排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题。LTR有三种主要的方法:PointWise,PairWise,ListWise。ListNet算法就是ListWise方法的一种,由刘铁岩,李航等人在ICML2007的论文Learning to Rank:From Pairwise approach to Listwise Approach中提出。
Pairwise方法的实际上是把排序问题转换成分类问题,以最小化文档对的分类错误为目标。但是评估排序结果的好坏通常采用MAP或NDCG等考虑文档排序的方法,所以Pairwise方法的损失函数并不是非常合适。 ListNet算法定义了一种Listwise的损失函数,该损失函数表示由我们的模型计算得来的文档排序和真正的文档排序之间的差异,ListNet最小化该损失函数以达到排序的目的。
ListNet首先把文档的排序列表转换成概率分布,然后选取交叉熵来衡量由模型训练出的文档排序和真正的文档排序之间的差异,最小化这个差异值来完成排序。下面我们从如何把文档列表转换成概率,如何计算概率分布之间的差异值,如何优化差异值三个部分来介绍ListNet算法。
1. 组合概率和Top-K概率。
(1) 组合概率.
假设我们需要对n篇文档进行排序,我们用π=<π(1),π(2),...,π(n)>表示一种排列组合,其中π(i)表示排列在第i个位置的文档。设Φ(.)是一个递增和恒大于0的函数,Φ(x)可以是线性函数Φ(x)=αx或者指数函数Φ(x)=exp(x),则排列组合π的概率为:
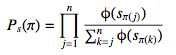
其中Sπ(j)表示排列在第j个位置的文档的得分。组合概率的计算复杂度为O(n!),当文档的数量较多时,计算量太大,所以ListNet选用了另外一种概率:Top-K概率。
(2) Top-K概率.
序列(j1,j2,...,jk)的Top-K概率表示这些文档排在n个文档中前K个的概率。在定义Top-K概率之前,需要首先定义前K个文档为(j1,j2,...,jk)的文档排序的Top-K Subgroup:
![]()
而Gk代表所有的Top-K Subgroup集合:

Gk中总共有N!/(N-k)!种不同的组合,大大低于组合概率的N!种组合。
n个文档中(j1,j2,...,jk)排在前k个的概率,亦即(j1,j2,...,jk)的Top-K概率为:
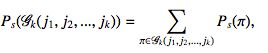
(j1,j2,...,jk)的Top-K概率的计算方法为:
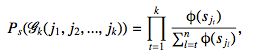
2. 计算概率分布的差异值
在得到利用模型训练出的文档排序和真正的文档排序的概率分布之后,我们可以使用多种方法来计算两个概率分布之间的差异值作为损失函数,ListNet采用交叉熵来计算两个概率分布之间的差异。
两个概率分布p和q之间的交叉熵定义为:
![]()
在ListNet中,假设Py(i)(g)表示实际的文档排序g的概率,而Pz(i)(g)表示模型计算得来的文档排序g的概率,则两个文档排序概率分布之间的交叉熵为:

3. 优化损失函数
ListNet使用神经网络来计算文档的得分值,选取Φ(x)=exp(x),然后使用梯度下降(Gradient Descent)的方法来不断更新神经网络的参数ω, 最小化损失函数, ω的迭代公式如下:
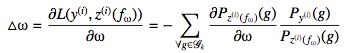
参考文献:
[1]. Learning to Rank: From Pairwise Approach to Listwise Approach. Zhe Cao, Tao Qin, Tie-yan Liu, Ming-Feng Tsai, Hang Li. ICML 2007
[2]. Learning to Rank for Information Retrieval and Natural Language Processing. Hang Li