python爬虫学习之路(2)——selenium
浏览器渲染引擎
爬虫中有一种调用浏览器渲染引擎的爬取方法。就是模拟真正的上网方式去爬取html内容。这种方式不仅能够爬取静态网页的内容,还能爬取动态网页的内容。
Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,浏览器自动按照脚本代码做出单击、输入、打开、验证等操作,就像真正的用户在操作一样。
注意
新版本中使用Selenium调用浏览其渲染引擎需要下载geckodriver.exe
下载地址:https://github.com/mozilla/geckodriver/releases
使用Selenium打开一个网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'C:\Users\Documents\Python Scripts\webscrapy\geckodriver.exe')
driver.get('https://www.airbnb.cn/s/Shenzhen--China/homes?map_toggle=false&superhost=true')
driver.implicitly_wait(20) #等待响应,不超过20s
Selenium的脚本可以控制浏览器进行操作,可以实现多个浏览器的调用,包括IE(7、8、9、10、11)、Firefox、Safari、Google Chrome、Opera等,但常用的是Firefox浏览器。
结果如下:
使用Selenium获得网页内容
比如获得网页中的房源名称,查看网页源代码可以发现,房源信息的元素标签在一个class为_qrfr9x5的div中。
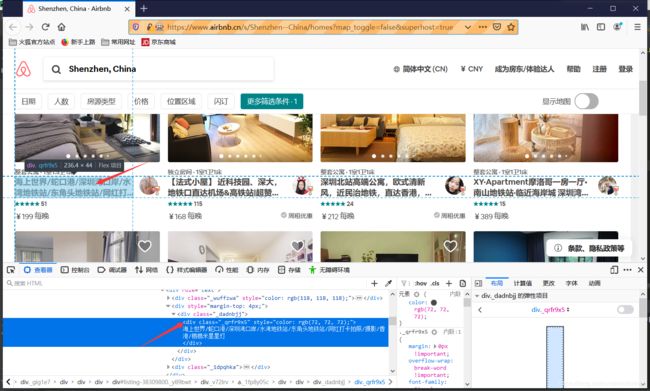 所以使用find_elements_by_css_selector()获得所有该标签的文本
所以使用find_elements_by_css_selector()获得所有该标签的文本
#获得房源名称
room_name = driver.find_elements_by_css_selector('div._qrfr9x5').text
Selenium选择元素的方法
上面使用的find_elements_by_css_selector()方法就是其中之一。
具体如下:
| 方法 | 描述 |
|---|---|
| find_element_by_css_selector | 通过元素的class选择,如find_element_by_css_selector ('div.bdy-inner') |
| find_element_by_xpath | 通过xpath选择,如driver.find_element_by_xpath("//form[@id='loginForm']") |
| find_element_by_id | 通过元素的id选择,如driver.find_element_by_id(' bdy-inner') |
| find_element_by_name | 通过元素的name选择,如driver.find_element_by_name('username') |
| find_element_by_partial_link_text | 通过链接地址选择,如Continue可以使用driver.find_element_by_link_text('Continue') |
| find_element_by_tag_name | 通过元素的名称选择,如driver.find_element_by_tag_name('h1') |
| find_element_by_class_name | 通过元素的class选择,如driver.find_element_by_class_name ('content') |
有时,需要查询同样的多个标签,这时就只需在上述对应方法的element后面加s,变成elements就OK。
Selenium操作元素的方法
常见方法如下:
| 方法 | 描述 |
|---|---|
| clear | 清楚元素内容 |
| send_keys() | 模拟按键输入 |
| click() | 模拟单击元素 |
| submit() | 提交表单 |
举例:163邮箱模拟登陆
打开网页
from selenium import webdriver
import time
diver = webdriver.Firefox(executable_path=r'C:\Users\wlx\Documents\Python Scripts\webscrapy\geckodriver.exe')
diver.get('https://mail.163.com/')
单击元素切换登陆方式
#因为163邮箱有扫码登陆和帐号密码登陆两种方式,默认是扫描登陆,所以这里先获得切换登陆方式的元素
app = diver.find_element_by_css_selector('div.new-loginFunc')
#使用单击方法click(),模拟单击了app元素,就能切换登陆方法
app.click()
#等待1秒,给浏览器刷新的时间
time.sleep(1)
定位帐号、密码以及登陆元素
然后定位帐号、密码以及登陆按钮的位置,发现着三个元素是在一个叫做iframe的标签中。
iframe
iframe 元素会创建包含另外一个文档的内联框架
也就是说在当前主docment中,又嵌入了一个子docment,这个子docment需要另外解析。

iframe解析方法
#解析iframe
iframe = diver.find_element_by_css_selector("iframe")
diver.switch_to.frame(iframe)
iframe释放的方法
#释放iframe
driver.switch_to.default_content()
iframe解析后,开始获取帐号、密码以及登陆按钮
#获取帐号元素
login_name = diver.find_element_by_xpath('//div[@id="account-box"]/div[2]/input')
#获取密码元素
login_password = diver.find_element_by_xpath('//input[@name="password"]')
#获取登陆按钮
login = diver.find_element_by_xpath('//a[@id="dologin"]')
模拟键盘输入
元素都获取后,就开始模拟输入和点击。
#输入帐号
login_name.send_keys('1234567890')
#输入密码
login_password.send_keys('*********')
#模拟点击登陆
login.click()
ok,实测成功。