今天看了Python语言写的使用SVM中的SMO进行优化,使用RBF函数进行手写体识别,下面简单整理一下整个过程及思路,然后详细介绍各个部分。
整个过程:
(1)获取训练数据集trainingMat和labelMat;
(2)利用SMO进行优化获得优化参数alphas和b,这一步即是进行训练获得最优参数;
(3)使用alphas和b带入RBF高斯核函数计算训练集输出并计算训练错误率;
(4)获取测试数据集testMat和labelMat1;
(5)使用(2)的参数alphas和b带入RBF高斯核函数计算输出,从而计算分类错误率;
Python代码:
def testDigits(kTup=('rbf',10)):
dataArr,labelArr=loadImages('D://softwareTool/Python/python_exerciseCode/Chap6_SVM//trainingDigits');
b,alphas=smoP(dataArr,labelArr,200,0.0001,1000,kTup);
dataMat=mat(dataArr);
labelMat=mat(labelArr).transpose();
# 取得支持向量的索引
svInd=nonzero(alphas.A>0)[0];
sVs=dataMat[svInd];
labelSV=labelMat[svInd];
print("there are ",shape(sVs)[0],' Support Vectors');
m,n=shape(dataMat);
errorCount=0.0;
for i in range(m):
kernelEvl=kernelTrans(sVs,dataMat[i,:],kTup);
# 计算输出公式
predict=kernelEvl.T*multiply(labelSV,alphas[svInd])+b;
if sign(predict)!=sign(labelMat[i]):
errorCount+=1.0;
print("the training error rate is:",errorCount/(len));
dataArr,labelArr=loadImages('D://softwareTool/Python/python_exerciseCode/Chap6_SVM//testDigits');
dataMat=mat(dataArr);
labelMat=mat(labelArr).transpose();
m,n=shape(dataMat);
errorCount=0.0;
for i in range(m):
kernelEval=kernelTrans(sVs,dataMat[i,:],kTup);
predict=kernelEval*multiply(labelSV,alphas[svInd])+b;
if sign(predict)!=sign(labelMat[i]):
errorCount+=1.0;
print("the test error rate is: ",errorCount/float(ms));
上面是整个主框架和主程序。
下面分模块介绍各个部分:
(1)获取训练数据集和训练标签:
如给的训练数据存放在文件trainingDigits中,其里面有多个.txt子文件,每个.txt文件存放的是一幅32*32的的图像,每一幅图像表示0-9的一个数字;

如这幅图显示的为数字3,最后将每幅图像转化为一个32*32=1024的列向量,如果训练样本数为m,则dataMat为m*1024的矩阵,labelMat为1*m的列向量。
下面先说说在Python中怎样将一幅图像(例32*32)转化为一个列向量(1*1024):函数输入为这幅图像的文件名‘3_177.txt’
伪代码: 初始化列向量returnVec为zeors((1,1024));
遍历每行:
读取每行(1*32的列向量)内容;
遍历每列:
将每列内容强转化为int型依次添加到returnVec中;
返回returnVec;
Python代码:
# 将一幅图像转化为一个向量 def img2vector(filename): # 将一幅32*32的图像转化为一个1*1024的图像 returnVect=zeros((1,1024)); fr=open(filename);
# 遍历每行 for i in range(32): # 读取文件每行内容 lineStr=fr.readline(); for j in range(32): returnVect[0,i*32+j]=int(lineStr[j]); return returnVect;
注意:fr.readline()和fr.readlines()区别;
下面写一下调用上面的函数img2vector(filename)怎样读取所有文件内容得到训练数据矩阵trainingMat(m*1024)和类标签l向量hwLabels(m*1):
伪代码: 取得所有子文件名(如'0_0.txt','0_1.txt',...),将其存放在一个列表里;
计算子文件个数(m),即统计样本个数;
初始化trainingMat和hwLabels;
遍历每个子文件:
取得该文件名(如'3_177.txt');
使用split('.')将文件名字符串切分为2部分,取前面部分(如'3_177');
使用split('_')将字符串切分为2部分,取前面部分('3'),同时强制转化为int类型;
由前面得到的整数获得对应类标签添加到hwLabels里(由于本例使用2分类,将数字0-8分为1类,数字9分为-1类,所以数字3的类标签为1);
调用函数img2vector(filename)将该文件的一幅图像(32*32)转化为一个列向量(1*1024),存放到trainingMat里;
返回trainingMat,hwLabels;
Python代码:
def loadImages(dirName):
from os import listdir; hwLabels=[]; # 将所有子文件名存放在一个列表中 trainingFileList=listdir(dirName); # 统计子文件个数 m=len(trainingFileList); # 初始化训练数据矩阵 trainingMat=zeros((m,1024)); # 遍历每个子文件 for i in range(m): # 获得子文件名如'0_2.txt' fileNameStr=trainingFileList[i]; # 用'.'将上面获得的字符串切分为2部分,取前面部分'0_2' fileStr=fileNameStr.split('.')[0]; # 用'_'将上面获得的字符串切分为2部分,取前面部分'0'且强转为int型得到类标签 classNumStr=int(fileStr.split('_')[0]); if classNumStr==9: hwLabels.append(-1); else: hwLabels.append(1); # 将每幅图像转化为一个1*1024的列向量存放在trainingMat中 trainingMat[i,:]=img2vector(dirName+'/'+fileNameStr);
return trainingMat,hwLabels;
(2)使用SMO(序列最小最优化)算法进行参数优化训练取得最优参数b和alphas
支持向量机的学习问题可以形式化为求解凸二次规划问题,这样的凸二次规划问题具有全局最优解,并且有许多最优化算法可以用于这一问题的求解.但当训练样本容量很大时,这些算法往往变得非常低效,以至无法使用.而SMO是一种快速实现算法.
SMO算法要解决如下凸二次规划的对偶问题:
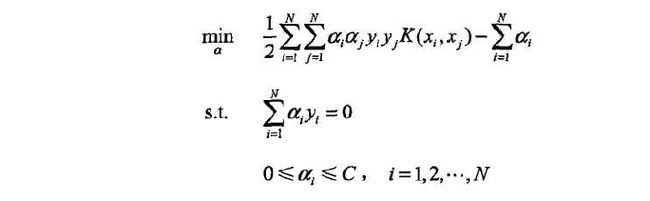
在这个问题中,变量是拉格朗日乘子,一个变量alphai对应于一个样本点(xi,yi);变量的总数等于训练样本数m.
SMO算法是一种启发式算法,其基本思路是:如果所有变量的解都满足此最优化问题的KKT条件,那么这个最优化问题的解就得到了.因为KKT条件是该最优化问题的充分必要条件.否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题.这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解,因为这使得原始二次规划问题的目标函数值变得更小,重要的是,这时子问题可以通过解析方法求解,这样就可以大大提高整个算法的计算速度.子问题有两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定.如此,SMO算法将原问题不断分解为子问题并对子问题求解,进而达到求解原问题的目的.
注意,子问题的两个变量中只有一个是自由变量.假设alpha1,alpha2为两个变量,alpha3,alpha4,...,alphaN固定,那么由等式约束可知:
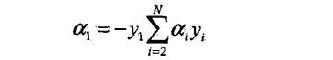
如果alpha2确定,那么alpha1也随之确定.所以子问题中同时更新两个变量.
整个SMO算法包括两个部分:求解两个变量二次规划的解析方法和选择变量的启发式方法.
简化版的SMO算法处理小规模数据集:Platt SMO算法的完整实现需要大量代码.Platt SMO算法中的外循环确定要优化的最佳alpha对.而简化版会跳过这一部分,首先在数据集上遍历每一个alpha,然后在剩下的alpha集合中随机选择另一个alpha,从而构成alpha对.就是要同时改变两个alpha.为此,将构建两个辅助函数.一个辅助函数用于在某个区间范围内随机选择一个整数;一个辅助函数用于在数值太大时进行调整.下面是两个辅助函数的Python代码:
# 随机选择一个j,函数输入i,m;i为alpha的下标,m为alpha的个数 def selectJrand(i,m): j=i; while(j==i): j=int(random.uniform(0,m)); return j; # 用于调整大于H或者小于L的alpha,使其介于[L,H]内
# 输入参数aj,H,L def clipAlpha(aj,H,L): if aj>H: aj=H; if aj<L: aj=L; return aj;
简化版的SMO伪代码大致如下:
伪代码: 创建一个alpha向量并将其初始化为0向量,初始化b为0;
当迭代次数小于最大迭代次数时(外循环):
遍历每个样本,即对数据集中的每个数据向量(内循环):
计算alpha1的函数值和误差;
误差和alpha1满足优化条件(如果该数据向量可以被优化):
随机选择另外一个数据向量alpha2;
计算alpha2的函数值和误差;
计算L和H;
计算eta;
更新alpha1和alpha2;
更新b1,b2;
计算b;
同时优化这两个向量;
如果两个向量都不能被优化,退出内循环;
如果所有向量都没被优化,增加迭代数目,继续下一次循环.
Python源代码:
def smoSimple(dataMatIn,classLabels,C,toler,maxIter): # 输入5个参数. dataMatrix=mat(dataMatIn); # m*n labelMat=mat(classLabels).transpose(); m,n=shape(dataMatrix); b=0; alphas=mat(zeros((m,1)));# 创建一个alpha向量并将其初始化为0向量 iterNum=0; while(iterNum<maxIter): alphasPairsChanged=0; for i in range(m): # 计算猜测的类别,P143式(7.104)g(x)=sigma(ai*yi*K(x,xi))+b fXi=float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T))+b; # 计算误差 Ei=fXi-float(labelMat[i]); # 如果该随机变量可以被优化(满足约束条件),随机选择另外一个数据向量;随机选择j # 如果误差很大,对alpha值进行优化 # 在if语句中,不过是正间隔还是负间隔都会被测试,同时检查alpha值不能为0或C,等于这两个值时,表示在边界上 if ((Ei*labelMat[i]<-toler) and (alphas[i]<C))\ or ((Ei*labelMat[i]>toler) and (alphas[i]>0)): j=selectJrand(i,m); fXj=float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T))+b; Ej=fXj-float(labelMat[j]); # 计算alphaIold,alphaJold;alphaIold,alphaJold为初始可行解 alphaIold=alphas[i].copy(); alphaJold=alphas[j].copy(); # 计算L和H,用于将alphas[j]调整到0-C之间 if(labelMat[i]!=labelMat[j]): L=max(0,alphaJold-alphaIold); H=min(C,C+alphaJold-alphaIold); else: L=max(0,alphaJold+alphaIold-C); H=min(C,alphaJold+alphaIold); if L==H: print('L==H'); continue; # 结束本次循环 # eta是alpha[j]的最优修改量eta=K11+K22-2*K12 eta=2*dataMatrix[i,:]*dataMatrix[j,:].T-\ dataMatrix[i,:]*dataMatrix[i,:].T-\ dataMatrix[j,:]*dataMatrix[j,:].T; if eta>=0: print("eta>=0"); continue; # 结束本次循环 # 同时改变alphas[i]和alphas[j],一个增大,一个减小 # 最优化问题沿着约束方向未经剪辑时的解 alphas[j]-=labelMat[j]*(Ei-Ej)/eta; # 调整大于H或者小于L的alpha alphas[j]=clipAlpha(alphas[j],H,L); # 检查alphas[j]是否有轻微改变;如果是的话,退出for循环 if(abs(alphas[j]-alphaJold)<0.0001): print("j not moving enough"); continue; # 由alpha2new求得alpha1new alphas[i]+=labelMat[i]*labelMat[j]*(alphaJold-alphas[j]); # 每次完成两个变量的优化后,都要重新计算阈值b b1=-Ei-labelMat[i]*dataMatrix[i,:]*dataMatrix[i,:].T*\ (alphas[i]-alphaIold)-labelMat[j]*dataMatrix[i,:]*\ dataMatrix[j,:].T*(alphas[j]-alphaJold)+b; b2=-Ej-labelMat[i]*dataMatrix[i,:]*dataMatrix[j,:].T*\ (alphas[i]-alphaIold)-labelMat[j]*dataMatrix[j,:]*\ dataMatrix[j,:].T*(alphas[j]-alphaJold)+b; if alphas[i]>0 and alphas[i]<C: b=b1; elif alphas[j]>0 and alphas[j]<C: b=b2; else: b=(b1+b2)/2; alphasPairsChanged+=1; print("iter: ",iterNum," i: ",i," pairs changed: ",alphasPairsChanged); # 如果所有向量(遍历完所有样本后)都没被优化,增加迭代数目,继续下一次循环 if(alphasPairsChanged==0): iterNum+=1; else: iterNum=0; print("iteration number: ",iterNum); return b,alphas;
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替:一种方式是在所有数据集上进行单边扫描,另一种方式是在非边界alpha中实现单边扫描.而所谓非边界alpha指的是那些不等于边界0或C的alpha值.
本文:http://www.cnblogs.com/yuzhuwei/p/4141713.html