一、上讲总结
你好,我是倪朋飞。
在访问商品搜索接口时,我们发现接口的响应特别慢。通过对系统 CPU、内存和磁盘 I/O等资源使用情况的分析,我们发现这时出现了磁盘的 I/O 瓶颈,并且正是案例应用导致的。
接着,我们借助 pidstat,发现罪魁祸首是 mysqld 进程。我们又通过 strace、lsof,找出了 mysqld 正在读的文件。根据文件的名字和路径,我们找出了 mysqld 正在操作的数据
库和数据表。综合这些信息,我们猜测这是一个没利用索引导致的慢查询问题。
为了验证猜测,我们到 MySQL 命令行终端,使用数据库分析工具发现,案例应用访问的字段果然没有索引。既然猜测是正确的,那增加索引后,问题就自然解决了。
从这个案例你会发现,MySQL 的 MyISAM 引擎,主要依赖系统缓存加速磁盘 I/O 的访问。可如果系统中还有其他应用同时运行, MyISAM 引擎很难充分利用系统缓存。缓
存可能会被其他应用程序占用,甚至被清理掉。
所以,一般我并不建议,把应用程序的性能优化完全建立在系统缓存上。最好能在应用程序的内部分配内存,构建完全自主控制的缓存;或者使用第三方的缓存应用,
比如Memcached、Redis 等。
Redis 是最常用的键值存储系统之一,常用作数据库、高速缓存和消息队列代理等。Redis基于内存来存储数据,不过,为了保证在服务器异常时数据不丢失,很多情况下,我们要
为它配置持久化,而这就可能会引发磁盘 I/O 的性能问题。
今天,我就带你一起来分析一个利用 Redis 作为缓存的案例。这同样是一个基于 PythonFlask 的应用程序,它提供了一个 查询缓存的接口,但接口的响应时间比较长,并不能满
足线上系统的要求。
非常感谢携程系统研发部资深后端工程师董国星,帮助提供了今天的案例
二、案例准备
1、系统运行环境
本次案例还是基于 Ubuntu 18.04,同样适用于其他的 Linux 系统。我使用的案例环境如下所示:
机器配置:2 CPU,8GB 内存 预先安装 docker、sysstat 、git、make 等工具,如 apt install docker.io sysstat
2、服务运行环境
今天的案例由 Python 应用 +Redis 两部分组成。其中,Python 应用是一个基于 Flask 的应用,它会利用 Redis ,来管理应用程序的缓存,并对外提供三个 HTTP 接口:
/:返回 hello redis; /init/:插入指定数量的缓存数据,如果不指定数量,默认的是 5000 条; 缓存的键格式为 uuid: 缓存的值为 good、bad 或 normal 三者之一 /get_cache/:查询指定值的缓存数据,并返回处理时间。其中, type_name 参数只支持 good, bad 和 normal(也就是找出具有相同 value 的 key 列 表)。
由于应用比较多,为了方便你运行,我把它们打包成了两个 Docker 镜像,并推送到了Github 上。这样你就只需要运行几条命令,就可以启动了。
3、服务架构图
今天的案例需要两台虚拟机,其中一台用作案例分析的目标机器,运行 Flask 应用,它的IP 地址是 192.168.118.74;而另一台作为客户端,请求缓存查询接口。我画了一张图来表示
它们的关系。
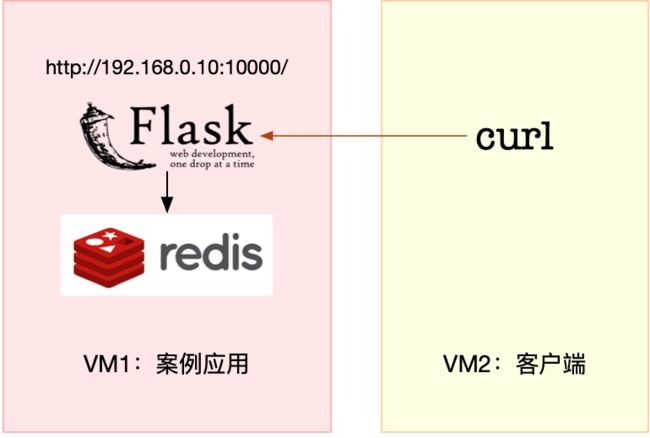
接下来,打开两个终端,分别 SSH 登录到这两台虚拟机中,并在第一台虚拟机中安装上述工具。
跟以前一样,案例中所有命令都默认以 root 用户运行,如果你是用普通用户身份登陆系统,请运行 sudo su root 命令切换到 root 用户。
到这里,准备工作就完成了。接下来,我们正式进入操作环节。
三、案例运行发现问题
1、案例环境运行
首先,我们在第一个终端中,执行下面的命令,运行本次案例要分析的目标应用。正常情况下,你应该可以看到下面的输出:
root@luoahong:/etc/docker# docker run --name=app --network=container:redis -itd feisky/redis-app Unable to find image 'feisky/redis-app:latest' locally latest: Pulling from feisky/redis-app 54f7e8ac135a: Pull complete d6341e30912f: Pull complete 087a57faf949: Pull complete 5d71636fb824: Pull complete 0c1db9598990: Pull complete 2eeb5ce9b924: Pull complete d3029c597b32: Pull complete 265a9c957eba: Pull complete 3bb7ae9463c5: Pull complete b3198935e7ab: Pull complete ca3ab58d03d9: Pull complete Digest: sha256:ac281cbb37e35eccb880a58b75f244ef19a9a8704a43ae274c12e6576ed6082b Status: Downloaded newer image for feisky/redis-app:latest 92205779ad2327750b59ea3ed8e30ed6d8455cb1302cd00c278cdbeaa4c85c6e root@luoahong:~# docker run --name=redis -itd -p 10000:80 feisky/redis-server Unable to find image 'feisky/redis-server:latest' locally latest: Pulling from feisky/redis-server cd784148e348: Pull complete 48d4c7155ddc: Pull complete 6d908603dbe8: Pull complete 0b981e82e1e2: Pull complete 7074f4a1fd03: Pull complete 447ac2b250dc: Pull complete b6d44ce71e94: Pull complete Digest: sha256:a69d39256eb970ab0d87a70d53fa2666d0c32cbf68fb316ef016efd513806146 Status: Downloaded newer image for feisky/redis-server:latest 09909c2e6853624b876e5ea85ac088947411e50dbc4e74158db0c6d4723d947d
然后,再运行 docker ps 命令,确认两个容器都处于运行(Up)状态:
root@luoahong:~# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 062b658d80d5 feisky/redis-app "python /app.py" 5 seconds ago Up 5 seconds app 9e6d1b994c71 feisky/redis-server "docker-entrypoint.s…" 12 seconds ago Up 11 seconds 6379/tcp, 0.0.0.0:10000->80/tcp redis
今天的应用在 10000 端口监听,所以你可以通过 http://192.168.118.74:10000 ,来访问前面提到的三个接口。
比如,我们切换到第二个终端,使用 curl 工具,访问应用首页。如果你看到 helloredis 的输出,说明应用正常启动:
[root@luoahong ~]# curl http://192.168.118.74:10000/ hello redis
接下来,继续在终端二中,执行下面的 curl 命令,来调用应用的 /init 接口,初始化Redis 缓存,并且插入 5000 条缓存信息。这个过程比较慢,比如我的机器就花了十几分钟时间。
耐心等一会儿后,你会看到下面这行输出:
root@luoahong:~# curl http://192.168.118.74:10000/init/5000
{"elapsed_seconds":88.31499242782593,"keys_initialized":5000}
2、发现问题
继续执行下一个命令,访问应用的缓存查询接口。如果一切正常,你会看到如下输出:
[root@luoahong ~]# curl http://192.168.118.74:10000/get_cache
c110002","14f7eeb8-838d-11e9-af71-0242ac110002","1ebceac0-838d-11e9-af71-0242ac110002","198488ba-838d-11e9-af71-0242ac110002"],
"elapsed_seconds":29.865149974822998,"type":"good"}
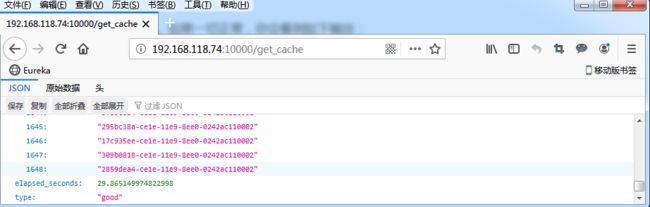
我们看到,这个接口调用居然要花 29 秒!这么长的响应时间,显然不能满足实际的应用需求。
四、问题定位过程
到底出了什么问题呢?我们还是要用前面学过的性能工具和原理,来找到这个瓶颈。不过别急,同样为了避免分析过程中客户端的请求结束,在进行性能分析前,我们先要把
curl 命令放到一个循环里来执行。你可以在终端二中,继续执行下面的命令:
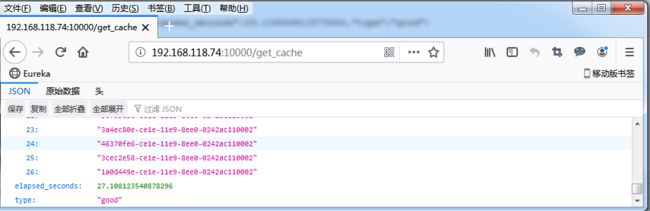
curl http://192.168.118.74:10000/get_cache
{"count":1677,"data":["d97662fa-06ac-11e9-92c7-0242ac110002",...],"elapsed_seconds":29.109556913375854,"type":"good"}
接下来,再重新回到终端一,查找接口响应慢的“病因”。最近几个案例的现象都是响应很慢,这种情况下,我们自然先会怀疑,是不是系统资源出
现了瓶颈。所以,先观察 CPU、内存和磁盘 I/O 等的使用情况肯定不会错。我们先在终端一中执行 top 命令,分析系统的 CPU 使用情况:
1、CPU0 的 iowait 比较高的定位
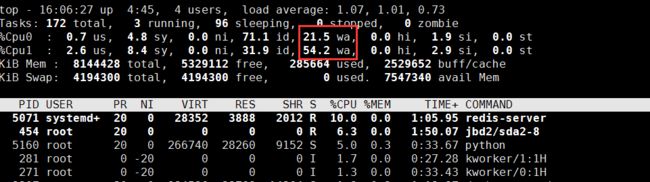
观察 top 的输出可以发现:
1、CPU1 的 iowait 比较高,已经达到了 54.2%;而各个进程的CPU 使用率都不太高,最高的 python 和 redis-server ,也分别只有 10% 和 6.3%。
2、再看内存,总内存 8GB,剩余内存还有 5GB 多,显然内存也没啥问题。
综合 top 的信息,最有嫌疑的就是 iowait。所以,接下来还是要继续分析,是不是 I/O 问题。
还在第一个终端中,先按下 Ctrl+C,停止 top 命令;然后,执行下面的 iostat 命令,查看有没有 I/O 性能问题:
root@luoahong:~# iostat -d -x 1 Linux 4.15.0-48-generic (luoahong) 09/03/2019 _x86_64_ (2 CPU) Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.06 0.00 0.00 0.00 0.00 0.00 42.64 0.00 0.00 22.55 0.00 5.53 0.00 loop1 0.43 0.00 0.49 0.00 0.00 0.00 0.00 0.00 3.08 0.00 0.00 1.14 0.00 0.15 0.01 loop2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.60 0.00 0.00 0.00 sda 0.55 20.17 18.63 228.09 0.07 12.06 11.40 37.41 15.50 10.67 0.22 33.90 11.31 4.76 9.87 scd0 0.01 0.00 0.18 0.00 0.00 0.00 0.00 0.00 0.58 0.00 0.00 22.35 0.00 0.58 0.00 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 loop2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 186.00 0.00 1008.00 0.00 66.00 0.00 26.19 0.00 4.17 0.79 0.00 5.42 4.24 78.80 scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
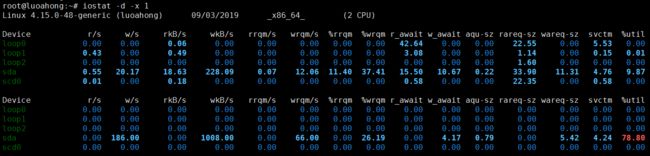
观察 iostat 的输出,我们发现:
1、磁盘 sda 每秒的写数据(wkB/s)为 2.5MB左右,I/O 使用率(%util)是 0。看来,虽然有些 I/O 操作,但并没导致磁盘的 I/O 瓶颈。
这里我和老师的不太一致、我的是磁盘 sda 每秒的写数据(wkB/s)为 1MB左右,I/O 使用率(%util)是 78、可能是环境原因导致把
排查一圈儿下来,CPU 和内存使用没问题,I/O 也没有瓶颈,接下来好像就没啥分析方向了?
2、看着明明有问题但是查了一圈都没问题怎嘛办呀
碰到这种情况,还是那句话,反思一下,是不是又漏掉什么有用线索了。你可以先自己思考一下,从分析对象(案例应用)、系统原理和性能工具这三个方向下功夫,回忆它们的
特性,查找现象的异常,再继续往下走。
回想一下,今天的案例问题是从 Redis 缓存中查询数据慢。对查询来说,对应的 I/O 应该是磁盘的读操作,但刚才我们用 iostat 看到的却是写操作。虽说 I/O 本身并没有性能瓶颈,但这里的磁盘写也是比较奇怪的。为什么会有磁盘写呢?那我们就得知道,到底是哪个进程在写磁盘。
1、 I/O 请求来自哪些进程
要知道 I/O 请求来自哪些进程,还是要靠我们的老朋友 pidstat。在终端一中运行下面的pidstat 命令,观察进程的 I/O 情况:
root@luoahong:~# pidstat -d 1 Linux 4.15.0-48-generic (luoahong) 09/03/2019 _x86_64_ (2 CPU) 04:09:14 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 04:09:15 PM 0 454 0.00 0.00 0.00 11 jbd2/sda2-8 04:09:15 PM 100 5071 0.00 236.89 0.00 61 redis-server 04:09:15 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 04:09:16 PM 0 454 0.00 0.00 0.00 17 jbd2/sda2-8 04:09:16 PM 100 5071 0.00 192.00 0.00 58 redis-server
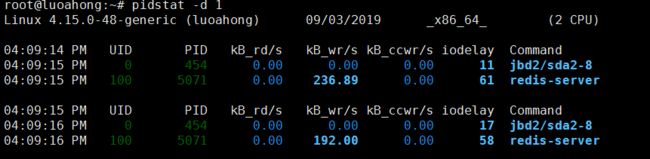
从 pidstat 的输出,我们看到:
1、I/O 最多的进程是 PID 为 5071 的 redis-server,并且它也刚好是在写磁盘。这说明,确实是 redis-server 在进行磁盘写。
2、strace+lsof 组合,看看 redis-server 到底在写什么?
当然,光找到读写磁盘的进程还不够,我们还要再用 strace+lsof 组合,看看 redis-server 到底在写什么。
接下来,还是在终端一中,执行 strace 命令,并且指定 redis-server 的进程号 5071:
root@luoahong:~# strace -f -T -tt -p 5071 strace: Process 5071 attached with 4 threads [pid 5131] 16:17:36.906134 futex(0x7fb4561f6124, FUTEX_WAIT_PRIVATE, 2, NULL[pid 5130] 16:17:36.906372 futex(0x7fb4566fa124, FUTEX_WAIT_PRIVATE, 2, NULL [pid 5129] 16:17:36.906418 futex(0x7fb456bfe124, FUTEX_WAIT_PRIVATE, 2, NULL [pid 5071] 16:17:36.914377 write(8, ":1\r\n", 4) = 4 <0.000123> [pid 5071] 16:17:36.914647 clock_gettime(CLOCK_REALTIME, {tv_sec=1567498656, tv_nsec=914744687}) = 0 <0.000045> [pid 5071] 16:17:36.914804 epoll_pwait(5, [], 10128, 0, NULL, 8) = 0 <0.000027> [pid 5071] 16:17:36.914889 clock_gettime(CLOCK_REALTIME, {tv_sec=1567498656, tv_nsec=914934669}) = 0 <0.000041> ...... [pid 5071] 16:17:36.918234 getpid() = 1 <0.000023> [pid 5071] 16:17:36.918309 open("/proc/1/stat", O_RDONLY) = 10 <0.000043> [pid 5071] 16:17:36.918416 read(10, "1 (redis-server) R 0 1 1 34816 1"..., 4096) = 321 <0.000121> [pid 5071] 16:17:36.918596 close(10) = 0 <0.000030> [pid 5071] 16:17:36.918762 clock_gettime(CLOCK_REALTIME, {tv_sec=1567498656, tv_nsec=918814779}) = 0 <0.000043> ...... [pid 5071] 16:17:36.919417 read(3, 0x7fffd80116e7, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000033> [pid 5071] 16:17:36.919519 clock_gettime(CLOCK_REALTIME, {tv_sec=1567498656, tv_nsec=919563533}) = 0 <0.000040> [pid 5071] 16:17:36.919612 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 100, NULL, 8) = 1 <0.000300> [pid 5071] 16:17:36.919982 read(8, "*4\r\n$4\r\nSCAN\r\n$4\r\n3330\r\n$5\r\nMATC"..., 16384) = 47 <0.000101> ...... [pid 5071] 16:17:36.921525 read(3, 0x7fffd80116e7, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000024> [pid 5071] 16:17:36.921987 write(8, "*2\r\n$4\r\n2178\r\n*11\r\n$41\r\nuuid:42e"..., 547) = 547 <0.000099> [pid 5071] 16:17:36.922161 clock_gettime(CLOCK_REALTIME, {tv_sec=1567498656, tv_nsec=922214066}) = 0 <0.000044> [pid 5071] 16:17:36.922271 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 97, NULL, 8) = 1 <0.000506> [pid 5071] 16:17:36.923453 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:42e524c2-"..., 16384) = 61 <0.000034>
观察一会儿,有没有发现什么有趣的现象呢?
事实上,从系统调用来看, epoll_pwait、read、write、fdatasync 这些系统调用都比较频繁。那么,刚才观察到的写磁盘,应该就是 write 或者 fdatasync 导致的了。接着再来运行 lsof 命令,找出这些系统调用的操作对象:
root@luoahong:~# lsof -p 5071 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME redis-ser 5071 systemd-network cwd DIR 8,2 4096 1183489 /data redis-ser 5071 systemd-network rtd DIR 0,51 4096 2500819 / redis-ser 5071 systemd-network txt REG 0,51 8191592 1840394 /usr/local/bin/redis-server redis-ser 5071 systemd-network mem REG 8,2 1840394 /usr/local/bin/redis-server (stat: No such file or directory) redis-ser 5071 systemd-network mem REG 8,2 1054947 /etc/localtime (path inode=4462182) redis-ser 5071 systemd-network mem REG 8,2 1313815 /lib/ld-musl-x86_64.so.1 (stat: No such file or directory) redis-ser 5071 systemd-network 0u CHR 136,0 0t0 3 /dev/pts/0 redis-ser 5071 systemd-network 1u CHR 136,0 0t0 3 /dev/pts/0 redis-ser 5071 systemd-network 2u CHR 136,0 0t0 3 /dev/pts/0 redis-ser 5071 systemd-network 3r FIFO 0,12 0t0 76970 pipe redis-ser 5071 systemd-network 4w FIFO 0,12 0t0 76970 pipe redis-ser 5071 systemd-network 5u a_inode 0,13 0 10710 [eventpoll] redis-ser 5071 systemd-network 6u sock 0,9 0t0 76972 protocol: TCP redis-ser 5071 systemd-network 7w REG 8,2 5456789 1183490 /data/appendonly.aof redis-ser 5071 systemd-network 8u sock 0,9 0t0 77708 protocol: TCP redis-ser 5071 systemd-network 9u sock 0,9 0t0 85803 protocol: TCP root@luoahong:~#
现在你会发现,描述符编号为 3 的是一个 pipe 管道,5 号是 eventpoll,7 号是一个普通文件,而 8 号是一个 TCP socket。
结合磁盘写的现象,我们知道,只有 7 号普通文件才会产生磁盘写,而它操作的文件路径是 /data/appendonly.aof,相应的系统调用包括 write 和 fdatasync。
3、 Redis 的持久化配置原理和注意事项
如果你对 Redis 的持久化配置比较熟,看到这个文件路径以及 fdatasync 的系统调用,你应该能想到,这对应着正是 Redis 持久化配置中的 appendonly 和 appendfsync 选项。
很可能是因为它们的配置不合理,导致磁盘写比较多。接下来就验证一下这个猜测,我们可以通过 Redis 的命令行工具,查询这两个选项的配置。
继续在终端一中,运行下面的命令,查询 appendonly 和 appendfsync 的配置:
docker exec -it redis redis-cli config get 'append*' 1) "appendfsync" 2) "always" 3) "appendonly" 4) "yes"
从这个结果你可以发现,appendfsync 配置的是 always,而 appendonly 配置的是yes。这两个选项的详细含义,你可以从 Redis Persistence 的文档中查到,这里我做一下简单介绍。
4、Redis 提供了两种数据持久化的方式,分别是快照和追加文件。
快照方式,会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中。为了避免阻塞主进程,Redis 还会 fork 出一个子进程,来负责快照的保存。这种方式的性能好,无论是备份还是恢复,都比追加文件好很多。
不过,它的缺点也很明显。在数据量大时,fork 子进程需要用到比较大的内存,保存数据也很耗时。所以,你需要设置一个比较长的时间间隔来应对,比如至少 5 分钟。这样,
如果发生故障,你丢失的就是几分钟的数据。
追加文件,则是用在文件末尾追加记录的方式,对 Redis 写入的数据,依次进行持久化,所以它的持久化也更安全。
此外,它还提供了一个用 appendfsync 选项设置 fsync 的策略,确保写入的数据都落到磁盘中,具体选项包括 always、everysec、no 等。
always 表示,每个操作都会执行一次 fsync,是最为安全的方式; everysec 表示,每秒钟调用一次 fsync ,这样可以保证即使是最坏情况下,也只丢失 1 秒的数据; 而 no 表示交给操作系统来处理
回忆一下我们刚刚看到的配置,appendfsync 配置的是 always,意味着每次写数据时,都会调用一次 fsync,从而造成比较大的磁盘 I/O 压力。
当然,你还可以用 strace ,观察这个系统调用的执行情况。比如通过 -e 选项指定fdatasync 后,你就会得到下面的结果:
root@luoahong:~# strace -f -p 5071 -T -tt -e fdatasync strace: Process 5071 attached with 4 threads [pid 5071] 16:24:26.489574 fdatasync(7) = 0 <0.004991> [pid 5071] 16:24:26.514328 fdatasync(7) = 0 <0.004021> [pid 5071] 16:24:26.602855 fdatasync(7) = 0 <0.004692> [pid 5071] 16:24:26.656592 fdatasync(7) = 0 <0.004023> [pid 5071] 16:24:26.691027 fdatasync(7) = 0 <0.007862> ...... [pid 5071] 16:24:27.534050 fdatasync(7) = 0 <0.006640> [pid 5071] 16:24:27.575976 fdatasync(7) = 0 <0.004995> [pid 5071] 16:24:27.630999 fdatasync(7) = 0 <0.004760>
从这里你可以看到,每隔 10ms 左右,就会有一次 fdatasync 调用,并且每次调用本身也要消耗 7~8ms。
不管哪种方式,都可以验证我们的猜想,配置确实不合理。这样,我们就找出了 Redis 正在进行写入的文件,也知道了产生大量 I/O 的原因。
不过,回到最初的疑问,为什么查询时会有磁盘写呢?按理来说不应该只有数据的读取吗?这就需要我们再来审查一下 strace -f -T -tt -p 5071 的结果。
read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) write(8, "$4\r\ngood\r\n", 10) read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) write(8, ":1\r\n", 4)
细心的你应该记得,根据 lsof 的分析,文件描述符编号为 7 的是一个普通文件/data/appendonly.aof,而编号为 8 的是 TCP socket。而观察上面的内容,8 号对应的
TCP 读写,是一个标准的“请求 - 响应”格式,即:
从 socket 读取 GET uuid:53522908-… 后,响应 good; 再从 socket 读取 SADD good 535… 后,响应 1。
对 Redis 来说,SADD 是一个写操作,所以 Redis 还会把它保存到用于持久化的appendonly.aof 文件中。
观察更多的 strace 结果,你会发现,每当 GET 返回 good 时,随后都会有一个 SADD 操作,这也就导致了,明明是查询接口,Redis 却有大量的磁盘写。
5、Redis 写磁盘的原因
到这里,我们就找出了 Redis 写磁盘的原因。不过,在下最终结论前,我们还是要确认一下,8 号 TCP socket 对应的 Redis 客户端,到底是不是我们的案例应用。
我们可以给 lsof 命令加上 -i 选项,找出 TCP socket 对应的 TCP 连接信息。不过,由于Redis 和 Python 应用都在容器中运行,我们需要进入容器的网络命名空间内部,才能看
到完整的 TCP 连接。
注意:下面的命令用到的 nsenter 工具,可以进入容器命名空间。如果你的 系统没有安装,请运行下面命令安装 nsenter: docker run --rm -v /usr/local/bin:/target jpetazzo/nsenter [root@luoahong ~]# docker run --rm -v /usr/local/bin:/target jpetazzo/nsenter Unable to find image 'jpetazzo/nsenter:latest' locally latest: Pulling from jpetazzo/nsenter ff4229790957: Pull complete c6e9de17d69e: Pull complete Digest: sha256:e1722e1503b24eb17daa5cb530766bac840c064c5b065861616eec825ef9953b Status: Downloaded newer image for jpetazzo/nsenter:latest Installing nsenter to /target Installing docker-enter to /target Installing importenv to /targe
还是在终端一中,运行下面的命令:
[root@luoahong ~]# PID=$(docker inspect --format {{.State.Pid}} app)
[root@luoahong ~]# nsenter --target $PID --net -- lsof -i
lsof: no pwd entry for UID 100
lsof: no pwd entry for UID 100
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
lsof: no pwd entry for UID 100
redis-ser 9844 100 6u IPv4 51240 0t0 TCP localhost:6379 (LISTEN)
lsof: no pwd entry for UID 100
redis-ser 9844 100 8u IPv4 52244 0t0 TCP localhost:6379->localhost:54074 (ESTABLISHED)
python 9953 root 3u IPv4 52217 0t0 TCP *:http (LISTEN)
python 9953 root 4u IPv4 194915 0t0 TCP luoahong:http->192.168.118.74:60266 (ESTABLISHED)
python 9953 root 5u IPv4 53526 0t0 TCP localhost:54074->localhost:6379 (ESTABLISHED)
这次我们可以看到:
1、redis-server 的 8 号文件描述符,对应 TCP 连接 localhost:6379->localhost:32996。其中, localhost:6379 是 redis-server 自己的监听端口,自然localhost:32996 就是 redis 的客户端。
2、再观察最后一行,localhost:32996 对应的,正是我们的 Python 应用程序(进程号为 9181)。
6、历经各种波折,我们总算找出了 Redis 响应延迟的潜在原因
历经各种波折,我们总算找出了 Redis 响应延迟的潜在原因。总结一下,我们找到两个问题。
第一个问题,Redis 配置的 appendfsync 是 always,这就导致 Redis 每次的写操作,都会触发 fdatasync 系统调用。今天的案例,没必要用这么高频的同步写,使用默认的 1s
时间间隔,就足够了。
第二个问题,Python 应用在查询接口中会调用 Redis 的 SADD 命令,这很可能是不合理使用缓存导致的。
五、解决方案
1、第一个问题
对于第一个配置问题,我们可以执行下面的命令,把 appendfsync 改成 everysec:
[root@luoahong ~]# docker exec -it redis redis-cli config set appendfsync everysec OK
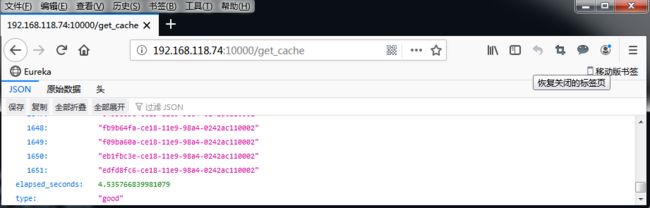
改完后,切换到终端二中查看,你会发现,现在的请求时间,已经缩短到了 4.5s:
2、第二个问题
而第二个问题,就要查看应用的源码了。点击 Github ,你就可以查看案例应用的源代码:
def get_cache(type_name):
'''handler for /get_cache'''
for key in redis_client.scan_iter("uuid:*"):
value = redis_client.get(key)
if value == type_name:
redis_client.sadd(type_name, key[5:])
data = list(redis_client.smembers(type_name))
redis_client.delete(type_name)
return jsonify({"type": type_name, 'count': len(data), 'data': data})
果然,Python 应用把 Redis 当成临时空间,用来存储查询过程中找到的数据。不过我们知道,这些数据放内存中就可以了,完全没必要再通过网络调用存储到 Redis 中。
基于这个思路,我把修改后的代码也推送到了相同的源码文件中,你可以通过http://192.168.118.74:10000/get_cache_data 这个接口来访问它。
我们切换到终端二,按 Ctrl+C 停止之前的 curl 命令;然后执行下面的 curl 命令,调用http://192.168.118.74:10000/get_cache_data 新接口:
while true; do curl http://192.168.118.74:10000/get_cache_data; done
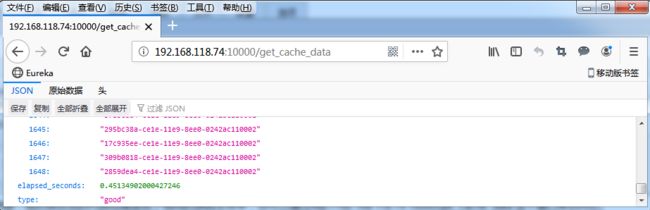
{...,"elapsed_seconds":0.38527560234069824,"type":"good"}
你可以发现,解决第二个问题后,新接口的性能又有了进一步的提升,从刚才的 4.5s ,再次缩短成了不到 0.45s。
当然,案例最后,不要忘记清理案例应用。你可以切换到终端一中,执行下面的命令进行清理:
docker rm -f app redis
小结
今天我带你一起分析了一个 Redis 缓存的案例。
我们先用 top、iostat ,分析了系统的 CPU 、内存和磁盘使用情况,不过却发现,系统资源并没有出现瓶颈。这个时候想要进一步分析的话,该从哪个方向着手呢?
通过今天的案例你会发现,为了进一步分析,就需要你对系统和应用程序的工作原理有一定的了解。定的了解。
比如,今天的案例中,虽然磁盘 I/O 并没有出现瓶颈,但从 Redis 的原理来说,查询缓存时不应该出现大量的磁盘 I/O 写操作。
顺着这个思路,我们继续借助 pidstat、strace、lsof、nsenter 等一系列的工具,找出了两个潜在问题,一个是 Redis 的不合理配置,另一个是 Python 应用对 Redis 的滥用。找
到瓶颈后,相应的优化工作自然就比较轻松了。