概况
让各位读者们久等了。心想尼玛写一篇入门就消失了吗?也太水了吧! 其实不然,只是博主上周出去旅游了刚回来,所以没有及时更新。还望各位见谅。
那么开始今天的内容 - 简单的识别入门 (一些简单相关的机器学习知识也会在最近这几篇文章里融合)
没读过上一章的读者可以点此链接
机器视觉入门学习日志(一)-什么是CV?
http://www.jianshu.com/p/16746498f480
学习日记二:Introduction to Recognition 上
首先,什么是recognition?
Recognition,顾名思义,就是识别的意思。什么是识别?这是一个CV最基本的问题,可以简述为底层的分类问题。在我们的生活中,作为人类每时每刻都在进行分类的工作,比如这是鼠标还是键盘?这是苹果还是番茄?这是男人还是女人?这是单身还是人妻?X#$@*!&*!^$&!^@&!...
我们所有的思维,想法和一系列后续的动作都是基于分类这一个最基本的事件。因为对于不同的类别的事物,有不同的处理方式,也代表着不同的目的与动机,而只有当有了分类,才会产生目的与动机,才会有了接下来的事情。就好像你打开探探,你要先瞄准是男人还是女人,再XXXXX,而不是说随便抓个人就约吗?对吧
计算机也一样,所以分类问题为CV中或者说ML中非常基础和必须的一个环节。就好比给你一张图片,这是摩托还是马?是碗还是盘子?是麻雀还是老鹰?有了分类,我们才可以用不同的算法和方法去对识别与分过类的物体进行下一步的任务。在后面会具体讲到识别和分类的更加细化的方法如edge detect, circle detect, texture, blabla, 今天讲的是general 的识别与分类。
奇思妙想:思考邮箱是如何区分辣鸡邮件和有用的邮件的?
前提
在这里,识别和分类问题会用到一些机器学习的知识,所以在此预先讲一下机器学习的一个大前提。
机器学习或者稍后用到的神经网络,听到这俩东西,不要怕,不要怕...其实总体来讲并不是什么高深莫测的东西
在那个懵懂的年代,都学过方程式吧?码农们知道什么是function吧?那好,其实机器学习,神经网络等的框架与大前提就是一个方程
你给一个参数,然后返回给你一个结果或者多个结果。举个例子,在CV领域就是往这个网络里面塞一张图片,然后返回一个机器预测的结果,是张三还是李四。就这么简单
那么有的读者就很高兴了,哇我学会机器学习了,我学会神经网络了,那么你就是too young too naive.....
在这里提一嘴总览机器学习的一个简单过程。一般来讲,分为两个阶段:Training 和 Testing。在Training阶段,你需要准备大量的数据和他们的label。可以这样去理解,你搞一箩筐水果,里面有苹果西瓜香蕉等,每一种水果还有很多个不同的形状,然后你往每个水果上面贴一个标签标明是什么水果(label),接下来你把他们扔进一个机器里面,这个机器你要预先做一些调试,能够提取和识别每个水果的形状,颜色等特征(features)而且能够读出这个label知道什么特征对应什么水果,然后最后这个机器经过一段时间的运作,就拉出了一个盒子,这个盒子就是一个模型(model),可以进行水果的识别和预测。
在Testing阶段,你又准备了这样一筐子水果,但是这次你在他们上面没有贴上label,就只是一堆水果,光溜溜的水果,然后你把他们挨着扔进这个前面拉出来的model,这个时候奇妙的事情发生了,你扔进去一个东西,这个model就会告诉你这是什么东西。
这就是机器学习的一个整体流程,上面描述的这种方法叫做supervised learning,也就是需要人辅助Train,给Label。后面会有几篇日记专门讲神经网络,到时候会对这个进行更进一步的讲解,现在只需要知道大概是个什么鬼就行了。
The Simplest Classifier
这是一个最简单的归类的方法,此处不需要机器学习。此处不需要机器学习,此处不需要机器学习,重要的事情说三遍
这个方法简单到一个什么地步呢,一句话概括:找最短距离。
哈哈哈哈什么鬼?(看来一句话还是讲不完的....)
这个方法,其实就是你把一堆东西仍在一个地上(不是乱扔,而是有规矩的扔,比如A扔在左边,B扔在右边,等)。扔完以后,你有一个需要预测或者识别的东西,然后你把他根据他的规格来扔一个属于它地方,扔完以后,拿块尺子来量它和地上其他东西之间的距离,最短的那一个是啥东西,它就是啥东西,好理解吧?
从CV的应用来讲,就是说一把一堆图片的特征提取出来(怎么提取,后面会讲),然后根据他们的值把他们分布在一个XY区域里,这个时候你把一个新的图片的特征提取出来放进去,来算它与其他点之间的距离,取最近的那一个。
这个方法虽然简单粗暴,但是有一个非常致命的缺陷,你猜
那就是RUNTIME! 非常糟糕! 因为他需要算每个之间的距离,而那些其他一看就尼玛相隔十万八千里的,我为毛还要算它?脑残吗?这个时候。我们来优化一下,就产生了下面这个方法。
K-Nearest Neighbors classification
顾名思义,K个最近的邻居。我们在这个我们想预测的点的身边,以它为中心,画一个圈圈诅咒它,这样我们就只用算它和圈圈以内的点的距离。。什么?不想算距离?好办!既然画了圈圈,我们也知道这个圈圈里的点是啥,那我们来投票吧!
这个时候,假设圈圈里有黑红两种颜色的点点,那么哪种颜色的点点最多,我们就把想要预测这个点涂成这个颜色,也就是预测它为这个类。很简单吧?
Linear classifier
这是线性分类。假设我们有两个类别,一个在左边,一个在右边,这个时候我们有一个新的点,怎样知道它属于左边还是右边呢?当然是画一条界限!然后观察这个点在这条线的那边不就行了! Wait。。。怎么画线来着?
我们需要找到一个function,来代表这条线,比如
f(x) = sgn(w1x1 + w2x2 + … + wDxD) = sgn(w x) (此处1,2,D为下标)
w是vector,代表weight 假设w=[a c],x=[x y] 然后这条线我们可以用
ax + cy + b = 0 (b是一个bias,暂时不用管这个值,就把它想成一个数就行,后面会讲它的用途)
来表示,简化为
wx+b = 0
这个时候如果有一个点p = (x0,y0),我们就可以求到这个点与这条线之间的距离
D= |ax0+cy0+b|/sqrt(a^2+c^2) (为什么是sqrt(...)?因为这个地方weight的x值是a,y值是c,那么求斜边,不用多讲了吧?)
这个distance 方程最后可以简写为
D = (w T x + b)/||w|| (w T x = w transpose x . 看不懂的看Linear algebra的基础去..)
现在有了线,有了点,我们就能知道这个点在线的那边,简单量化的话就可以想做是>0和<0的问题,正数为右,负数为左,这就达成了分类。
那么在正数和负数这两类之间,能够找到许多的线 (如图)
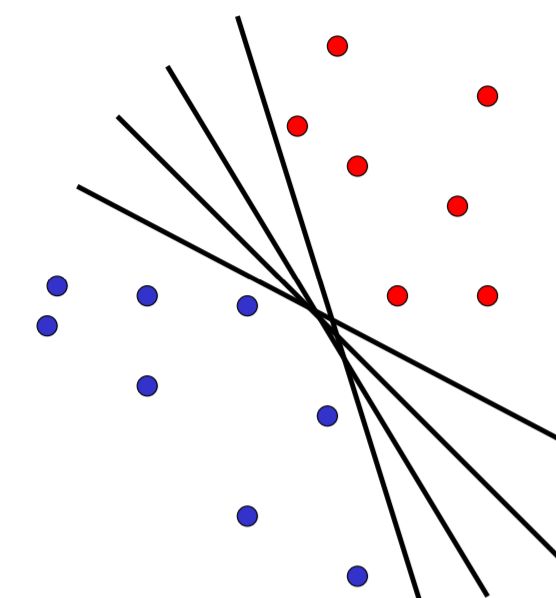
这个时候应该选哪条呢?
这个时候一般我们想要maximize这条线与两类之间的距离,那么会选一条线刚好等于0 (wx+b=0),然后让右边正数部分的最左边的点落在平行线wx+b=1上,左边负数部分的最右边的点落在平行线wx+b=-1上,让他们之间的距离刚好等于2,我们称这些两边最边缘的点,刚好落在=+-1的线上的点为support vector。
这样一来,正数部分的sv到中线的距离就刚好是1,负数部分同样,正负数之间的距离就会是2,也就是此处我们想要达到的一个效果,将正负两类之间的margin最大化。有人可能会问,为什么不是3,不是4?此处一言难尽,有兴趣的读者可以去阅读此篇文章(英文...)
http://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf 阅读1.1-1.2部分
总之,这里有一个重要的概念需要记住,
在optimize这个问题的时候我们需要对于yi(wx+b)>=1 将 1/2wTw最小化,也就是说要将margin最大化。具体的原因和解释比较长,就需要读者们去阅读上面的文章了。
上面我们提到,这个东西叫做support vector, 所以此类方法或者这个东西我们叫做SVM (support vector machine)
今天讲到的叫做linear SVM, 也就是我们上面看到的,这条线是linear 的。那么NON-Linear 非线性的情况怎么办呢?要是点都交杂在一起,找不到这条线怎么办呢?这不是只能分两个类吗?尼玛现实中有很多类要一起分的好吧,那又怎么办? 那分完类了,又干啥?
下一章节我将讲到 non-linear的分类方法,kernal trick 还有多类的SVM分类方法,以及开始进入神经网络日记部分。
点个赞,请听下回分晓。
------------------------------------------------------
本次日记结束。886
此篇文章是第一篇技术性的文章,可能博主有些地方会讲的不太清楚,
对文章的讲述方式有建议,或者有什么问题,有什么想进一步了解的知识,请在下面留言吧~
谢谢阅读