简单回顾下挖矿的流程。
首先先要对所有的交易做验证,剔除有问题的,然后通过一套自定义的标准来选择哪些交易希望打包进区块,比如说提供的交易费与交易占用的字节大小的比值超过某个门槛,这样的交易才被认为有利可图。当然,节点也可以特意选择要加入某条交易,或者故意忽略某些交易。如果是通过矿池挖矿的话,矿池的服务器会去筛选交易,然后分配给每个参与的矿机一个独立的任务。
一旦筛选好交易数据,层层约减,通过这些交易就可以计算出一棵Merkle树,可以确定一个唯一的摘要,这就是Merkl树的根。
然后我们再依次获取挖矿需要的其他信息,这些信息组成一个区块的头。
区块头的字节分配
- version 版本号,4个字节
- previous_block_hash 前一区块的摘要,32个字节
- merkle_root 默克尔树的根,32个字节
- time 区块生成时间,4个字节
- bits 难度目标,是一个数字,4个字节
- nonce 随机数,4个字节
区块头只有80个字节,挖矿只需要对区块头进行运算即可。交易数据都通过merkle树固定了下来,不需要再包含进来。

这些信息中大部分已经是固定下来的,或者是可计算的。
- 版本号是跟随比特币客户端而定的,一段时间内不会改变。即使要改变,也会有比特币的核心开发人员来协调升级策略,这个可以理解为一个静态常数。
- 前一区块的摘要,可以通过数学方法快速计算,因为前一区块早已打包好了。
- 默克尔树的根,刚才已经得到了结果。
- 时间,可以取打包时的时间,也不需要很精确,前后几秒,几十秒也都可以。
- 难度目标,是参考上两周产生的区块的平均生成时间而定的,两周内如果平均10分钟产生一个区块的话,两周会产生2016个区块,软件会计算最新的2016个区块生成的时间,然后做对比,随之调整难度,使得接下来产生的区块的预期时间保持在10分钟左右。因为最近的2016个区块已经确定,所以这个数字也是确定的。
- 最后一个随机数,就是挖矿的目标了。这个数字可以变化,而且要从0试到最大值。直到最后出现的hash结果,其数字必须低于难度目标值。不过以现在的计算机算力,这个数字用不了一秒就把全部的变化可能计算完了,所以还需要改变区块内部的创币交易中的附带消息,这样就让merkle root也发生了变化,从而有更多的可能去找到符合要求的nonce。
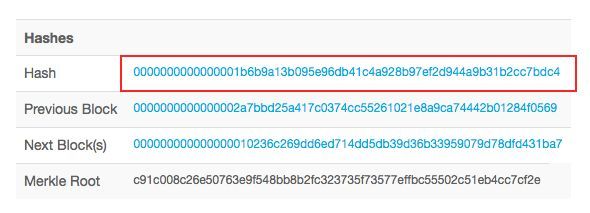
我们以区块277316为例,其信息来自网站http://blockchain.info
Bitcoin Block #277316blockchain.info
选择这个区块的原因是在《Mastering Bitcoin》一书中,中文社区译本和英文原版在介绍这部分内容时有出入,而且作者Antonopoulos并没有提到一个关键点,就是字节顺序的问题,相信很多人可能会踩这个坑。这里还原的细节可以帮助读者与书籍做相互参考。


请大家注意下面的每个步骤,注意每一个变化,这是比特币最核心的算法。
第一步,准备数据,转换时间
2 (版本号的十进制)
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569 (前一区块hash值的16进制)
c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e (merkle root的16进制)
2013-12-27 23:11:54 (utc时间)
419668748 (难度目标的十进制)
924591752 (随机数的十进制)
转换时间,记住,一定要转为utc的时间戳,此处遇到过坑,小心。
>>> import datetime
>>> from datetime import timezone
>>> datetime.datetime.strptime('2013-12-27 23:11:54', '%Y-%m-%d %H:%M:%S').replace(tzinfo=timezone.utc).timestamp()
1388185914.0
第二步,全部转换为16进制
00000002
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569
c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e
52be093a
1903a30c
371c2688
第三步,从big-endian转化为little-endian
这一步的发现异常艰辛,耗费了大量的查询,大坑,大坑,谨记。发明人中本聪可能为了让机器计算更快,而变为了更接近机器的编码方式little-endian.
02000000
69054f28012b4474caa9e821102655cc74037c415ad2bba70200000000000000
2ecfc74ceb512c5055bcff7e57735f7323c32f8bbb48f5e96307e5268c001cc9
3a09be52
0ca30319
88261c37
第四步,拼接字符串,开始验证
import binascii
from hashlib import sha256 as s
k = '0200000069054f28012b4474caa9e821102655cc74037c415ad2bba702000000000000002ecfc74ceb512c5055bcff7e57735f7323c32f8bbb48f5e96307e5268c001cc93a09be520ca3031988261c37'
hk = binascii.unhexlify(k)
res = binascii.hexlify(s(s(hk).digest()).digest()[::-1])
最终得到的结果就是
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
16进制下前面15个0,然后是1; 而难度目标对应的数字是
0000000000000003a30c00000000000000000000000000000000000000000000
16进制下前面15个0,然后是3. 计算结果小于难度目标,符合要求。这个结果与网站上公布的数字一致。
在挖矿时,nonce随机数是未知的,要从0试到2^32,但是这个数字其实不大,只有4294967296,以现在的矿机动辄14T每秒的算力,全部算完到上限也不需要一秒。刚才提到在这种情况下,需要使用创币交易中的附带信息,额外的字符串成为extra nonce。
另外,创世区块也可以通过上面的方法来验证,有好奇的朋友可以尝试下。
提示:
- 对于创始区块,版本号是1;
- 前一区块的hash摘要,猜想会是什么呢?
- 难度目标是1,这是定义为一个sha256结果的前32位是0,也就是对应的16进制字符串要有8个0,那么难度bits此时是0x1d00ffff。
- 然后再用上面的问题的解法去求解随机数就可以了。