处理效果好,而测试或验证数据分辨率低,没有经过后期处理,这种情况,必须保训练集、证验证集和测试集来自同一分布
6、偏差 、方差
图像很模糊,人眼或者没法系统准确无误的识别图像 ,这种情况偏差会很大,重点查看训练集误差,完成训练集,开始验证集验证,判断方差是否过高。
训练集精度低,偏差比较大 欠学习
测试集比训练集低很大 出现过拟合 方差比较大 过学习
假设基本误差很小,训练集和验证集来自同一分布
7、机器学习基础
训练神经网络的基本方法,
初始化模型完成后,首先要知道算法的偏差高不高,
如果高,试着评估训练集或训练数据的性能,
如果偏差的确很高,甚至无法拟合一个样本,
那么就需要选择一个新的网络,如含有更多隐藏层或隐藏单元的网络
或者花更多的时间来训练网络,或尝试更先进的优化算法
不过采用规模更大的网络通常都会有所帮助,延长训练时间不一定有用,但也没有坏处
训练学习算法时,不断尝试这些方法,直到解决掉偏差问题,这是最低标准,反复尝试,直到拟合数据为止
图像
如果网络足够大,通常能很好的拟合训练集,只要你能扩大网络规模,
如果图像很模糊,算法可能无法拟合该图像,但是如果有人可以分辨出图像,
如果你觉得基本误差不是很高,那么训练一个更大的网络,你就应该可以,至少可以很好的拟合训练集
一旦偏差降低到可以接受的数值,检测方差有没有问题,
为了评估方差,我们要查看验证集性能,我们能从一个性能理想的训练集,推断出验证集的性能也理想?
如果方差高,最好的解决方法采用更多的数据,如果你能做到,会有一定的帮助,
如果没有更多数据,也可以尝试正则化来减少过拟合
如果能找到更加合适的神经网络框架,同时减少偏差和方差
不断尝试,直到找到一个低偏差和低方差的框架,
注意两点:
1、高偏差和高方差是两种不同情况
通常会使用训练验证集来诊断算法是否存在偏差或方差问题,
如果算法存在高偏差,准备更多训练数据其实没什么用,
2、在机器学习的初期阶段
采用更多数据通常可以在不过多影像偏差的同时,减少方差,
训练网络、选择网络或准备更多数据
现在有工具可以在减少偏差或方差的同时不对另一方产生过多不良影像
正则化,训练一个更大的网络几乎没有任何负面影像,主要代价就是计算时间,前提是网络比较规范化的
8、正则化
正则化 解决过拟合问题
另一种解决过拟合方法,准备更多的样本数据

lambda 是正则化参数,通常比较小
Dropout 正则化
对于可能出现过拟合,且含有诸多参数的层,可以将keep_prob设置成比较小的值
输入层和输出层不加 droupout
只有出现过拟合才使用droupout,如果没有就不要使用,通常在视觉处理中使用
其他正则化方法
如:数据增强(如图像旋转,上下左右翻转,调整对比度、亮度,随机裁剪、缩放等)得到更多训练样本
9、归一化输入
训练神经网络, 其中一个加速训练的方法就是归一化输入
归一化输入:
2个步骤:
1、零均值化
x=x-mean(x)
2、归一化方差
x=x/var(x)
x最后变成 均值为0,方差为1
训练集和测试集必须使用相同的 平均值和方差,而不能分别预估 平均值和方差
10、神经网络的权重初始化
初始化每一层权重
w[L]=np.random.randn(shape)*np.sqqrt(2/(n[L-1])) 红色部分为激活函数
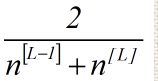
Relu激活函数:
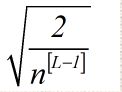
tanh激活函数:
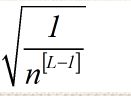
n表示该层神经元的输入特征数量
L表示神经层
n[L-1] 对应第L-1层的输入特征数, 输出层不计算
11、理解 mini-batch梯度下降法
m总样本数
mini_batch_size=m ;Batch 梯度下降
Batch 梯度下降 每次迭代需要大量的样本,如果训练样本太大,每次训练的时间太长,如果
训练样本不大,batch梯度下降法运行很好
mini_batch_size=1 ;随机 梯度下降 每个样本都是独立的mini batch
随机梯度下降法永远不会收敛,会一直在最小值附近波动,但它不会在达到最小值并停留在此
失去所有向量化带来的加速
mini_batch_size=1~m, 它不会总朝向最小值靠近,但它比随机梯度下降要更持续的靠近最小值方向,它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减小学习效率
如果训练集小(m<=2000),直接使用batch梯度下降 mini_batch_size=m
如果训练集大,一般mini_batch_size 取值范围64~512 (2^n) 64,128,256,512
12、动量梯度下降法
Momentum 梯度下降算法,运行速度快于标准的梯度下降算法
Momentum 梯度下降算法
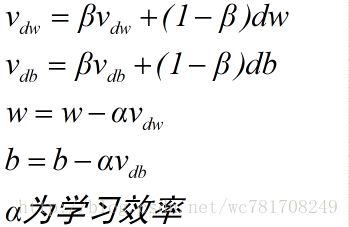
一般梯度下降算法

13、RMSprop
root mean square prop 加速梯度下降
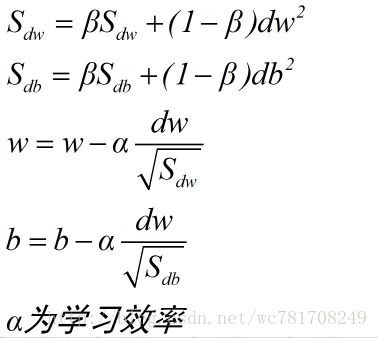

RMSprop和Momentum相似一点,可以消除梯度下降中的摆动,并且允许使用一个更大的学习效率,从而加快算法学习速度
14、Adam 优化算法
Adam优化算法基本上就是将 Momentum 和 RMSprop结合在一起,

15、学习率衰减

16、超参数训练的实践 Panda VS caviar
Babysitting one model
一次负担起试验一个模型或一小批模型
第0天 将随机参数初始化,然后逐渐观察自己的学习曲线或损失函数,或者数据设置误差或其他东西
第1天末 尝试增加学习效率,看看它会怎样,
每天观察它,不断调整参数
training many models in parallel
同时试验多种模型,设置一些超参数,
17、正则化网络的激活函数
输出层:使用以下公式进行归一化

隐藏层:
在使用激活函数之前 ,使用Batch_Norm
Btach归一化的作用是它适用的归一化过程不只是输入层,甚至同样适用于神经网络中的深层隐藏层

batch_norm 使隐藏单元值的均值和方差标准化
Batch_norm 可以和droupout一起使用
测试时,用到的均值和方差 都是训练集平均后的均值和方差
18、正交化
Fit training set well on cost function 否则 :(偏差大 欠学习) 更换网络,优化函数,归一化处理等
Fit dev set well on cost function 否则:(方差大 过拟合) 正则化,扩大样本
Fit test set well on cost function 否则:(方差大 过拟合) 扩大样本
Performs well in real world 否则: 改变训练集、cost函数
根据某个成本函数,系统在测试集上做的很好,但无法反映你的算法在现实世界中的表现,这意味着,你的开发集分布设置不正确,或者你的cost函数测量指标不对
19、开发集合测试集的大小


20、 什么时候该改变开发、测试集和指标
在当前开发集或开发集和测试集分布中表现很好,但在实际应用程序,你真正关注的地方表现不好,那就需要修改指标,或开发测试集
如果开发测试集都是质量高图像,但在开发测试集上做评估,无法预测你的实际表现,因为你的应用处理的是低质量图像,那么就应该改变你的开发测试集,让你的数据更能反映你实际需处理好的数据
但总体方针就是 ,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事关心不大,那就应该更改你的指标 或者你的开发/测试集,让它们能更好地反映你的算法需要处理好的数据
有一个评估指标和开发集让你可以更快做出决策,判断算法A还是算法B更优,这真的可以加速你和团队迭代速度
21、可避免偏差
人类识别错误率 1%
机器训练错误率 8%
Dev error 10%
8%>1%, 说明你的算法对训练集的拟合不够好,所以从减少偏差和方差的工具角度看,
重点放在减少偏差上,你需要做的是,如 训练更大的神经网络 或者 跑久一点梯度下降,
就试试能不能在训练集上做的更好
humans error 7.5% (数据中的图像非常模糊,人都无法辨别)
Training error 8%
Dev error 10%
这种情况,着重于加上算法的方差,如正则化,扩大样本
一般把人类识别误差近似为贝叶斯误差
贝叶斯误差估计和训练误差之间的差值,称为可避免偏差,如果希望提高训练集表现,直到接近贝叶斯误差,但实际上你也不希望做到比贝叶斯 误差更好,这理论上是不可能超过贝叶斯误差的,除非过拟合,
训练误差与开发误差之间的差值,就大概说明你的算法在方差问题上还有多少改善的空间
22、改善你的模型的表现
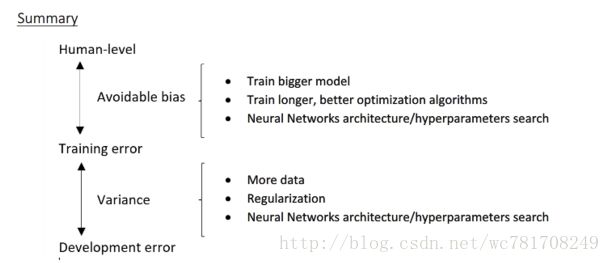
23、进行误差分析
猫分类器,查看算法分类出错的例子,注意到算法将一些狗分成猫,
一种建议做法,怎么针对狗的图片优化算法,如:针对狗,收集更多的狗图
或者设计一些只处理狗的算法功能
为了让你的猫分类器在狗图上做的更好,让算法不再将狗分类成猫,问题在于
你是不是应该去开始做一个项目专门处理狗?
误差分析:
首先收集 如:100个错误标记的开发集例子,手动检查,看看你的开发集里有多少错误标记的例子是狗,如果只有5%是狗,那么你在狗的问题上花更多时间,那么你的误差从10%降低到9.5%
性能上限,
如果发现50% 是狗,现在花时间去解决狗的问题可能效果就很好,可以集中精力减少
错误标记的狗的问题
24、清楚标注错误的数据
对于训练集
如果误差足够随机,那放着这些误差不管可能也没问题,而不要花太多时间去修复他们,有时修正这些是有价值的,有时放置不管也可以,只要总数据集足够大,实际误差可能不会太高,
深度学习算法对随机误差很鲁棒,但对系统性的错误就没那么鲁棒,如:做标记的人一直把白色的
狗标记成猫,那就成问题,因为你的分类器学习之后,会把所有白色的狗都分类成猫,但随机误差或
近似随机误差对于大多数深度学习算法来说不成问题
如果样本标记错误严重影响你在开发集上评估算法的能力,那么应该花时间修正错误的标签
必须同时对开发集和测试集做修正,(开发集和测试集必须来自相同的分布),开发集确定你的目标,当你击中目标后,在来自同一分布的开发集和测试集上迭代,如果你打算修正开发集上的部分数据,那么最好也对测试集做同样的修正,确保他们继续来自相同的分布
同时检验算法判断正确和判断错误的例子,检测算法出错的例子很容易,只需要看看那些例子是否需要修正,但是还有些例子没有判断对,那些也需要修正,如果你只修正算法出错的例子,你对算法的偏差估计可能会变大,这会让你的算法有点不公平的优势。我们就需要再次检查出错的例子,但也需要再次检查做对的例子
25、在不同的划分上进行训练
一组数据A 20W,另一组数据B 1w(最后模型要在该组数据上表现良好) 来自不同的分布
如:A是网络上下载的处理效果比较好的图像数据,B是手机拍摄的效果不是很好,我们期望是使用A、B数据建立的模型要对B效果好
方法一: 将两组数据合并到一起,随机分配到训练、开发和测试集中
20500 训练集 2500 开发集 2500测试集
好处:训练、开发和测试集都来自同一分布,这样更好管理
坏处:开发集中大部分都是来自于A数据(这样优化几乎是针对A数据),而我们的目标是针对B数据优化,这样目标发生偏离
这种数据划分 不行
方法二:
训练集 A+0.5B=20500
开发集 0.25B=2500
测试 0.25B=2500
26、不匹配数据划分的偏差和方差
humans error 0%
Training error 1%
Dev error 10%
如果训练、开发测试集都来自同一分布, 那主要是方差问题,过拟合
如果训练、开发测试集都来自不同分布,有可能开发集包含更难准确分类的图片,
当你看训练误差再看开发误差,有两件事变了,
1、算法只见过训练集数据,没有见过开发集数据(过拟合)
2、开发集数据来自不同的分布
解决方法:
训练集 分成 训练集和训练-开发集,
样本总的分成 训练集、训练-开发集、 开发集、 测试集
其中训练集 和训练开发集 满足同一分布
开发集和测试集满足同一分布
此时:
Training error 1%
Training-dev error 9%
dev error 10%
从Training error 1% 与Training-dev error 9%可以看出,算法存在方差问题(过拟合)
如果
Training error 1%
Training-dev error 1.5%
dev error 10%
此时是数据不匹配的问题,因为你的学习算法,没有直接在训练-开发集或开发集上训练过,但是这
两个数据集来自不同的分布,它在训练-开发集上做的很好,但在开发集上做的不好,所以你的算法
擅长处理和你关心的数据不同的分布,称之为数据不匹配问题
如果
humans error 0%
Training error 10%
Training-dev error 11%
dev error 12%
如果这种表现,那就存在偏差问题
Training error 10%
Training-dev error 11%
dev error 20%
存在两个问题
1、可避免偏差相当高
2、数据不匹配问题很大
humans error 4%
Training error 7%
Training-dev error 10%
dev error 12%
如果开发集与测试集误差相差很大,那就是在开发集发生过拟合,此时需要更大的开发集
开发集和测试集来自同一分布
27、定位数据不匹配
如果发现有严重的数据不匹配问题,做误差分析,了解训练集和开发测试集的具体差异
为了避免对测试集过拟合,要做误差分析,应该人工去看开发集而不是测试集
如 很多开发集样本噪声很多,有很多汽车噪声,这是你的开发集和训练集差异之一
当你了解开发集误差的性质时,你就知道开发集有可能跟训练集不同或者更难识别,那么
你可以尝试把训练数据变得更像开发集一点 或者 也可以收集更多类似你的开发集和测试集的训练数据
如果你发现汽车噪声是主要的误差来源,那么你可以模拟车辆噪声数据,加入到训练集里
如果你发现识别街牌号是主要误差来源,你可以有意识地收集很多人们说数字的音频数据,加
到你的训练集里
可以尝试收集更多和真正重要的场合相似的数据,这通常有助于解决很多问题
如果你的目标是让训练集更接近你的开发集
你可以利用的其中一种技术是,人工合成数据
人工合成一个潜在问题:
如:你在安静的背景中录的10000小时音频数据,然而你只录了1小时车辆背景噪声,那么
你可以这么做,将这1小时汽车噪声回放10000次,并叠加到在安静的背景下录的10000小时数据
但是有一个风险,有可能你的学习算法对这1小时汽车噪声过拟合
28、迁移学习(Transfer learning)
神经网络可以从一个任务中学的知识,并将这些知识应用到另一个独立的任务中
图像识别—迁移到 —-X射线扫描图识别
如: 你已经训练好一个神经网络,能够识别像猫这样的对应,然后使用那些知识或者部分学得的知识去帮助你更好地阅读X射线扫描图,这就是所谓的迁移学习
假设你已经训练好一个图形识别神经网络,如果你把这个神经网络拿来,适应或者
说迁移在不同任务中学到的知识,你可以做的是,把神经网络最后的输出层拿走,即删除掉,
并删除最后一层的权重,然后为最后一层重新赋予随机权重,然后让它在新的数据上训练
要实现迁移学习,把数据集换成新的x,y对(更换训练数据),初始化最后一层的权重,其他层的权重则是提取已经训练好的模型参数
如果你的新模型数据集很少,你可能只需要重新训练最后一层的权重,并保持其他参数不变,
如果你的数据足够多,你可以重新训练神经网络中剩下的所有层,
经验规则,如果你有一个小数据集,就只训练输出层前的最后一层,或者最后两层
如果你有很多数据,那么你可以重新训练网络中的所有参数,如果你重新训练神经网络中的所有参数,那么这个在图像识别数据的初期训练阶段,有时称为预训练,
因为你再用图像识别数据去预先初始化或者预训练神经网络的权重,然后,如果你以后更新所有权重,然后在放射科数据上训练,有时这个过程叫微调
把图像识别中学到的知识应用或迁移到放射科诊断上来,为什么这样有效果?
有很多低层次特征,比如说边缘检测,曲线检测,阳性对象检测,从非常大的图像识别数据库中学得的这些能力,可能有助于你的学习算法在放射科诊断中做的更好,算法学到了很多结构信息。图像形状信息,其中一些知识可能很有用,所以学会了图像识别,它就可能学到足够多的信息,可以了解不同图像的组成部分是怎样的,学到线条,点,曲线这些知识,也行对象的一小部分,这些知识有可能帮助你的放射科诊断网络,学习更快一些或者需要更少的学习数据
迁移学习,你可以不只加入一个新节点(如把输出节点替换掉),或者甚至往你的神经网络加入几个新层,这取决于你有多少数据,你可能只需重新训练网络的新层,也许你需要重新训练神经网络中更多的层
迁移学习起作用的场合是,迁移来源问题你有很多数据,但迁移目标问题没有那么多数据,
如:图像识别有100W个样本,放射扫描图有100个样本,所以你从图像识别训练中学到的很多知识可以迁移并且真正帮你加强放射科识别任务的性能,即使你的放射科数据很少,
如: 你有10000小时训练过你的语音识别系统,所以这10000小时数据学到很多人类声音的特征,但触发字检测(新模型)也许只有1小时数据,所以这数据太小,不能用来拟合很多参数,所以这种情况,预先学到很多人类声音的特征,人类语言的组成部分等等知识,可以帮你建立一个很好的唤醒字检测器,即使你的数据集相对很小,
从数据量多的问题迁移到数据量少的问题,然后反过来的话,迁移学习可能就没有意义了
29、多任务学习
多任务学习,使用多维标签同时训练多个模型,每一维标签对应一个类别,
如:自动驾驶中识别一张图像中 有没有 行人、交通标志、其他车辆、信号灯 共4类
可以使用这样的标签
labels=[0,1,0,1] # 4维标签 不是1维标签转成的one-hot标签
labels[0]=0 没有行人
labels[1]=1 有交通标志
labels[2]=0 无其他车辆
labels[3]=1 有信号灯
这样就能同时训练 行人、交通标志、其他车辆、信号灯4种模型
其loss函数参考如下:

一般的都是1维标签,如mnist数据集 10类 1维标签,1维标签的loss函数参考如下:

在实践中,多任务学习的使用频率要低于迁移学习
多任务学习就是你需要同时处理很多任务,都要做好,
多任务学习能让你训练一个神经网络来执行多个任务,这可以给你更高的性能,比单独完成各个任务更高的性能,
注:
如果每张图都对应唯一 一个标签(不存在多个标签对应问题),使用1维多分类标签 如:mnist数据集,cifar 数据集(1维标签)
如果一张图对应多个标签,如在做猫、狗检测 ,一张图里既有猫、狗 ,可以使用多维标签(多任务学习),labels=[1,0] 第一维表示图中有无猫 第二维表示图中有无狗
30、是否要使用端到端的深度学习
优点:
1、让数据说话,
如果你有足够多的x,y数据,那么不管从x到y最适合的函数映射是什么,如果你训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从x到y输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见
如:在语音识别邻域,
如果你让你的学习算法,学习它想学习的任意表示方式,而不是强迫你的算法使用音位作为表示方式,那么其整体表现可能更好
2、所需的手工设计的组件更少,简化设计工作流程
缺点:
1、需要大量的数据,要直接学到这个x到y的映射
2、排除了可能有用的手工设计组件