一、创建新项目,新建Flight_Info.py页面
1.写一个主程序方法:
1 #主程序 2 if __name__ == '__main__': 3 try: 4 py_info() #循环爬取方法 5 6 #爬取出错 7 except Exception as e: 8 print('爬取错误:'+e) 9 #pass
2.查看爬取页面HTML,定位要爬取信息位置
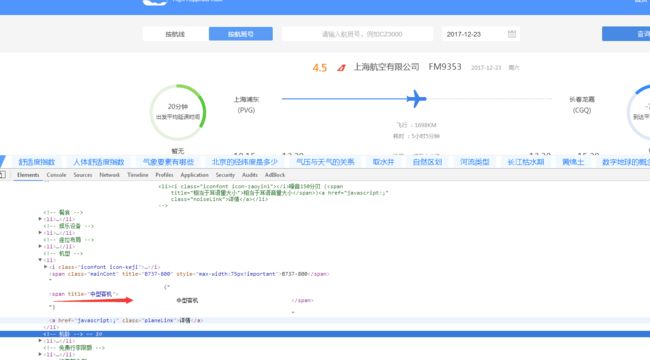
3.根据URL参数爬取航班信息:


1 ok_ip=[] #可用IP 2 all_ip=[] #IP列表 3 ok=[] #返回信息 4 # 根据航班参数返回航班信息 5 def get_content(fnum,dep,arr,date,type): 6 global ok_ip 7 global all_ip 8 global ok 9 # 首次使用本机IP直接获取 10 content = requests.get('http://happiness.variflight.com/info/detail?fnum='+fnum+'&dep='+dep+'&arr='+arr+'&date='+date+'&type='+type+'').text 11 soup = BeautifulSoup(content, 'html.parser') 12 13 #是否上限需代理IP 14 if(content.find("查无航班判断") < 0): 15 ipinfo = open('代理IP(2017-12-25).txt') 16 all_ip = ipinfo.read().splitlines() 17 18 if len(ok_ip)>0: #有可用IP 19 iptext=ok_ip[0] 20 # 查询上限,换IP 21 proxies = {'http': '//' + iptext, 'https': '//' + iptext} 22 try: 23 # proxies代理IP timeout超时设置 24 content = requests.get( 25 'http://happiness.variflight.com/info/detail?fnum=' + fnum + '&dep=' + dep + '&arr=' + arr + '&date=' + date + '&type=' + type + '', 26 proxies=proxies,timeout=30).text 27 soup = BeautifulSoup(content, 'html.parser') 28 # 可用IP是否上限 29 if (content.find("查无航班判断") < 0): 30 if(ok_ip[0]!=''): 31 ok_ip.remove(iptext) # 移除不可用IP 32 except: 33 pass 34 35 else: #无可用IP找IP列表 36 # 获取IP列表 37 for qwe in all_ip: 38 iptext = qwe 39 40 # 查询上限,换IP 41 proxies = {'http': '//' + iptext, 'https': '//' + iptext} 42 try: 43 content = requests.get( 44 'http://happiness.variflight.com/info/detail?fnum=' + fnum + '&dep=' + dep + '&arr=' + arr + '&date=' + date + '&type=' + type + '', 45 proxies=proxies,timeout=30).text 46 soup = BeautifulSoup(content, 'html.parser') 47 # 可用IP是否上限 48 if (content.find("查无航班判断") < 0): 49 50 if(ok_ip[0]!=''): 51 ok_ip.remove(iptext) # 移除不可用IP 52 continue 53 # 是可用IP即结束循环 54 else: 55 ok_ip.append(iptext) # 加入可用IP 56 print('目前可用IP:' + iptext) 57 break 58 except : 59 continue 60 61 #暂无航班信息 62 if (content.find("没有找到您输入的航班信息") > 0): 63 ok=[] 64 #查询成功 65 else: 66 try: 67 ok=get_info(fnum,soup,dep,arr) 68 except: 69 print('爬取'+fnum+'航班失败') 70 return ok 71 #返回航班信息 72 return ok
4.自动循环爬取
1 #循环爬取 2 def py_info(): 3 # 批量爬取航班信息 4 newhb='' 5 szm_cf='' 6 szm_md='' 7 hbb='' 8 # 根据航班txt循环爬取 9 hb_txt = open('航班列表.txt') 10 try: 11 all_text = hb_txt.read().splitlines() 12 #获取最新航班索引 13 newhb=ReadPGSQL() 14 if(newhb!=''): #获取数据库最新航班 15 hisindex = all_text.index(newhb) 16 # 查找位置 17 for hb in all_text: 18 # 找到当前位置开始爬取 19 if (all_text.index(hb) < hisindex): 20 continue 21 szm_list = hb.split("\t", 1)[0] 22 szm_cf = szm_list[0:3] # 出发地三字码 23 szm_md = szm_list[3:6] # 目的地三字码 24 hbb = hb.split("\t", 1)[1] # 航班号 25 hblx = '1' # 航班类型 26 hbrq = time.strftime("%Y-%m-%d") # 日期 27 save(hbb, szm_cf, szm_md, hbrq, hblx) # 保存航班信息 28 print(hbb + '航班爬取完成!') 29 print('爬取完成!') 30 else: 31 for hb in all_text: 32 szm_list = hb.split("\t", 1)[0] 33 szm_cf = szm_list[0:3] # 出发地三字码 34 szm_md = szm_list[3:6] # 目的地三字码 35 hbb = hb.split("\t", 1)[1] # 航班号 36 hblx = '1' # 航班类型 37 hbrq = time.strftime("%Y-%m-%d") # 日期 38 save(hbb, szm_cf, szm_md, hbrq, hblx) # 保存航班信息 39 print(hbb + '航班爬取完成!') 40 print('爬取完成!') 41 42 # 爬取出错中止写入列名 43 except: 44 print('保存航班出错') 45 Error(szm_cf,szm_md,hbb) #记录出错航班 46 #pass
5.处理HTML
1 #处理HTML航班信息 2 def get_info(fnum,soup,dep,arr): 3 try: 4 hbh = fnum 5 6 phdate=time.strftime("%Y-%m-%d") #抓取票号日期 7 8 szm_str=dep 9 10 szm_end=arr 11 12 str_time='' 13 # 查找div中class=“fl three-lef”的HTML 14 for li in soup.select('div[class="fl three-lef"]'): #起飞时间 15 str_time=li.get_text() #获取文本内容 16 17 end_time='' 18 for li in soup.select('div[class="fr three-rig"]'): #到达时间 19 end_time=li.get_text() 20 21 jt = '无经停' 22 for li in soup.select('div[class="fl three-mid"]'): # 经停 23 jt = li.get_text() 24 if(jt!='无经停'): 25 jt=jt[4:] 26 27 km='' 28 for li in soup.select('p[class="one"]'): #里程(km) 29 km=li.get_text() 30 km=km[4:] 31 32 km_time='' 33 for li in soup.select('p[class="two"]'): #耗时(分钟) 34 km_time=li.get_text() 35 km_time=km_time[4:] 36 37 jx=' ' 38 for li in soup.select('span[style="max-width:75px!important"]'): #机型 39 jx=li.get_text() 40 41 jxdx='' 42 if(soup.select('span[title="大型客机"]')): 43 jxdx='大型客机' 44 elif(soup.select('span[title="中型客机"]')): 45 jxdx = '中型客机' 46 elif(soup.select('span[title="小型客机"]')): 47 jxdx = '中型客机' 48 49 can='' 50 if (soup.select('span[class="totalCont"]')): 51 can='提供' 52 53 pf='' 54 for li in soup.select('span[class="score cur"]'): #舒适度评分 55 pf=li.get_text() 56 57 updatetime=time.strftime("%Y-%m-%d") #更新时间 58 59 try: 60 FLPGSQL(hbh, phdate, szm_str, szm_end, str_time, end_time, jt, km, km_time, jx, jxdx, can, pf, 61 updatetime) # 入库 62 except: 63 print('入库出错') 64 Error(szm_str,szm_end,hbh) #记录出错航班 65 #pass 66 67 finally: 68 return(hbh, phdate, szm_str, szm_end, str_time, end_time, jt, km, km_time, jx, jxdx, can, pf, updatetime)
全部代码:(单个爬取航班)
1 import urllib.request 2 import urllib.parse 3 import re 4 from bs4 import BeautifulSoup 5 import requests 6 from lxml import etree 7 import datetime 8 import time 9 import html 10 import csv 11 import exception 12 import int 13 import psycopg2 14 import socket 15 import sys 16 import os 17 18 19 #处理航班信息HTML 20 def get_info(fnum,soup,dep,arr): 21 try: 22 hbh = fnum 23 24 phdate=time.strftime("%Y-%m-%d") #抓取票号日期 25 26 szm_str=dep 27 28 szm_end=arr 29 30 str_time=' ' 31 for li in soup.select('div[class="fl three-lef"]'): #起飞时间 32 str_time=li.get_text() 33 34 end_time=' ' 35 for li in soup.select('div[class="fr three-rig"]'): #到达时间 36 end_time=li.get_text() 37 38 jt = ' ' 39 for li in soup.select('div[class="fl three-mid"]'): # 经停 40 jt = li.get_text() 41 if(jt!=' '): 42 jt=jt[4:] 43 44 km='' 45 for li in soup.select('p[class="one"]'): #里程(km) 46 km=li.get_text() 47 km=km[4:] 48 49 km_time=' ' 50 for li in soup.select('p[class="two"]'): #耗时(分钟) 51 km_time=li.get_text() 52 km_time=km_time[4:] 53 54 jx=' ' 55 for li in soup.select('span[style="max-width:75px!important"]'): #机型 56 jx=li.get_text() 57 58 jxdx=' ' 59 if(soup.select('span[title="大型客机"]')): 60 jxdx='大型客机' 61 elif(soup.select('span[title="中型客机"]')): 62 jxdx = '中型客机' 63 elif(soup.select('span[title="小型客机"]')): 64 jxdx = '中型客机' 65 66 can=' ' 67 if (soup.select('span[class="totalCont"]')): 68 can='提供' 69 70 pf=' ' 71 for li in soup.select('span[class="score cur"]'): #舒适度评分 72 pf=li.get_text() 73 74 updatetime=time.strftime("%Y-%m-%d") #更新时间 75 76 finally: 77 return(hbh, phdate, szm_str, szm_end, str_time, end_time, jt, km, km_time, jx, jxdx, can, pf, updatetime) 78 79 80 ok_ip=[] #可用IP 81 all_ip=[] #IP列表 82 ok=[] #返回信息 83 # 根据航班参数请求页面 84 def get_content(fnum,dep,arr,date,type): 85 # 首次使用本机IP 86 content = requests.get('http://happiness.variflight.com/info/detail?fnum='+fnum+'&dep='+dep+'&arr='+arr+'&date='+date+'&type='+type+'').text 87 soup = BeautifulSoup(content, 'html.parser') 88 89 #是否上限需代理IP 90 if(content.find("Notifica: timeout del gateway")>0 or content.find("The requested URL could not be retrieved")>0 or content.find("main notFound")>0 or content.find("此类查询已达当日上限")>0): 91 ipinfo = open('代理IP(2017-12-25).txt') 92 all_ip = ipinfo.read().splitlines() 93 94 if len(ok_ip)>0: #有可用IP 95 iptext=ok_ip[0] 96 # 查询上限,换IP 97 proxies = {'http': '//' + iptext, 'https': '//' + iptext} 98 try: 99 content = requests.get( 100 'http://happiness.variflight.com/info/detail?fnum=' + fnum + '&dep=' + dep + '&arr=' + arr + '&date=' + date + '&type=' + type + '', 101 proxies=proxies).text 102 #, timeout=120 103 #socket.setdefaulttimeout(150) # 超时后能自动往下继续跑 104 soup = BeautifulSoup(content, 'html.parser') 105 # 可用IP是否上限 106 if (content.find("Notifica: timeout del gateway") > 0 or content.find( 107 "The requested URL could not be retrieved") > 0 or content.find( 108 "main notFound") > 0 or content.find("此类查询已达当日上限") > 0): 109 ok_ip.remove(iptext) # 移除不可用IP 110 except: 111 pass 112 113 else: #无可用IP找IP列表 114 # 获取IP列表 115 for qwe in all_ip: 116 iptext = qwe 117 118 # 查询上限,换IP 119 proxies = {'http': '//' + iptext, 'https': '//' + iptext} 120 try: 121 content = requests.get( 122 'http://happiness.variflight.com/info/detail?fnum=' + fnum + '&dep=' + dep + '&arr=' + arr + '&date=' + date + '&type=' + type + '', 123 proxies=proxies).text 124 #,timeout=120 125 #socket.setdefaulttimeout(150) ##超时后能自动往下继续跑 126 soup = BeautifulSoup(content, 'html.parser') 127 128 # 可用IP是否上限 129 if (content.find("502 Bad Gateway")>0 or content.find("Notifica: timeout del gateway") > 0 or content.find( 130 "The requested URL could not be retrieved") > 0 or content.find( 131 "main notFound") > 0 or content.find("此类查询已达当日上限") > 0): 132 ok_ip.remove(iptext) # 移除不可用IP 133 continue 134 # 是可用IP即结束循环 135 else: 136 ok_ip.append(iptext) # 加入可用IP 137 print('目前可用IP:' + iptext) 138 break 139 except : 140 continue 141 142 #暂无航班信息 143 if (content.find("没有找到您输入的航班信息") > 0): 144 ok=[] 145 #查询成功 146 else: 147 try: 148 ok=get_info(fnum,soup,dep,arr) 149 except: 150 return ok 151 #返回航班信息 152 return ok 153 154 155 #写入CSV文件 156 def save(fnum,dep,arr,date,type): 157 #返回航班信息 158 try: 159 content=get_content(fnum,dep,arr,date,type) 160 # 写方式打开一个文本,把获取的航班信息存放进去 161 with open('Flight_Info.csv', 'a', ) as f: 162 writer = csv.writer(f) 163 writer.writerows([content]) 164 f.close() 165 except: 166 pass 167 168 169 hbb='' 170 szm_cf='' 171 szm_md='' 172 #循环爬取 173 def py_info(): 174 global hbb 175 global szm_cf 176 global szm_md 177 try: 178 print('请输入航班号:') 179 hbb = input() # 航班号 180 print('请输入出发地三字码:') 181 szm_cf = input() # 出发地三字码 182 print('请输入目的地三字码:') 183 szm_md = input() # 目的地三字码 184 hblx = '1' # 航班类型默认为1 185 hbrq = time.strftime("%Y-%m-%d") # 日期默认当天 186 save(hbb, szm_cf, szm_md, hbrq, hblx) # 保存写入CSV文件 187 print(hbb + '航班爬取完成!') 188 189 # 爬取出错跳过继续 190 except: 191 print(hbh+'航班爬取出错'+szm_cf+szm_md) #输出出错航班信息 192 pass 193 194 195 #主程序 196 if __name__ == '__main__': 197 py_info()