目录
- 总
- 架构
- Controller
- Model
- 输入处理
- 架构
- 代码静态分析
- 行数
- 方法复杂度
- UML 类图
- 优点
- 缺点
- 坑
- 输入
- 非法的空白字符
- 输入的简并处理
- 运算
- 浅拷贝
- 可变类型与不可变类型
- 输出
- 表达式因子的优化
- 输入
- 互测策略
- 测试集测试
- 针对性测试
- 脚本测试
- Creational Pattern
总
本博文是2019年北航面向对象(OO)课程第一单元作业(多项式求导)的总结。三次作业的要求大致如下:
- 第一次作业:简单幂函数的求导,如 \(1 + x^5 + 4 * x^3\)
- 第二次作业:简单幂函数和简单正余弦函数的求导,如 \(-5*sin(x)^2+5*cos(x)*cos(x)+12*x^2\)
- 第三次作业:简单幂函数和有嵌套的正余弦函数的求导,如 \(2*(cos(x) + 1)*cos((2*x)) - sin(x)*sin((2*x))\)
源代码及项目要求均已发布到 github ,读者可以下载检查。以下将对这一单元作业进行简单总结。
架构
项目的总体构架参考 \(MVC\) 模式,将运算与输入输出分离。由于输入输出都是在 \(console\) 完成的,因此并没有 \(view\) 类,但 \(Model\) 和 \(Controller\) 都有其对应类。
Controller
输入处理类 \(PolyBuild\) ,负责将输入字符串组织成一个 \(Poly\) 对象。其中按层次包含五个解析方法:
- \(parsePoly\)
- \(parseItem\)
- \(parseFactor\)
- \(parseElement\)
- \(parseTri\)
方法的功能显而易见,采取递归下降法应用有限状态机对字符串进行解析。
Model
\(Model\) 对应 \(Package\ Poly\) 。如下 \(UML\) 图所示,我将多项式分为四个层次:
- \(Element\) :底层类,构成多项式的最基本元素,也是因子的底数。包括 \(Const\), \(Var\), 和 \(Tri\) 。
- \(Factor\) :因子类,构成项的单元,属于指数函数。由一个 \(Element\) 和其对应的 \(exp\) 对应。
- \(Item\) :项类,构成多项式的单元,由多个 \(Factor\) 或表达式因子相乘组成。
- \(Poly\) :顶层类,由多个 \(Item\) 相加构成。
每个类实现各自的求导方法和输出方法( \(toString()\) ) 。
输入处理
处理输入字符串时,我采用了递归下降法,按层用状态机进行处理。状态机如图:
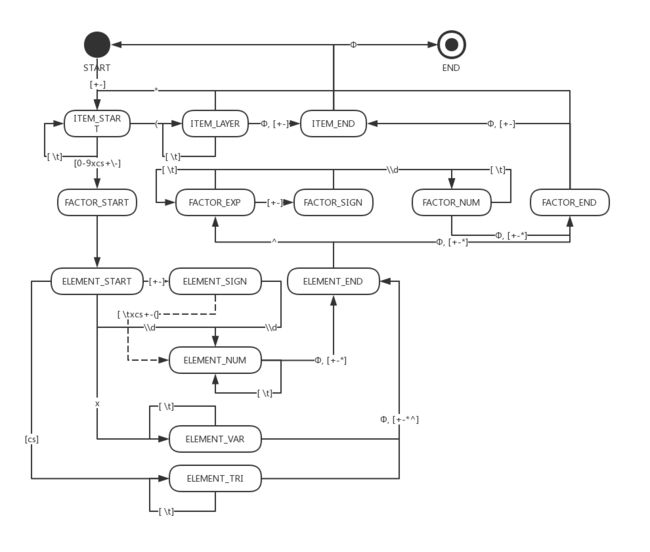
上图为示意图,图中状态可能附加处理操作,并没有列出,读者可以下载代码查看。虚线表示状态转移时,输入字符串会被改变。线上字符表示状态转移规则,即当前光标下的字符,但并不是每次状态转移光标都会移至下一位。\(\phi\) 表示光标到达字符串结尾。
代码静态分析
以下使用 \(Metrics\) 和 \(Statistics\) 插件对最终项目代码进行静态分析。
行数
| Source File | Total Lines | Source Code Lines | Source Code Lines[%] | Comment Lines | Comment Lines[%] | Blank Lines | Blank Lines[%] |
|---|---|---|---|---|---|---|---|
| Const.java | 88 | 68 | 0.77 | 4 | 0.04 | 16 | 0.18 |
| Derivable.java | 20 | 14 | 0.70 | 0 | 0.0 | 6 | 0.30 |
| Element.java | 60 | 44 | 0.73 | 4 | 0.06 | 12 | 0.20 |
| Factor.java | 146 | 113 | 0.77 | 11 | 0.07 | 22 | 0.15 |
| Item.java | 294 | 255 | 0.86 | 8 | 0.02 | 31 | 0.10 |
| Poly.java | 189 | 158 | 0.83 | 8 | 0.04 | 23 | 0.12 |
| PolyBuild.java | 348 | 307 | 0.88 | 11 | 0.03 | 30 | 0.08 |
| PolyBuildTest.java | 30 | 24 | 0.80 | 0 | 0.0 | 6 | 0.20 |
| Se.java | 7 | 7 | 1.00 | 0 | 0.0 | 0 | 0.0 |
| Tri.java | 71 | 56 | 0.78 | 7 | 0.09 | 8 | 0.11 |
| TriParseException.java | 2 | 2 | 1.00 | 0 | 0.0 | 0 | 0.00 |
| TypeEnum.java | 7 | 6 | 0.85 | 0 | 0.0 | 1 | 0.14 |
| Var.java | 25 | 19 | 0.76 | 0 | 0.0 | 6 | 0.24 |
可见代码中注释比例偏低,但空行比例较高。类长度和其复杂度成正比。其中 \(PolyBuild\) 由于包含输入状态机,复杂度最高;\(Poly\) , \(Item\), \(Factor\) 三类的求导操作较复杂,复杂度次之。
方法复杂度
| class | OCavg | WMC |
|---|---|---|
| poly.element.Const | 1.23 | 16.0 |
| poly.element.Element | 1.00 | 7.0 |
| poly.element.Tri | 2.00 | 12.0 |
| poly.element.TypeEnum | 0.0 | |
| poly.element.Var | 1.00 | 4.0 |
| poly.Factor | 1.55 | 28.0 |
| poly.Item | 2.28 | 64.0 |
| poly.Poly | 2.04 | 43.0 |
| PolyBuild | 8.37 | 67.0 |
| PolyBuild.StringIterator | 1.42 | 20.0 |
| PolyBuildTest | 1.00 | 4.0 |
| Se | 0.0 | |
| TriParseException | 0.0 | |
| Total | 265.0 | |
| Average | 2.154471544715447 | 20.384615384615383 |
可见 \(PolyBuild\) 类的复杂度最高,约为平均值的 \(4\) 倍。而加入权重计算时,\(PolyBuild\) 和 \(Item\) 类复杂度基本相同。
UML 类图
优点
类的内剧度高,类间逻辑关系清晰。\(UML\) 图中从上至下为 \(Element\), \(Factor\), \(Item\), \(Poly\) 类,与逻辑关系相同。说明每个类都直接与其前驱类相关,而与其他类关联度较低。
缺点
\(Item\), \(Poly\) 类的复杂度较高,尤其在求导时会进入递归,给调试造成困扰。
坑
此处记录了一些在开发过程中遇到的 \(Bug\) ,希望通过反思总结警醒自己。按照这些 \(Bug\) 的出现位置,我将其大致分为输入、运算以及输出三个部分。每个部分都多多少少有一些 \(Bug\) ,证实了老师所说“不存在没有 \(Bug\) 的代码”。许多 \(Bug\) 十分隐蔽,需要大量测试才能发现。因此即使从逻辑上完备的测试了代码,仍然需要更多测试,以检测正确性。
输入
输入处理在这单元作业中最为繁琐且易出错,其原因主要在于识别非法输入。正确识别合法的字符串并不困难,但一不小心很有可能将非法字符串当作合法输入进行处理。结合被检查出的 \(Bug\) ,我发现我对于字符出现的不同组合仍然考虑不全,因此将一些非法字符串误认为合法进行解析。发现这个问题后,我在状态机的转移图中检查了所有可能出现的字符,这才避免了后续输入上的 \(Bug\) 。输入部分的 \(Bug\) 全部出现在解析类 \(PolyBuild\) 中。
非法的空白字符
在第一次作业中,最关键的 \(Bug\) 出现在非法的空白字符。由于允许的空白字符只有 和 \(\t\), 但 \(Java\) 中默认的 \(String.trim\) 方法会将字符串首尾的全部空白字符删去。
位置
\(PolyBuild.main(String[])\)
样例输入
\f 1 + x在调用 \(trim\) 方法时 \(\f\) 将被删去。但 \(\f\) 的存在使整体字符串不合法。因此这样的处理会将一些包含非法空白字符的输入当作合法输入处理。
解决方法
针对非法空白字符的解决方法主要有两个:
- 在获得输入后进行合法字符筛查。若输入中存在非法字符则直接报错,不进行后续处理。这种方法简单直观,且向后兼容性更强。当需求有变化时只需要在合法字符集中加入对应的字符即可。
- 在处理字符串时检查,例如在状态机中检查每个位置的字符是否合法。这种方法的耦合度较高,因为合法字符集分散在状态机各处,且判断逻辑复杂,不易发现 \(Bug\) 。但优点在于,这样的方法可以提高效率。输入合法性不需要单独判断,而是在处理输入的同时进行。
反思
这一问题的原因在于没有区分空白字符的合法性,误认为空白字符即合法。
输入的简并处理
在第一次作业指导书中就提到
表达式由加法和减法运算符连接若干项组成…在第一项之前,可以带一个正号或者负号
这样的要求就使得第一项前的运算符变成可选项,但后续各项都可以解析为一个运算符(\([+-]\))和一个项的形式。为了统一每项的解析方式,我在处理字符串前将其 \(trim\) 并在其头部加入 \(“+0”\) 。这样的处理可以简并以下情况
12 * x -> +012 * x
+12 * x -> +0+12 * x
+ 12 * x -> +0+ 12 * x
+ +12 * x -> +0+ +12 * x同时考虑到如下的以 \(x\) 开头的表达式
x ^ 2我对字符串的首个非空白字符进行了特判。若其为 \(x\) 则只补全 \(“+”\) 而不输出 \(“0”\) 。即
x ^ 2 -> +x ^ 2位置
\(PolyBuild.main(String[])\)
样例输入
*x -> +0*x由输入可以看出,原本非法的表达式被当作合法输入进行解析。这一问题的出现即是因为事先没有考虑到 \(“*”\) 作为表达式第一个字符出现的可能性。但从逻辑的角度看,\([+-*\^0-9x]\) 均为合法字符,应考虑到其在字符串开头出现的可能性。
解决方法
最直接且行之有效的解决方法是加入对于 \(“*”\) 的特判。若 \(“*”\) 是字符串的首个非空字符,则报错。但这样的判断显然不够简洁。
另一种方法是判断字符串的首个非空字符是否为操作符 \([+-]\) ,若非,则在字符串(\(trim\) 前)的开头加入 \(“+”\) 。可以证明,这种方法可以完美的保留原输入的合法性。
反思
这一问题主要是因为对于字符串开头可能存在的字符考虑不全。在后面修改状态机时,我在每个状态都排查了所有合法输入的可能,确保了状态机的正确性。每行代码都需要推敲与证明。
运算
运算主要是对于一个多项式完成加、减、乘、求导等操作。由于已经经过输入部分的处理,因此不必在考虑非法输入的问题,只需要对合法多项式进行对应操作即可。这部分的难度较低,但由于 \(Poly\) 类和 \(Item\) 类的底层数据结构均为集合,涉及到了拷贝问题,还是引发了一些问题。
浅拷贝
浅拷贝问题发生在构造新对象时。这一问题不仅存在于 \(Item\) 类和 \(Poly\) 类中,还存在于 \(Factor\) 类和 \(Element\) 子类中。由于构造方法中简单的进行赋值,就造成了多个对象中的属性指向同一个元素。操作一个对象时会改变其他对象的值。
位置
所有类的构造方法。
样例输入
记不清了…
解决方法
我最开始的解决方法是调用者负责 \(clone\) ,但构造函数一多,这样的解决办法很容易出错。因此我后来将 \(clone\) 的调用转移到构造方法中,虽然增加了复杂度,但代码更加简洁。
反思
这一问题的出现让我直接把 \(Element\) 和 \(Factor\) 改造成了不可变对象,每次调用其方法时必须申请新变量。这样的措施虽然有效,却没有根除问题。事实上,这一问题在作业 \(3\) 的整个开发过程中一直存在,直到提交前才被解决。这几乎是本项目设计上最严重的问题,应该从构架时着手思考。在以后项目开发的过程中,我会更加留意深浅拷贝的问题。
可变类型与不可变类型
在第三次作业中,由于出现了因子的嵌套,可变性的问题才显得尤其突出。尽管我在编码时尽量把类构造成不可变对象,且每个类都显式重写了 \(Object.equals(Object)\) 方法。但 \(Item\) 类与 \(Poly\) 类的构造方法中调用了本类的 \(mult()\) 和 \(add()\) 方法,因而不能完全构造成不可变对象。对这一问题,我的解决方法是构造私有的 \(mult()\) 和 \(add()\) 方法,供类内部使用。而外部调用 \(mult()\) 和 \(add()\) 方法时通过公共方法 \(mult(Derivable)\) 和 \(add(Derivable)\) 获得新对象。这样在类的内部,\(Item\) 类与 \(Poly\) 类是可变类型对象;在类的外部,\(Item\) 类与 \(Poly\) 类仿佛是不可变对象。但这决定了在 \(Item\) 类和 \(Poly\) 类的内部可能存在可变类型与不可变类型混淆的情况。
位置
\(Item.mult\) 方法(由于 \(Debug\) 过程较为复杂,具体哪个重载方法记不清了…)
样例输入
sin(sin(x))错误输出:
cos(sin(x))解决方法
该问题的解决并不困难,只要定位到 \(Bug\) 并将返回值(新对象)赋值即可。难点主要在于 \(Bug\) 定位,因为带嵌套的表达式会进入递归。我采取的是二分定位的方法,将程序分成若干片段,在每个递归程序间设置断点,定位到程序片之后再进入递归跟踪断点。
反思
这一问题是由于 \(Item\) 类和 \(Poly\) 类的可变性引起的。我在编码时就预感到这样的设计可能导致 \(Bug\) ,但还是没有将所有情况考虑完备。如果将 \(Item\) 类和 \(Poly\) 类完全设计为可变类型,虽然在调用者处需要显式调用 \(clone\) 方法,但却解决了类型可变性的问题。只是这样的修改成本较大,在后期我没有采用这样的方法。
输出
输出部分的难点集中在判断和调用子类的 \(toString()\) 方法。比如一个 \(Item\) 类包含两个 \(Factor\) ,\(1\) 和 \(x^2\) 。应输出 \(+x^2\) ,但单独调用每个 \(Factor\) 的 \(toString()\) 方法并拼接将会生成 \(+1*x^2\) 。由此可知,输出的问题可能出现在优化中。
表达式因子的优化
在优化作业 \(3\) 时,由于涉及到合并同类项,\(Item\) 类的输出会包含表达式因子。这是一个十分复杂的过程,因为表达式因子的括号在某些情况下是可以省略的(如果表达式因子只有一个 \(Factor\))。问题出现在表达式因子的第一项包含省略时,即形如 \(+x^2\) 的情况。若表达式因子的括号被省略,那么在这个 \(Item\) 中将会出现非第一项被省略的情况,即形如 \(4*x^5*+sin(x)\) 。
位置
\(Item.toString()\)
样例输入
不考虑求导过程,即调用
System.out.println(new PolyBuild(string).parsePoly())时,若输入
4*x^5*5*sin(x)-4*x^5*4*sin(x)将会产生输出:
4*x^5*+sin(x)解决方法
在合并同类项时,加入判断表达式因子是否可以转发为其他因子。若表达式因子只含一个 \(Item\) ,则将其转化为 \(Item\) 与本类相乘。
反思
为了使优化更加简单,不易出错,应将优化过程前移至最开始可以优化的位置。以合并同类项为例,在项与表达式因子相乘时即可开始优化。如果在运算完成后在进行优化,一方面需要访问多个类的私有方法,破坏了封装性;另一方面操作过于复杂,容易引发错误。
互测策略
一般来说,我测试其他人代码分为三个步骤:
- 利用针对自己代码的测试集进行测试
- 阅读代码,针对性测试
- 利用脚本大量测试
测试集测试
一般情况下,这种测试方法只能检查程序的基本表现。由于测试集是针对我的代码编写的,尽管从我的编码逻辑上做到了覆盖,但并不一定能覆盖他人的代码。因此这一轮测试只是检查他人代码能否完成最基本的求导操作。
针对性测试
这个阶段我会阅读对方代码。阅读重点放在输入和输出的处理,因为运算部分比较简单。如果有比较明显的逻辑错误,在这个阶段就可以暴露出来。如果阅读一遍没有发现问题,我会查看运算部分的逻辑,同时编写测试集进行测试。但是这里的测试集一般不能做到覆盖,只是针对顶层的逻辑进行检查,否则没有时间测试更多代码。
脚本测试
脚本测试一般和阅读代码同时进行,因为测试量较大,运行时间长( \(5000\) 个测试样例一般需要 \(15\sim20\) 分钟)。如果前两个阶段都没有发现问题,脚本生成的随机输入可以全面检查程序的正确性。大部分 \(Bug\) 都会在这个阶段被发现。
Creational Pattern
在开始写这一单元项目的时候,我对设计模式还没有很全面的了解,因此没有运用。但后来查阅相关资料发现原型模式很适合我的项目。由于我的所有类都继承自 \(Derivable\) 接口,而且所有类都重写了 \(clone\) 方法(由于 \(Derivable\) 接口继承了 \(Cloneable\) 接口,因此必须重写)。我认为重构可以在 \(Derivable\) 接口中加入默认的 \(clone\) 方法,并子类的构造方法融入 \(clone\) 方法中。这样不仅可以加快程序的运行速度,还能更严格的保证对象的不可变性。
(\(P.S.\) 不知道 Applying Creational Pattern 是不是设计模式的意思…)