对于分类中集成学习算法,在不同的算法书中,叫法比较丰富。比如在周志华的西瓜书中,称为集成学习/多分类器系统/基于委员会的学习;在李航的《统计学习方法》中,称提升方法;在《数据挖掘导论》中,又称为组合方法/分类器组合。
无论怎么称呼,根据定义,这些名称表达的意思都是一样的,即:
- 通过聚集多个分类器的预测来提高分类准确率。
说明:这里的“分类器”如果由一个现有的学习算法(比如C4.5决策树算法)从训练数据中产生,那么所有的分类器类型相同,可统一称为“基学习器”;如果分类器由多种学习算法生成,则把这些学习其称为“组件学习器”或“个体学习器”
这篇学习笔记,主要是从下面几个问题入手,去理解一些常用的集成学习方法:
- 一、为什么组合方法比任意单分类器的效果好?【理论】
- 二、如何构建组合分类器技术?
针对第一个问题,借用《数据挖掘导论》例题5.7:
Consider an ensemble of twenty-five binary classifiers,each of which has an error rate of = 0.35. If the base classifiers are independent—i.e., their errors are uncorrelated—then the error rate of the ensembleclassifier is:
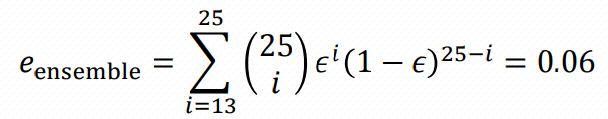
例题中,组合分类器(集成学习)的规则是对所有分类器的预测结果进行多数表决。所有分类器存在两种关系,其一,它们完全等同,这意味着它们是完全相关的,即任一分类器预测错误,其余的分类器也预测错误,组合分类器的误差等于0.35;第二种情况是所有分类器误差相互独立,组合分类器的误差是所有预测错误分类器个数大于12的误差累加,为上面的0.06。
此处,我有个问题是:如何理解分类器相互独立?