前言:大家好,我叫邵威儒,大家都喜欢喊我小邵,学的金融专业却凭借兴趣爱好入了程序猿的坑,从大学买的第一本vb和自学vb,我就与编程结下不解之缘,随后自学易语言写游戏辅助、交易软件,至今进入了前端领域,看到不少朋友都写文章分享,自己也弄一个玩玩,以下文章纯属个人理解,便于记录学习,肯定有理解错误或理解不到位的地方,意在站在前辈的肩膀,分享个人对技术的通俗理解,共同成长!
后续我会陆陆续续更新javascript方面,尽量把javascript这个学习路径体系都写一下
包括前端所常用的es6、angular、react、vue、nodejs、koa、express、公众号等等
都会从浅到深,从入门开始逐步写,希望能让大家有所收获,也希望大家关注我~
文章列表:https://juejin.im/user/5a84f871f265da4e82634f2d/posts
小邵教你玩转nodejs系列:https://juejin.im/collection/5bae6ffbe51d452fa9ee497e
Author: 邵威儒
Email: [email protected]
Wechat: 166661688
github: https://github.com/iamswr/
十分抱歉,最近比较忙,临时需要把h5快速迁移到app,又不懂co swift android,基本每天都在踩坑当中,不过收获也很大,将来前端的趋势肯定是大前端,不管是pc 移动m站还是app 后端都需要懂一些,后面有时间,我也会把最近接触ios/android原生遇到的问题总结出来。
在这篇文章中,你会明白模块化的发展,明白以sea.js为代表的cmd规范和以require.js为代表的amd规范的异同,剖析node.js使用的commonJs规范的源码以及手写实现简陋版的commonJs,最后你会明白模块化是怎样一个加载过程。
Javascript最开始是怎样实现模块化呢?
我们知道javascript最开始是面向过程的思维编程,随着代码越来越庞大、复杂,在这种实际遇到的问题中,大佬们逐渐把面向对象、模块化的思想用在javascript当中。
一开始,我们是把不同功能写在不同函数当中
// 比如getCssAttr函数来获取Css属性,当我们需要获取Css属性的时候可以直接调用该方法
function getCssAttr(obj, attr) {
if (obj.currentStyle) {
return obj.currentStyle[attr];
} else {
return window.getComputedStyle(obj, null)[attr];
}
}
// 比如toJSON函数能够把url的query转为JSON对象
function toJSON(str) {
var obj = {}, allArr = [], splitArr = [];
str = str.indexOf('?') >= 0 ? str.substr(1) : str;
allArr = str.split('&');
for (var i = 0; i < allArr.length; i++) {
splitArr = allArr[i].split('=');
obj[splitArr[0]] = splitArr[1];
}
return obj;
}
这样getCssAttr函数和toJSON组成了模块,当需要使用的时候,直接调用即可,但是随着项目代码量越来越庞大和复杂,而且这种方式会对全局变量造成了污染。
为了解决上面的问题,会想到把这些方法、变量放到对象中
let utils = new Object({
getCssAttr:function(){...},
toJSON:function(){...}
})
当需要调用相应函数时,我们通过对象调用即可,utils.getCssAttr()、utils.toJSON(),但是这样会存在一个问题,就是可以直接通过外部修改内部方法属性。
utils.getCssAttr = null
那么我们有办法让内部方法属性不被修改吗?
答案是可以的,我们可以通过闭包的方式,使私有成员不暴露在外部。
let utils = (function(){
let getCssAttr = function(){...}
let toJSON = function(){...}
return {
getCssAttr,
toJSON
}
})()
这样的话,外部就无法改变内部的私有成员了。
CMD和AMD规范
试想一下,如果一个项目,所有轮子都自己造,在现在追求敏捷开发的环境下,我们有必要所有轮子都自己造吗?一些常用通用的功能,是否可以提取出来,供大家使用,提高开发效率?
正所谓,无规矩不成方圆,每个程序猿的代码风格肯定是有差异的,你写你的,我写我的,这样就很难流通了,但是如果大家都遵循一个规范编写代码,形成一个个模块,就显得非常重要了。
在这样的背景下,形成了两种规范,一种是以sea.js为代表的CMD规范,另外一种是以require.js为代表的AMD规范。
- CMD规范(Common Module Definition 通用模块定义)
- AMD规范(Asynchronous Module Definition 异步模块定义)
这一点一定要明白,非常重要!
这一点一定要明白,非常重要!
这一点一定要明白,非常重要!
在node.js中是遵循commonJS规范的,在对模块的导入是同步的,为什么这样说?因为在服务器中,模块都是存在本地的,即使要导入模块,也只是耗费了从硬盘读取模块的时间,而且可控。
但是在浏览器中,模块是需要通过网络请求获取的,如果是同步获取的话,那么网络请求的时间没办法保证,会造成浏览器假死的,但是异步的话,是不会阻塞主线程,所以不管是CMD还是AMD,都是属于异步的,CMD和AMD都是属于异步加载模块,当所需要依赖的模块加载完毕后,才通过一个回调函数,写我们所需要的业务逻辑。
CMD和AMD的异同
- CMD是
延迟执行,依赖就近,而AMD是提前执行,依赖前置(require2.0开始可以改成延迟执行),怎么理解呢?看看下面代码
// CMD
define(function(require,exports,module){
var a = require('./a')
a.run()
var b = require('./b')
b.eat()
})
// AMD
define(['./a','./b'],function(a,b){
a.run()
b.eat()
})
上面CMD和AMD都是异步获取到这些模块,但是加载的时机是不同的
CMD是使用的时候再进行加载
AMD则是执行回调函数之前就已经把模块加载了
这样的话会存在一个问题,就是在CMD执行的时候,require模块的时候,
因为要加载指定的模块,所以当执行到var a = require('./a')、var b = require('./b')
的时候,会稍微耗费多一些时间,也就是俗称的懒加载,所以CMD中执行
这个回调函数的时间会比AMD的快。
但是在AMD中,是预加载,意思就是执行回调函数之前就把依赖的模块都加载完了,
所以AMD执行回调函数的时间会比CMD慢,但是因为已经预加载了,在AMD执行回
调函数内的业务逻辑会比CMD快。
CMD AMD
执行回调函数的时机 快 慢
执行回调函数内的业务 慢 快

- 还有一些什么定位有差异、遵循的规范不同、推广理念有差异、对开发调试的支持有差异、插件机制不同等等就不衍生说了,最主要的还是前面说的那一条。
node.js遵循的commonJs规范
首先,我们来剖析一下commonJs的源码
我们分别创建两个文件useModule.js、module.js,并且打上断点。
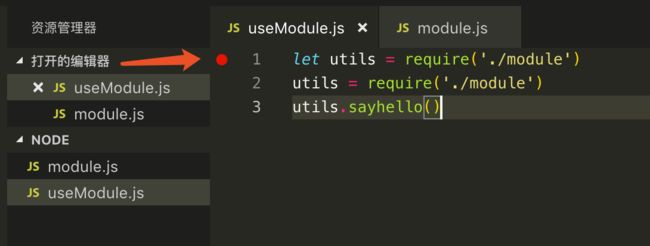
// useModule.js
let utils = require('./module')
utils = require('./module')
utils.sayhello()
// module.js
let utils = {
sayhello:function(){
console.log('hello swr')
}
}
module.exports = utils
然后开始执行,我们首先会进入commonJs的源码了
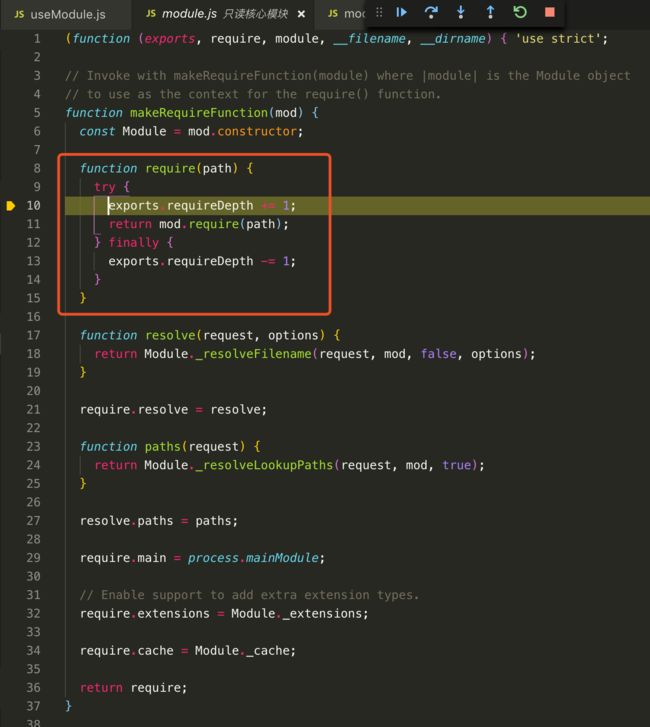
在最上面可以看出是一个闭包的形式(function(exports,require,module,__filename,__dirname)),这里可以看出__dirname和__filename并非是global上的属性,而是每个模块对应的路径。
而且我们在模块当中this并不是指向global的,而是指向module.exports,至于为什么会这样呢?下面会讲到。
在红框中,我们可以看到require函数,exports.requireDepth可以暂时不用管,是一个引用深度的变量,接下来我们往下看,return mod.require(path),这里的mod就是每一个文件、模块,而里面都有一个require方法,接下来我们看看mod.require函数内部是怎么写的。

进来后,我们会看到2个assert断言,用来判断path参数是否传递了,path是否字符串类型等等。
return Module._load(path,this,false),path为我们传入的模块路径,this则是这个模块,false则不是主要模块,主要模块的意思是,如果a.js加载了b.js,那么a.js是主要模块,而b.js则是非主要模块。
接下来我们看看Module._load这个静态方法
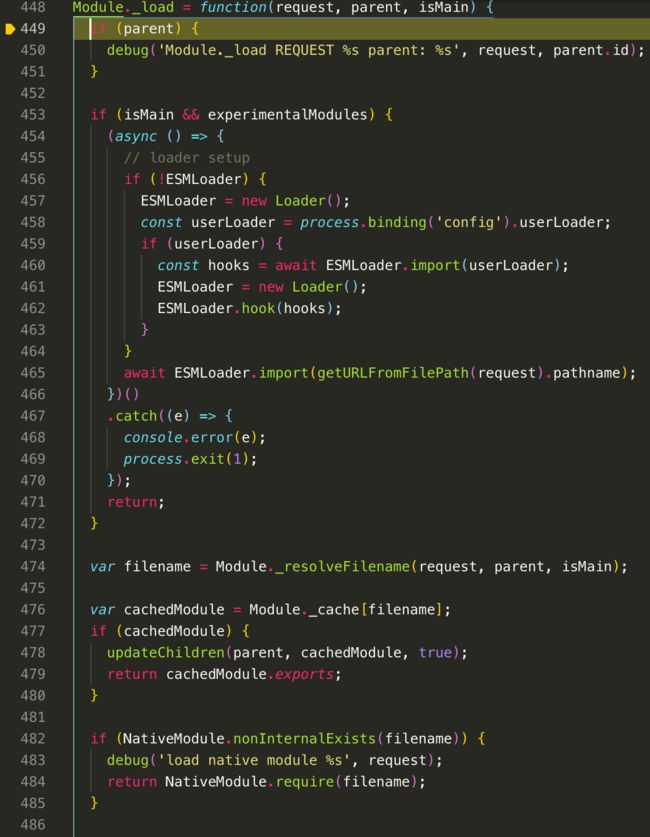
var filename = Module._resolveFilename(request, parent, isMain),这里的目的是解析出一个绝对路径,我们可以进去看看Module._resolveFilename函数是怎么写的

Module._resolveFilename函数也没什么好说的,就是判断各种情况,然后解析出一个绝对路径出来,我们跳出这个函数,回到Module._load中
然后我们看到var cachedModule = Module._cache[filename],这是我们加载模块的缓存机制,就是说我们加载过一次模块后,会缓存到Module._cache这个对象中,并且是以filename作为键名,因为路径是唯一的,所以以路径作为唯一标识,如果已经缓存过,则会直接返回这个缓存过的模块。
NativeModule.nonInternalExists(filename)判断是否原生模块,是的话则直接返回模块。
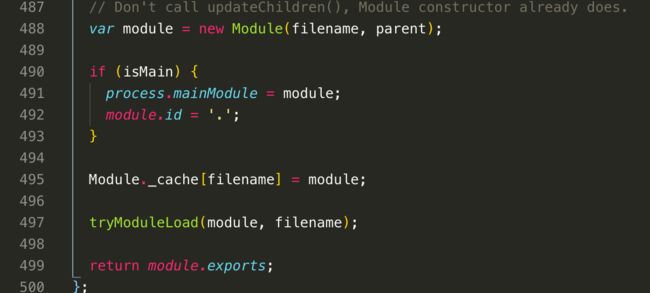
经过上面两个判断,基本可以判定这个模块没被加载过,那么接下来看到var module = new Module(filename, parent),创建了一个模块,我们看看Module这个构造函数有什么内容
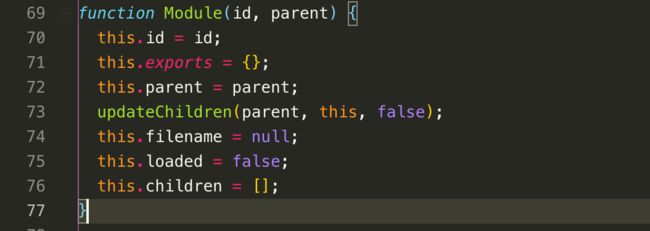
这里的id,实际上就是filename唯一路径,另外一个很重要的是this.exports,也就是将来用于暴露模块的。
我们接着往下看,在创建一个实例后,接下来把这个实例存在缓存当中,Module._cache[filename] = module
然后执行tryModuleLoad(module, filename),这个函数非常重要,是用来加载模块的,我们看看是怎么写的

这里有个module.load,我们再往里面看看是怎么写的
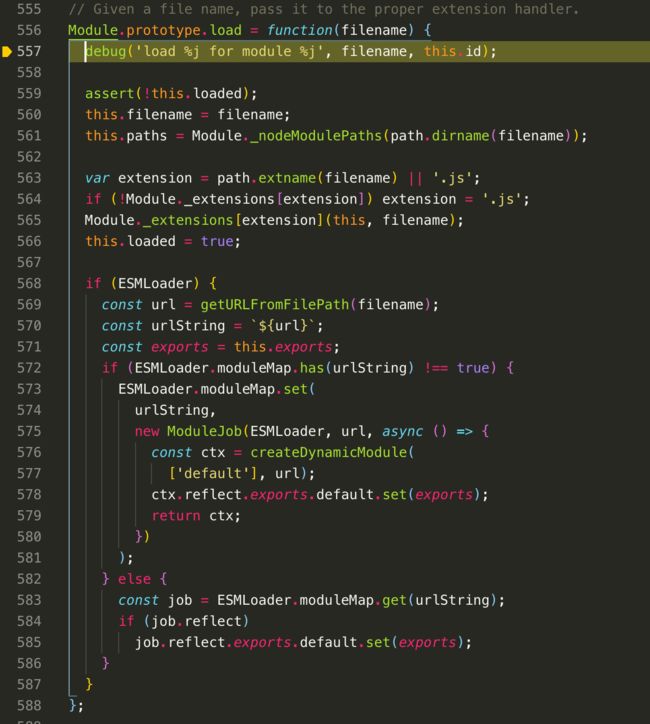
兜兜转转,终于来到最核心的地方了
this.paths = Module._nodeModulePaths(path.dirname(filename)),我们知道,我们安装npm包时,node会由里到外一层层找node_modules文件夹,而这一步,则是路径一层层丢进数组里,我们可以看看this.paths的数组

继续往下看,var extension = path.extname(filename) || '.js'是获取后缀名,如果没有后缀名的话,暂时默认添加一个.js后缀名。
继续往下看,if (!Module._extensions[extension]) extension = '.js'是判断Module._extensions这个对象,是否有这个属性,如果没有的话,则让这个后缀名为.js
继续往下看,Module._extensions[extension](this, filename),根据后缀名,执行对应的函数,那么我们看一下Module._extensions对象有哪几个函数
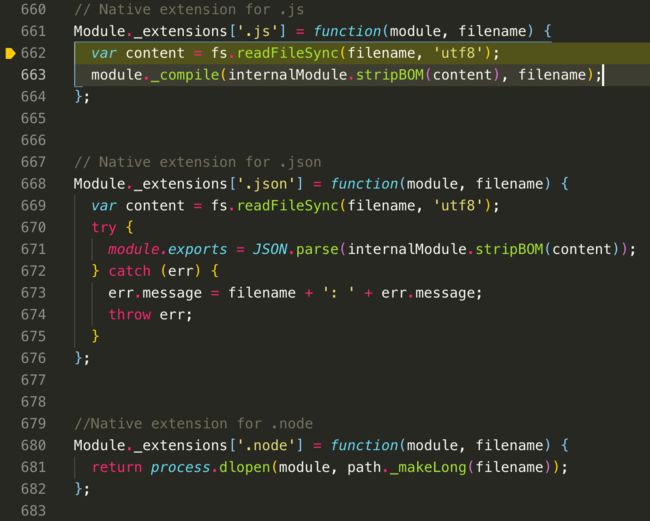
从这里我们可以看到,Module._extensions中有3个函数,分别是.js、.json、.node函数,意思是根据不同的后缀名,执行不同的函数,来解析不同的内容,我们可以留意到读取文件都是用fs.readFileSync同步读取,因为这些文件都是保存在服务器硬盘中,读取这些文件耗费时间非常短,所以采用了同步而不是异步
其中.json最为简单,读取出文件后,再通过JSON.parse把字符串转化为JSON对象,然后把结果赋值给module.exports
接下来看看.js,也是一样先读取出文件内容,然后通过module._compile这个函数来解析.js的内容,我们看一下module._compile函数怎么写的
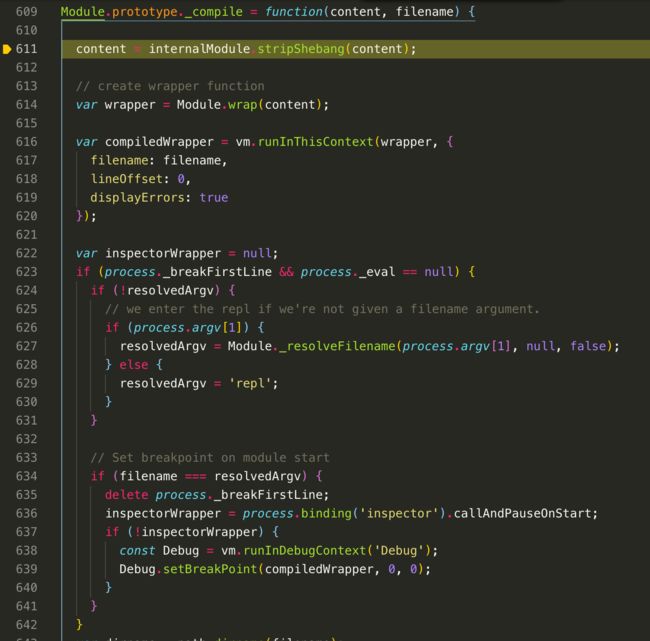
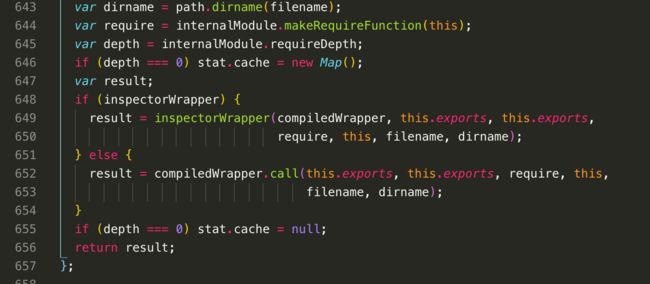
var wrapper = Module.wrap(content)这里对.js文件的内容进行了一层处理,我们可以看看Module.wrap怎么写的
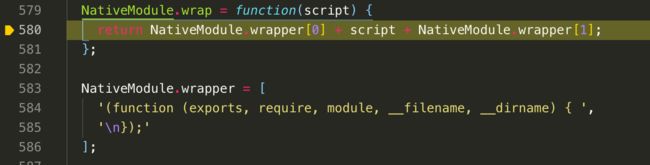
在这里可以看出,NativeModule.wrapper数组中有两个数组成员,是不是看起来似曾相识?没错,这就是闭包的形式,而Module.wrap中,是直接把js文件的内容,和这个闭包拼接成一段字符串,对,就是在这里,把一个个模块,套一层闭包!实际上拼接出来的是
// 字符串
"(function(exports,require,module,__filename,__dirname){
let utils = {
sayhello:function(){
console.log('hello swr')
}
}
})"
我们跳出来,回到Module.prototype._compile看看,接下来看到var compiledWrapper = vm.runInThisContext(wrapper,{...}),在nodejs中是通过vm这个虚拟机,执行字符串,而且这样的好处是使内部完全是封闭的,不会被外在变量污染,而在前端的字符串模板则是通过new Function()来执行字符串,达到不被外在变量污染
继续往下看,result = compiledWrapper.call(this.exports, this.exports, require, this,filename, dirname),其中compiledWrapper就是我们通过vm虚拟机执行的字符串后返回的闭包,而且通过call来把这个模块中的this指向更改为当前模块,而不是全局的global,这里就是为什么我们在模块当中打印this时,指向的是当前的module.exports而不是global,然后后面依次把相应的参数传递过去
最终一层层跳出后Module._load中,最后是return module.exports,也就是说我们通过require导入的模块,取的是module.exports
通过剖析commonJs源码,我们收获了什么?
- 懂得了模块加载的整个流程
- 第一步:解析出一个绝对路径
- 第二步:如文件没添加后缀,则添加
.js、.json、.node作为后缀,然后通过fs.existsSync来判断文件是否存在 - 第三步:到缓存中找该模块是否被加载过
- 第四步:new一个模块实例
- 第五步:把模块存到缓存当中
- 第六步:根据后缀名,加载这个模块
- 知道如何实现由里到外一层层查找
node_modules - 知道针对
.js和.json是怎么解析的-
.js是通过拼接字符串,形成一个闭包形式的字符串 -
.json则是通过JSON.parse转为JSON对象
-
- 知道如何执行字符串,并且不受外部变量污染
- nodejs中通过vm虚拟机来执行字符串
- 前端则是通过
new Function()来执行字符串
- 知道为什么模块中的
this指向的是this.exports而不是global- 通过
call把指针指向了this.exports
- 通过
曾经有个小伙伴问我,在vue中,想在export default{}外读取里面的data的值
首先,我们知道,.vue文件在vue当中相当于一个模块,而模块的this是指向于exports,那么我们可以打印出this看看是什么
打印出来是这样的

那么就是说this.a.data则是data函数了,
那么我们执行this.a.data(),返回了{name:"邵威儒"}
所以当我们了解这个模块化的源码后,会为我们工作当中解决问题,提供了思路的
接下来,我们手写一个简陋版的commonJs源码
commonJs其实在加载模块的时候,做了以下几个步骤
- 第一步:解析出一个绝对路径
- 第二步:如文件没添加后缀,则添加
.js、.json、.node作为后缀,然后通过fs.existsSync来判断文件是否存在 - 第三步:到缓存中找该模块是否被加载过
- 第四步:new一个模块实例
- 第五步:把模块存到缓存当中
- 第六步:根据后缀名,加载这个模块
那么我们根据这几个步骤,来手写一下源码~
// module.js
let utils = {
sayhello: function () {
console.log('hello swr')
}
}
console.log('执行了')
module.exports = utils
首先写出解析一个绝对路径以及如文件没添加后缀,则添加.js、.json作为后缀,然后通过fs.existsSync来判断文件是否存在( .. 每个步骤我都会标识1、2、3…
// useModule.js
// 1.引入核心模块
let fs = require('fs')
let path = require('path')
// 3.声明一个Module构造函数
function Module(id) {
this.id = id
this.exports = {} // 将来暴露模块的内容
}
// 8.支持的后缀名类型
Module._extensions = {
".js":function(){},
".json":function(){}
}
// 5.解析出绝对路径,_resolveFilename是Module的静态方法
Module._resolveFilename = function (relativePath) {
// 6.返回一个路径
let p = path.resolve(__dirname,relativePath)
// 7.该路径是否存在文件,如果存在则直接返回
// 这种情况主要考虑用户自行添加了后缀名
// 如'./module.js'
let exists = fs.existsSync(p)
if(exists) return p
// 9.如果relativePath传入的如'./module',没有添加后缀
// 那么我们给它添加后缀,并且判断添加后缀后是否存在该文件
let keys = Object.keys(Module._extensions)
let r = false
for(let val of keys){ // 这里用for循环,是当找到文件后可以直接break跳出循环
let realPath = p + val // 拼接后缀
let exists = fs.existsSync(realPath)
if(exists){
r = realPath
break
}
}
if(!r){ // 如果找不到文件,则抛出错误
throw new Error('file not exists')
}
return r
}
// 2.为了不与require冲突,这个函数命名为req
// 传入一个参数p 路径
function req(p) {
// 10.因为Module._resolveFilename存在找不到文件
// 找不到文件时会抛出错误,所以我们这里捕获错误
try {
// 4.通过Module._resolveFilename解析出一个绝对路径
let filename = Module._resolveFilename(p)
} catch (e) {
console.log(e)
}
}
// 导入模块,并且导入两次,主要是校验是否加载过一次后
// 在有缓存的情况下,会不会直接返回缓存的模块
// 为此特意在module.js中添加了console.log("执行了")
// 来看打印了几次
let utils = require('./module')
utils = require('./module')
utils.sayhello()
然后到缓存中找该模块是否被加载过,如果没有加载过则new一个模块实例,把模块存到缓存当中,最后根据后缀名,加载这个模块( .. 每个步骤我都会标识1、2、3…
// useModule.js
// 1.引入核心模块
let fs = require('fs')
let path = require('path')
// 3.声明一个Module构造函数
function Module(id) {
this.id = id
this.exports = {} // 将来暴露模块的内容
}
// * 21.因为处理js文件时,需要包裹一个闭包,我们写一个数组
Module.wrapper = [
"(function(exports,require,module){",
"\n})"
]
// * 22.通过Module.wrap包裹成闭包的字符串形式
Module.wrap = function(script){
return Module.wrapper[0] + script + Module.wrapper[1]
}
// 8.支持的后缀名类型
Module._extensions = {
".js":function(module){ // * 20.其次看看js是如何处理的
let str = fs.readFileSync(module.id,'utf8')
// * 23.通过Module.wrap函数把内容包裹成闭包
let fnStr = Module.wrap(str)
// * 24.引入vm虚拟机来执行字符串
let vm = require('vm')
let fn = vm.runInThisContext(fnStr)
// 让产生的fn执行,并且把this指向更改为当前的module.exports
fn.call(this.exports,this.exports,req,module)
},
".json":function(module){ // * 18.首先看看json是如何处理的
let str = fs.readFileSync(module.id,'utf8')
// * 19.通过JSON.parse处理,并且赋值给module.exports
let json = JSON.parse(str)
module.exports = json
}
}
// * 15.加载
Module.prototype._load = function(filename){
// * 16.获取后缀名
let extension = path.extname(filename)
// * 17.根据不同后缀名 执行不同的方法
Module._extensions[extension](this)
}
// 5.解析出绝对路径,_resolveFilename是Module的静态方法
Module._resolveFilename = function (relativePath) {
// 6.返回一个路径
let p = path.resolve(__dirname,relativePath)
// 7.该路径是否存在文件,如果存在则直接返回
// 这种情况主要考虑用户自行添加了后缀名
// 如'./module.js'
let exists = fs.existsSync(p)
if(exists) return p
// 9.如果relativePath传入的如'./module',没有添加后缀
// 那么我们给它添加后缀,并且判断添加后缀后是否存在该文件
let keys = Object.keys(Module._extensions)
let r = false
for(let val of keys){ // 这里用for循环,是当找到文件后可以直接break跳出循环
let realPath = p + val // 拼接后缀
let exists = fs.existsSync(realPath)
if(exists){
r = realPath
break
}
}
if(!r){ // 如果找不到文件,则抛出错误
throw new Error('file not exists')
}
return r
}
// * 11.缓存对象
Module._cache = {}
// 2.为了不与require冲突,这个函数命名为req
// 传入一个参数p 路径
function req(p) {
// 10.因为Module._resolveFilename存在找不到文件
// 找不到文件时会抛出错误,所以我们这里捕获错误
try {
// 4.通过Module._resolveFilename解析出一个绝对路径
let filename = Module._resolveFilename(p)
// * 12.判断是否有缓存,如果有缓存的话,则直接返回缓存
if(Module._cache[filename]){
// * 因为实例的exports才是最终暴露出的内容
return Module._cache[filename].exports
}
// * 13.new一个Module实例
let module = new Module(filename)
// * 14.加载这个模块
module._load(filename)
// * 25.把module存到缓存
Module._cache[filename] = module
// * 26.返回module.exprots
return module.exports
} catch (e) {
console.log(e)
}
}
// 导入模块,并且导入两次,主要是校验是否加载过一次后
// 在有缓存的情况下,会不会直接返回缓存的模块
// 为此特意在module.js中添加了console.log("执行了")
// 来看打印了几次
let utils = req('./module')
utils = req('./module')
utils.sayhello()
这样我们就完成了一个简陋版的commonJs,而且我们多次导入这个模块,只会打印出一次执行了,说明了只要缓存中有的,就直接返回,而不是重新加载这个模块
这里建议大家一个步骤一个步骤去理解,尝试敲一下代码,这样感悟会更加深
那么为什么exports = xxx 却失效了呢?
// 从上面源码我们可以看出,实际上
// exports = module.exports = {}
// 但是当我们exports = {name:"邵威儒"}时,
// require出来却获取不到这个对象,这是因为我们在上面源码中,
// req函数(即require)内部return出的是module.exports,而不是exports,
// 当我们exports = { name:"邵威儒" }时,实际上这个exports指向了一个新的对象,
// 而不是module.exports
// 那么我们的exports是不是多余的呢?肯定不是多余的,我们可以这样写
exports.name = "邵威儒"
// 这样写没有改变exports的指向,而是在exports指向的module.exports对象上新增了属性
// 那么什么时候用exports,什么时候用module.exports呢?
// 如果导出的东西是一个,那么可以用module.exports,如果导出多个属性可以用exports,
// 一般情况下是用module.exports
// 还有一种方式,就是把属性挂载到global上供全局访问,不过不推荐。