Kylin
is an open source Distributed Analytics Engine from eBay Inc。that provides SQL interface and multi-dimensional analysis (OLAP) on Hadoop supporting extremely large datasets
亮点
1.Compression and Encoding Support
2.Incremental Refresh of Cubes
3.Approximate Query Capability for distinct Count (HyperLogLog)
4.Leverage HBase Coprocessor for query latency
5.Job Management and Monitoring
6.Easy Web interface to manage, build, monitor and query cubes
7.Security capability to set ACL at Cube/Project Level
8.Support LDAP Integration
HyperLogLog:
从事统计数据。统计一组不同元素且数量很大的数据集时,是一个挑战。
Hyper LogLog计数器就是估算Nmax为基数的数据集仅需使用loglog(Nmax)+O(1) bits就可以。
如线性计数器的Hyper LogLog计数器允许设计人员指定所需的精度值,在Hyper LogLog的情况下,这是通过定义所需的相对标准差和预期要计数的最大基数。
大部分计数器通过一个输入数据流M,并应用一个哈希函数设置h(M)来工作。这将产生一个S = h(M) of {0,1}^∞字符串的可观测结果。通过分割哈希输入流成m个子字符串,并对每个子输入流保持m的值可观测 ,这就是相当一个新Hyper LogLog(一个子m就是一个新的Hyper LogLog)。
利用额外的观测值的平均值,产生一个计数器,其精度随着m的增长而提高,这只需要对输入集合中的每个元素执行几步操作就可以完成。
其结果是,这个计数器可以仅使用1.5 kb的空间计算精度为2%的十亿个不同的数据元素。与执行 HashSet所需的120 兆字节进行比较,这种算法的效率很明显。
ACL
访问控制列表(Access Control List,ACL) 是路由器和交换机接口的指令列表,用来控制端口进出的数据包。ACL适用于所有的被路由协议,如IP、IPX、AppleTalk等。
– Hive
– Stinger without Tez
• SQL processed by a MPP Engine
– Impala
– Drill
– Presto
– Spark + Shark
• SQL process by a existing SQL Engine + HDFS
– EMC Greenplum (postgres)
– Taobao Garude (mysql)
• OLAP on Hadoop in other Companies
– Adobe: HBase Cube
– LinkedIn: Avatara
– Salesforce.com: Phoenix
why do we Build Kylin
• Why existing SQL-on-Hadoop solutions fall short?
The existing SQL-on-Hadoop needs to scan partial or whole data set to answer a user query. Moreover, table join may trigger the huge data transfer across host. Due to large scan range and network traffic latency, many queries are very slow (minute+latency).
• What is MOLAP/ROLAP?
– MOLAP (Multi-dimensional OLAP) is to pre-compute data along different dimensions of interest and store resultant values in the cube. MOLAP is much faster but is inflexible. Kylin is more like MOLAP.
– ROLAP (Relational-OLAP) is to use star or snow-flake schema to do runtime aggregation. ROLAP is flexible but much slower. All existing SQL-on-Hadoop is kind of ROLAP.
• How does Kylin support ROLAP/MOLAP?
Kylin builds data cube (MOLAP) from hive table (ROLAP) according to the metadata definition.
– If the query can be fulfilled by data cube, Kylin will route the query to data cube that is MOLAP.
– If the query can’t be fulfilled by data cube, Kylin will route the query to hive table that is ROLAP.
– Basically, you can think Kylin as HOLAP(Hybrid OLAP) on top of MOLAP and ROLAP.
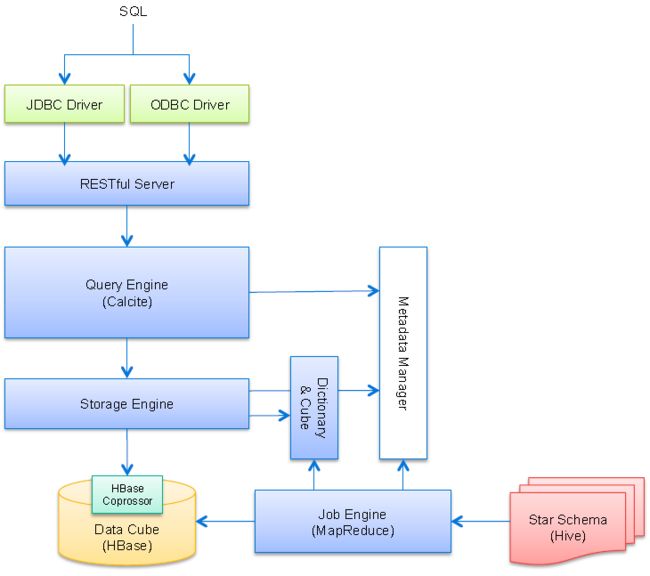
体系结构:

• Hive
– Pre-join star schema during cube building
• MapReduce
– Pre-aggregation metrics during cube building
• HDFS
– Store intermediated files during cube building.
• HBase
– Store data cube.
– Serve query on data cube.
– Coprocessor is used for query processing.
Kylin查询:
Kylin support ANSI-SQL: projection, filter, join, aggregation, groups and sub-query

分析查询分类
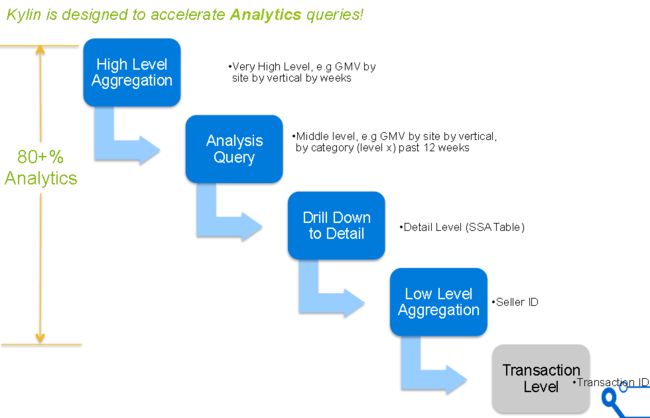
组件设计
Cube设计
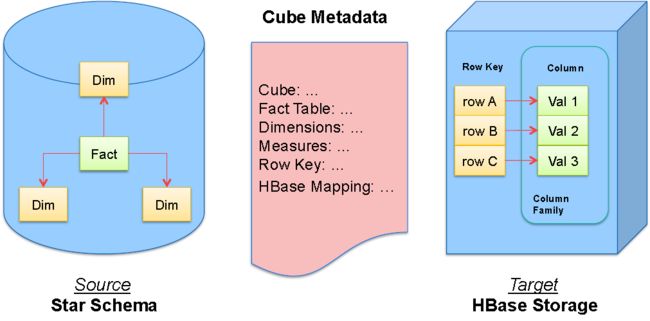
Cube元数据
• Dimension
– Normal
– Mandatory
– Hierarchy
– Derived
•Measure
– Sum
– Count
– Max
– Min
– Average
– Distinct Count (based on HyperLogLog)
如何build cube
1.key-value

2.job流
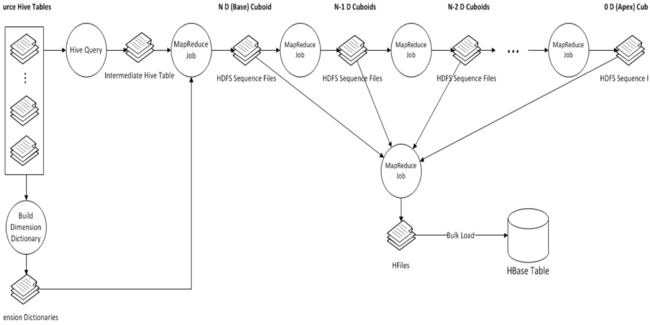
3.存储Cube:HBase模式
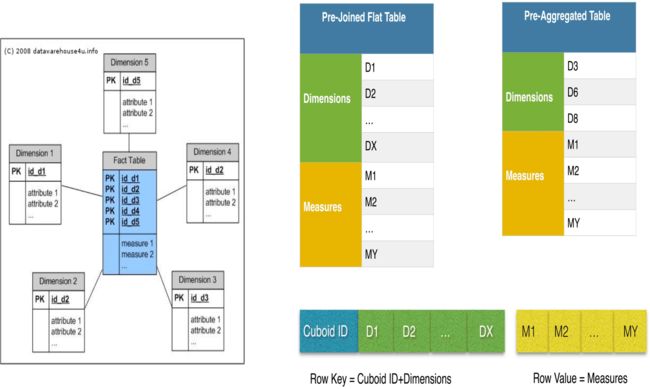
4.Cube查询:查询引擎
• Query engine: is based on Apache Calcite (http://incubator.apache.org/projects/calcite.html)
• Apache Calcite: is an extensible open source SQL engine that is also used in Stinger/Drill/Cascading.
• Metadata SPI
– Provide table schema from kylin metadata
• Optimize Rule
– Translate the logic operator into kylin operator
• Relational Operator
– Find right cube
– Translate SQL into storage engine api call
– Generate physical execute plan by linq4j java implementation
• Result Enumerator
– Translate storage engine result into java implementation result.
• SQL Function
– Add HyperLogLog for distinct count
– Implement date time related functions (i.e. Quarter)

解释计划:

存储引擎:
• Provide cube query for query engine
– Common iterator interface for storage engine
– Isolate query engine from underline storage
• Translate cube query into HBase table scan
– Groups à Cuboid ID
– Filters -> Scan Range (Row Key)
– Aggregations -> Measure Columns (Row Values)
• Scan HBase table and translate HBase result into cube result
– HBase Result (key + value) -> Cube Result (dimensions + measures)
优化Cube:
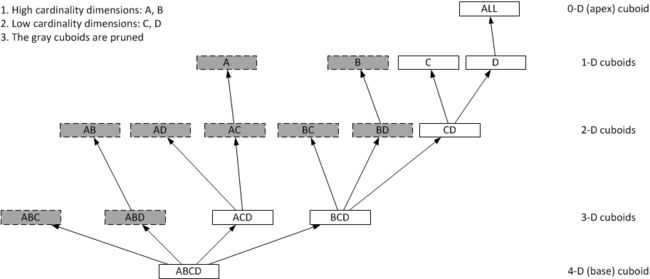
• “Curse of dimensionality”: N dimension cube has 2N cuboid
– Full Cube vs. Partial Cube
Full Cube
– Pre-aggregate all dimension combinations
– “Curse of dimensionality”: N dimension cube has 2N cuboid.
Partial Cube
– To avoid dimension explosion, we divide the dimensions into different aggregation groups
• 2N+M+L à 2N + 2M + 2L
– For cube with 30 dimensions, if we divide these dimensions into 3 group, the cuboid number will reduce from 1 Billion to 3 Thousands
• 230 à 210 + 210 + 210
– Tradeoff between online aggregation and offline pre-aggregation
• Hugh data volume
– Dictionary Encoding
• Data cube has lost of duplicated dimension values
• Dictionary maps dimension values into IDs that will reduce the memory and storage footprint.
• Dictionary is based on Trie

– Incremental Building

• Slow Table Scan – TopN Query on High Cardinality Dimension
– Bitmap inverted index
– Time range partition
– Separate high cardinality dimension from low cardinality dimension
– In-memory +parallel scan: block cache + endpoint coprocessor

Kylin里程碑:

相关资源:
• Web Site
– http://kylin.io
• Google Groups
– https://groups.google.com/forum/#!forum/kylin-olap
• Twitter
– @KylinOLAP
• Source Code
– https://github.com/KylinOLAP/Kylin