郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
今天的人工智能仍然面临两大挑战。一种是,在大多数行业中,数据以孤岛的形式存在。二是加强数据隐私和安全。我们提出了一个解决这些挑战的可能方案:安全联邦学习。除了谷歌在2016年首次提出的联邦学习框架外,我们还引入了一个全面的安全联邦学习框架,其中包括横向联邦学习、纵向联邦学习和联邦迁移学习。我们为联邦学习框架提供定义、架构和应用程序,并提供关于这个主题的现有工作的全面调查。此外,我们提出在组织之间建立基于联邦机制的数据网络,作为一种有效的解决方案,以允许在不损害用户隐私的情况下共享知识。
1 INTRODUCTION
2016年是人工智能(AI)成熟的一年。随着AlphaGo[59]击败了顶尖的人类围棋玩家,我们真正见证了人工智能(AI)的巨大潜力,并开始期望在许多包括无人驾驶汽车、医疗保健、金融等的应用中,使用更复杂、尖端的人工智能技术。如今,人工智能技术在几乎所有行业都能发挥其优势。然而,回顾人工智能的发展历程,人工智能的发展必然经历了几次起伏。人工智能会有下一个转弯吗?什么时候会出现?因为什么因素?当前公众对人工智能感兴趣的部分是由大数据可用性驱动的:2016年,AlphaGo使用了总计300000盘比赛作为训练数据,以取得优异的成绩。
随着AlphaGo的成功,人们自然希望像AlphaGo这样的大数据驱动的人工智能能够在我们生活的各个方面很快实现。然而,现实情况有些令人失望:除了少数行业外,大多数领域的数据都很有限或质量较差,使得人工智能技术的实现比我们想象的要困难。是否可以通过跨组织传输数据,将数据融合到一个公共站点中?事实上,在许多情况下,打破数据源之间的障碍即使不是不可能的,也是非常困难的。一般来说,任何人工智能项目所需的数据涉及多种类型。例如,在人工智能驱动的产品推荐服务中,产品销售商拥有产品信息、用户购买数据,但没有描述用户购买能力和支付习惯的数据。在大多数行业中,数据以孤岛的形式存在。由于行业竞争、隐私安全和复杂的管理程序,甚至同一公司不同部门之间的数据集成也面临着巨大的阻力。几乎不可能将分散在全国各地的数据和机构进行整合,否则成本是难以承受的。

与此同时,随着大公司在数据安全和用户隐私方面的妥协意识日益增强,对数据隐私和安全的重视已成为世界性的重大问题。有关公开数据泄露的消息引起了公众媒体和政府的极大关注。例如,最近Facebook的数据泄露引发了广泛的抗议[70]。作为回应,世界各国正在加强保护数据安全和隐私的法律。例如,欧盟于2018年5月25日实施的《通用数据保护条例》(GDPR)[19]。GDPR(图1)旨在保护用户的个人隐私和数据安全。它要求企业在用户协议中使用清晰明了的语言,并授予用户“被遗忘的权利”,即用户可以删除或撤回其个人数据。违反该法案的公司将面临严厉的罚款。美国和中国也在制定类似的隐私和安全行为。例如,2017年颁布的《中国网络安全法》和《民法通则》要求互联网企业不得泄露或篡改其收集的个人信息,在与第三方进行数据交易时,必须确保提议的合同遵循法律数据保护义务。这些法规的建立将明显有助于建立一个更加文明的社会,但也将对人工智能中常用的数据处理程序提出新的挑战。
更具体的说,人工智能中的传统数据处理模型通常涉及简单的数据交易模型,一方收集数据并将其传输给另一方,另一方负责数据的清理和融合。最后,第三方将获取集成数据并构建模型供其他方使用。这些模型通常作为最终的服务产品进行销售。这一传统程序面临着上述新数据法规和法律的挑战。此外,由于用户可能不清楚模型的未来用途,因此这些交易违反了GDPR等法律。因此,我们面临着这样一个困境:我们的数据是以孤岛的形式存在的,但是在许多情况下,我们被禁止收集、融合和使用数据到不同的地方进行人工智能处理。如何合法地解决数据碎片化和隔离问题是当今人工智能研究者和实践者面临的主要挑战。
2 AN OVERVIEW OF FEDERATED LEARNING
联邦学习的概念最近由谷歌提出[36,37,41]。他们的主要想法是建立基于分布在多个设备上的数据集的机器学习模型,同时防止数据泄漏。最近的改进集中在克服统计挑战[60,77]和提高联邦学习的安全性[9,23]。还有一些研究努力使联邦学习更具个性化[13,60]。以上工作都集中在设备联邦学习上,涉及分布式移动用户交互,并且大规模分发中的通信成本、不平衡的数据分布和设备可靠性是优化的主要因素之一。此外,数据是通过用户ID或设备ID进行划分的,因此,在数据空间中是横向的。这一类工作与隐私保护机器学习(privacy-preserving machine learning,如[58])非常相关,因为它还考虑了分散协作学习设置中的数据隐私。为了将联邦学习的概念扩展到涵盖组织间的协作学习场景,我们将原始的“联邦学习”扩展成所有隐私保护分散协作机器学习技术的一般概念。在[71]中,我们对联邦学习和联邦迁移学习技术进行了初步概述。在本文中,我们进一步调查了相关的安全基础,并探讨了与其他几个相关领域的关系,如多代理理论和隐私保护数据挖掘。在本节中,我们提供了一个更全面的联邦学习定义,它考虑了数据划分、安全性和应用程序。我们还描述了联邦学习系统的工作流和系统架构。
2.1 Definition of Federated Learning

2.2 Privacy of Federated Learning
隐私是联邦学习的基本属性之一。这需要安全模型和分析来提供有意义的隐私保证。在本节中,我们简要回顾和比较联邦学习的不同隐私技术,并确定防止间接泄漏的方法和潜在挑战。
安全多方计算(SMC):SMC安全模型自然包含多方,并在一个定义明确的仿真框架中提供安全证明,以保证完全零知识,即除了输入和输出之外,各方什么都不知道。零知识是非常可取的,但这种要求的属性通常需要复杂的计算协议,并且可能无法有效地实现。在某些情况下,如果提供了安全保证,则可以认为部分知识披露是可接受的。在安全性要求较低的情况下,可以用SMC建立安全模型,以换取效率[16]。最近,研究[46]使用SMC框架对具有两个服务器和半诚实假设的机器学习模型进行训练。参考文献[33]使用MPC协议进行模型训练和验证,无需用户透露敏感数据。最先进的SMC框架之一是ShareMind[8]。参考文献[44]提出了一个3PC模型[5,21,45],以诚实的多数,并考虑了在半诚实和恶意假设中的安全性。这些工作要求参与者的数据在非协作服务器之间秘密共享。
差异隐私:另一项工作使用差分隐私技术[18]或k-匿名[63]来保护数据隐私[1,12,42,61]。差异隐私、k-匿名和多样化[3]的方法涉及在数据中添加噪声,或使用泛化方法来模糊某些敏感属性,直到第三方无法区分个体,从而使数据无法还原来保护用户隐私。然而,这些方法的根源仍然要求数据传输到别处,而这些工作通常涉及准确性和隐私之间的权衡。在[23]中,作者介绍了联邦学习的差异隐私方法,以便通过在训练期间隐藏客户的贡献来增加对客户机端数据的保护。
同态加密:在机器学习过程中,也可以采用同态加密[53]的方法,通过加密机制下的参数交换来保护用户数据隐私[24、26、48]。与差异隐私保护不同,数据和模型本身不会被传输,也不能通过另一方的数据对其进行推测。因此,原始数据级别的泄漏可能性很小。最近的工作采用同态加密来集中和训练云上的数据[75,76]。在实践中,加法同态加密[2]被广泛使用,需要进行多项式近似来评估机器学习算法中的非线性函数,从而在准确性和隐私性之间进行权衡[4,35]。
2.2.1 Indirect information leakage
联邦学习的先驱工作揭示了诸如随机梯度下降(SGD)等优化算法的参数更新等中间结果,但是没有提供安全保证。当与数据结构(如图像像素)一起曝光时,这些梯度的泄漏实际上可能泄漏重要的数据信息[51]。研究人员已经考虑到这样一种情况:联邦学习系统的一个成员通过植入后门来学习其他人的数据,恶意攻击其他人。在[6]中,作者证明了在一个联邦全局模型中植入隐藏后门的可能性,并提出了一种新的“约束和缩放”模型中毒法来减少数据中毒。在[43]中,研究人员发现了协作机器学习系统中存在的潜在漏洞,在该系统中,不同参与方在协作学习中使用的训练数据容易受到推理攻击。他们表明,一个敌对的参与者可以推断成员资格以及与训练数据子集相关的属性。他们还讨论了针对这些攻击的可能防御措施。在[62]中,作者揭示了与不同方之间的梯度交换有关的潜在安全问题,并提出了梯度下降法的一种安全变体,并表明它可以容忍一定常数比例的拜占庭用户(参见拜占庭将军问题)。
研究人员也开始考虑将区块链作为促进联邦学习的平台。在[34]中,研究人员考虑了一种区块链联邦学习(BlockFL)结构,其中移动设备的本地学习模型更新通过区块链进行交换和验证。他们考虑了最佳块生成、网络可扩展性和鲁棒性问题。
2.3 A Categorization of Federated Learning
在本节中,我们将讨论如何根据数据的分布特征对联邦学习进行分类。

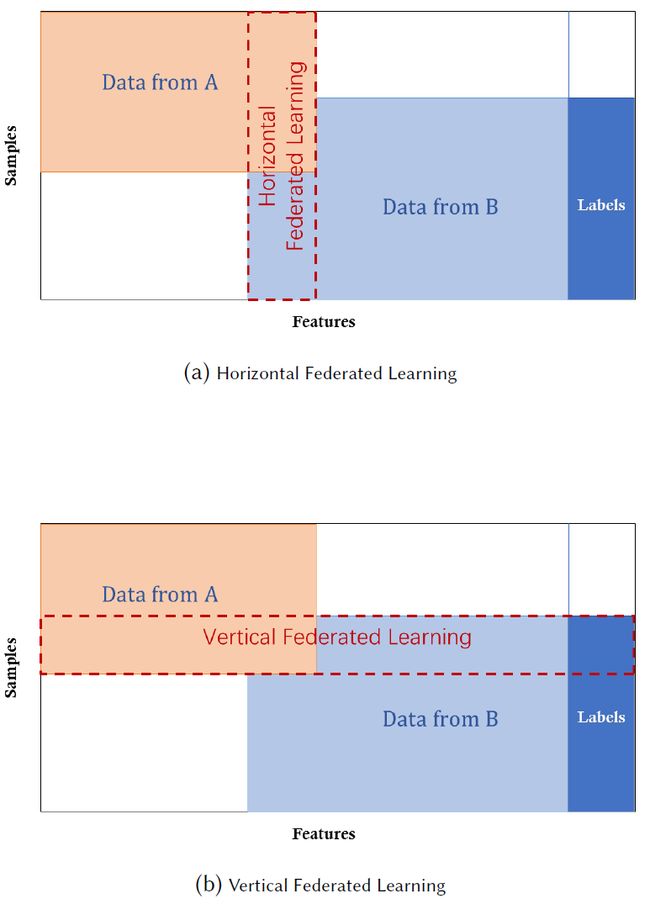

2.3.1 Horizontal Federated Learning
横向联邦学习,或者基于样本的联邦学习,被引入到数据集共享相同的特征空间,但样本不同的场景中(图2a)。例如,两个区域性银行的用户组可能由于各自的区域非常不同,其用户的交叉集非常小。但是,它们的业务非常相似,因此特征空间是相同的。参考文献[58]提出了一个协作式深度学习方案,参与者独立训练,只共享参数更新的子集。2017年,谷歌提出了一个横向联邦学习解决方案,用于Android手机模型更新[41]。在该框架中,使用Android手机的单个用户在本地更新模型参数,并将参数上传到Android云,从而与其他数据所有者共同训练集中式模型。[9]还介绍了一种安全的聚合方案,以保护在联邦学习框架下聚合用户更新的隐私。参考文献[51]对模型参数聚合使用加法同态加密来提供对中央服务器的安全性。
在[60]中,提出了一种多任务风格的联邦学习系统,允许多个站点在共享知识和维护安全的同时完成不同的任务。他们提出的多任务学习模型还可以解决高通信成本、分散和容错问题。在[41]中,作者提出构建一个安全的客户机-服务器结构,在该结构中,联邦学习系统按用户划分数据,并允许在客户机设备上构建的模型,用来在服务器站点上协作,以构建一个全局联邦模型。模型的建立过程确保了数据不泄漏。同样,在[36]中,作者提出了提高通信成本的方法,以便于基于分布在移动客户端上的数据对训练得到集中式模型。近年来,为了在大规模分布式训练中大幅度降低通信带宽,[39]提出了一种称为深度梯度压缩的压缩方法。
我们将横向联邦学习总结为:
![]()
安全定义:横向联邦学习系统通常假设诚实的参与者和对于诚实但好奇的服务器的安全性[9,51]。也就是说,只有服务器才能危害数据参与者的隐私。这些工作提供了安全证明。最近,另一个考虑恶意用户[29]的安全模型也被提出,这给隐私带来了额外的挑战。在训练结束时,通用模型和整个模型参数将向所有参与者公开。
2.3.2 Vertically Federated Learning. 针对纵向分割数据,提出了隐私保护机器学习算法,包括协同统计分析[15]、关联规则挖掘[65]、安全线性回归[22,32,55]、分类[16]和梯度下降[68]。最近,参考文献[27,49]提出了一个纵向联邦学习方案来训练一个隐私保护逻辑回归模型。作者研究了实体分辨率对学习性能的影响,并将泰勒近似应用于损失函数和梯度函数,使同态加密可以用于隐私保护计算。
纵向联邦学习,或基于特征的联邦学习(图2b)适用于两个数据集共享相同的样本ID空间,但特征空间不同的情况。例如,考虑同一城市中的两个不同公司,一个是银行,另一个是电子商务公司。他们的用户集可能包含该区域的大多数居民,因此他们的用户空间的交叉很大。然而,由于银行记录了用户的收支行为和信用评级,电子商务保留了用户的浏览和购买历史,所以其特征空间有很大的不同。假设我们希望双方都有一个基于用户和产品信息的产品购买预测模型。
纵向联邦学习是将这些不同的特征聚合在一起,以一种隐私保护的方式计算训练损失和梯度的过程,以便用双方的数据协作构建一个模型。在这种联邦机制下,每个参与方的身份和地位是相同的,联邦系统帮助每个人建立“共同财富”策略,这就是为什么这个系统被称为“联邦学习”。因此,在这样一个系统中,我们有:
![]()
安全定义:纵向联邦学习系统通常假设参与者诚实但好奇。例如,在两党制的情况下,两党是不串通的,而且其中至多有一方会向对手妥协。安全性定义是,对手只能从其损坏的客户机中获取数据,而不能从输入和输出显示的其他客户机中获取数据。为了便于双方安全计算,有时会引入半诚实第三方(STP),在这种情况下,假定STP不会与任何一方串通。SMC为这些协议[25]提供了正式的隐私证明。在学习结束时,每一方只拥有与其自身特性相关的模型参数,因此在推断时,双方还需要协作生成输出。
2.3.3 Federated Transfer Learning(FTL)
联邦迁移学习适用于两个数据集不仅在样本上不同,而且在特征空间也不同的场景。考虑两个机构,一个是位于中国的银行,另一个是位于美国的电子商务公司。由于地域的限制,两个机构的用户群有一个小的交叉点。另一方面,由于业务的不同,双方的功能空间只有一小部分重叠。在这种情况下,可以应用迁移学习[50]技术为联邦下的整个样本和特征空间提供解决方案(图2c)。特别地,使用有限的公共样本集学习两个特征空间之间的公共表示,然后应用于获取仅具有单侧特征的样本预测。FTL是对现有联邦学习系统的一个重要扩展,因为它处理的问题超出了现有联邦学习算法的范围:![]()
安全定义:联邦迁移学习系统通常涉及两个方面。如下一节所示,它的协议类似于纵向联邦学习中的协议,在这种情况下,纵向联合学习的安全定义可以扩展到这里。
2.4 Architecture for a federated learning system
在本节中,我们将举例说明联邦学习系统的一般架构。请注意,横向和纵向联邦学习系统的架构在设计上是非常不同的,我们将分别介绍它们。
2.4.1 Horizontal Federated Learning
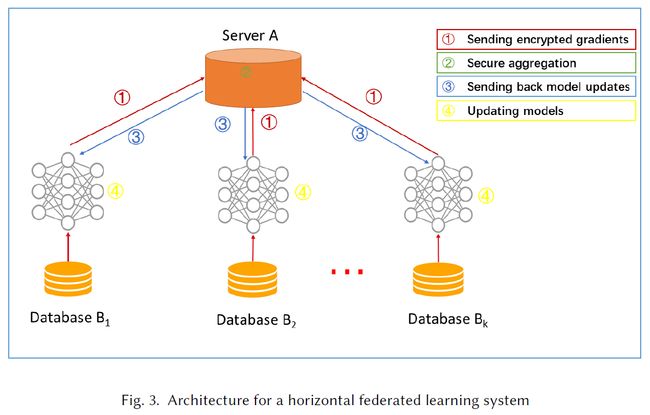
横向联邦学习系统的典型架构如图3所示。在该系统中,具有相同数据结构的k个参与者通过参数或云服务器协同学习机器学习模型。一个典型的假设是参与者是诚实的,而服务器是诚实但好奇的,因此不允许任何参与者向服务器泄漏信息[51]。这种系统的训练过程通常包括以下四个步骤:
- 第一步:参与者在本地计算训练梯度,使用加密[51]、差异隐私[58]或秘密共享[9]技术掩饰所选梯度,并将掩码后的结果发送到服务器;
- 第二步:服务器执行安全聚合,不了解任何参与者的信息;
- 第三步:服务器将汇总后的结果发送给参与者;
- 第四步:参与者用解密的梯度更新他们各自的模型。
通过上述步骤进行迭代,直到损失函数收敛,从而完成整个训练过程。该结构独立于特定的机器学习算法(逻辑回归、DNN等),所有参与者将共享最终的模型参数。
安全性分析:如果梯度聚合是使用SMC[9]或同态加密[51]完成的,则证明上述结构可以保护数据泄漏不受半诚实服务器的影响。但它可能会受到另一种安全模式的攻击,即恶意参与者在协作学习过程中训练生成对抗网络(GAN)[29]。
2.4.2 Vertical Federated Learning
假设A公司和B公司想要联合训练一个机器学习模型,并且他们的业务系统都有自己的数据。此外,B公司还拥有模型需要预测的标签数据。由于数据隐私和安全原因,A和B不能直接交换数据。为了确保训练过程中数据的保密性,引入了第三方合作者C。在此,我们假设合作者C是诚实的,不与A或B勾结,但A和B是诚实但彼此好奇的。一个可信的第三方C是一个合理的假设,因为C可以由政府等权威机构发挥作用,或由安全计算节点,如Intel Software Guard Extensions(SGX)[7]取代。联邦学习系统由两部分组成,如图4所示。
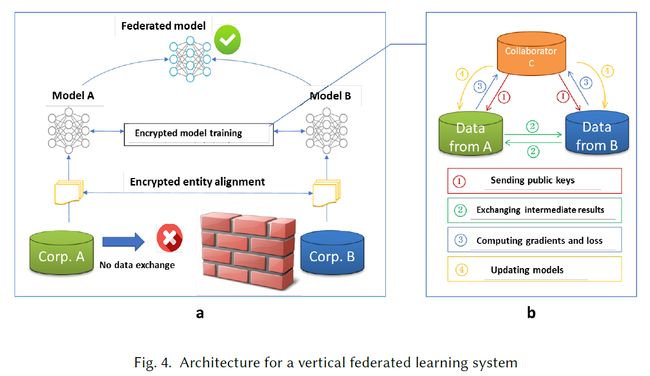
第一部分:加密实体对齐。由于两家公司的用户组不同,系统使用基于加密的用户ID对齐技术,如[38,56],来确认双方的共同用户,而A和B不会暴露各自的数据。在实体对齐过程中,系统不会公开彼此不重叠的用户。
第二部分:加密模型训练。在确定了公共实体之后,我们可以使用这些公共实体的数据来训练机器学习模型。训练过程可分为以下四个步骤(如图4所示):
- 第一步:第三方合作者C创建加密对,将公钥发送给A和B;
- 第二步:A、B对梯度和损失计算需要的中间结果进行加密与交换;
- 第三步:A、B分别计算加密梯度并添加额外的掩码,B也计算加密损失;A和B向C发送加密值;
- 第四步:C解密并将解密后的梯度和损失发送回A、B;A和B除去梯度上的掩码,相应地更新模型参数。



具体步骤见表1和表2。在实体对齐和模型训练过程中,A和B的数据在本地保存,训练中的数据交互不会导致数据隐私泄露。注:向C泄漏的潜在信息可能被视为侵犯隐私。为了进一步阻止C从A或B中学到信息,在这种情况下,A和B可以通过添加加密的随机掩码进一步向C隐藏其梯度。因此,双方在联邦学习的帮助下实现了共同模型的训练。因为在训练过程中,每一方收到的损失和梯度与他们在一个没有隐私限制的地方汇聚数据,然后联合建立一个模型收到的损失和梯度是完全相同的,也就是说,这个模型是无损的。模型的效率取决于加密数据的通信成本和计算成本。在每次迭代中,A和B之间发送的信息按重叠样本的数量进行缩放。因此,采用分布式并行计算技术可以进一步提高算法的效率。
安全性分析:表1所示的训练协议没有向C透露任何信息,因为所有C学习的都是掩码后的梯度,并且保证了掩码矩阵的随机性和保密性[16]。在上述协议中,A方在每一步都会学习其梯度,但这不足以让A根据等式8从B中学习任何信息,因为标量积协议的安全性是建立在无法用n个方程解n个以上未知数[16,65]的基础上的。这里我们假设样本数NA比nA大得多,其中nA是特征数。同样,B方也不能从A处获得任何信息,因此协议的安全性得到了证明。注意,我们假设双方都是半诚实的。如果一方是恶意的,并且通过伪造其输入来欺骗系统,例如,A方只提交一个只有一个非零特征的非零输入,它可以辨别该样本的该特征值uiB。但是,它仍然不能辨别xiB或ΘB,并且偏差会扭曲下一次迭代的结果,从而警告另一方终止学习过程。在训练过程结束时,每一方(A或B)都会不会察觉到另一方的数据结构,只获取与其自身特征相关的模型参数。推断时,双方需要协同计算预测结果,步骤如表2所示,这仍不会导致信息泄露。
2.4.3 Federated Transfer Learning
假设在上面的纵向联邦学习示例中,A方和B方只有一组非常小的重叠样本,并且我们希望学习A方中所有数据集的标签。到目前为止,上述部分描述的架构仅适用于重叠的数据集。为了将它的覆盖范围扩展到整个样本空间,我们引入了迁移学习。这并没有改变图4所示的总体架构,而是改变了A、B双方之间交换的中间结果的细节,具体来说,迁移学习通常涉及学习A、B双方特征之间的共同表示,并最小化利用源域方(在本例中为B)中的标签预测目标域方的标签时的出错率。因此,A方和B方的梯度计算不同于纵向联邦学习场景中的梯度计算。在推断时,仍然需要双方计算预测结果。
2.4.4 Incentives Mechanism
为了将不同组织之间的联邦学习充分商业化,需要开发一个公平的平台和激励机制[20]。模型建立后,模型的性能将在实际应用中体现出来,这种性能可以记录在永久数据记录机制(如区块链)中。提供更多数据的组织会更好,模型的有效性取决于数据提供者对系统的贡献。这些模型的有效性基于联邦机制分发给各方,并继续激励更多组织加入数据联邦。
上述架构的实现不仅考虑了多个组织之间协作建模的隐私保护和有效性,还考虑了如何奖励贡献更多数据的组织,以及如何通过共识机制实施激励。因此,联邦学习是一种“闭环”学习机制。
3 RELATED WORKS
联邦学习使多方能够协作构建机器学习模型,同时保持其训练数据的私有性。联邦学习作为一种新的技术,具有多个创新的思路,其中一些思路植根于现有的领域。下面我们从多个角度解释联邦学习和其他相关概念之间的关系。
3.1 Privacy-preserving machine learning
联邦学习可以看作是一种隐私保护的分散式协作机器学习,因此它与多方隐私保护机器学习密切相关。过去许多研究工作都致力于这一领域。例如,参考文献[17,67]提出了用于纵向划分数据的安全多方决策树算法。Vaidya和Clifton提出了安全关联挖掘规则[65]、安全k-means[66]、用于纵向划分数据的朴素贝叶斯分类器[64]。参考文献[31]提出了一种横向划分数据关联规则的算法。针对纵向划分数据[73]和横向划分数据[74]开发了安全支持向量机算法。参考文献[16]提出了多方线性回归和分类的安全协议。参考文献[68]提出了安全的多方梯度下降方法。以上工作均使用安全多方计算(SMC)[25,72]来保证隐私。
Nikolaenko等人[48]使用同态加密和姚式混乱电路实现了横向划分数据线性回归的隐私保护协议,参考文献[22,24]提出了纵向划分数据的线性回归方法。这些系统直接解决了线性回归问题。参考文献[47]探讨了随机梯度下降(SGD)问题,并提出了逻辑回归和神经网络的隐私保护协议。最近,[44]提出了一个三服务器模型的后续工作。Aono等人[4]提出了一种使用同态加密的安全逻辑回归协议。Shokri和Shmatikov[58]提出了基于更新参数交换的横向划分数据的神经网络训练。参考文献[51]使用了加法同态加密来保护梯度的隐私,并增强了系统的安全性。随着深度学习的不断进步,隐私保护的神经网络推断也受到了广泛的研究[10,11,14,28,40,52,54]。
3.2 Federated Learning vs Distributed Machine Learning
横向联邦学习乍一看有点类似于分布式机器学习。分布式机器学习包括训练数据的分布式存储、计算任务的分布式操作、模型结果的分布式分布等多个方面,参数服务器[30]是分布式机器学习中的一个典型元素。作为加速训练过程的工具,参数服务器将数据存储在分布式工作节点上,通过中央调度节点分配数据和计算资源,从而更有效地训练模型。对于横向联邦学习,工作节点表示数据所有者。它对本地数据具有完全的自主性,可以决定何时以及如何加入联邦学习。在参数服务器中,中心节点始终处于控制状态,因此联邦学习面临着一个更加复杂的学习环境。其次,联邦学习强调在模型训练过程中数据所有者的数据进行隐私保护。数据隐私保护的有效措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
与分布式机器学习设置一样,联邦学习也需要处理非IID数据。在[77]中显示,使用非IID本地数据,联邦学习的性能会大大降低。作为回应,作者提供了一种新的方法来解决类似于迁移学习的问题。
3.3 Federated Learning vs Edge Computing
联邦学习可以看作是边缘计算的操作系统,因为它为协调和安全提供了学习协议。在[69]中,作者考虑了使用基于梯度下降的方法训练的机器学习模型的一般类。他们从理论上分析了分布式梯度下降的收敛边界,在此基础上提出了一种控制算法,在给定的资源预算下,确定局部更新和全局参数聚合之间的最佳权衡,以最小化损失函数。
3.4 Federated Learning vs Federated Database Systems
联邦数据库系统[57]是集成多个数据库单元并对其进行整体管理的系统。为了实现与多个独立数据库的交互操作性,提出了联邦数据库的概念。联邦数据库系统通常使用分布式存储作为数据库单元,实际上,每个数据库单元中的数据都是异构的。因此,在数据类型和存储方面,它与联邦学习有许多相似之处。但是,联邦数据库系统在交互过程中不涉及任何隐私保护机制,所有数据库单元对管理系统都是完全可见的。此外,联邦数据库系统的重点是数据的基本操作,包括插入、删除、搜索和合并等,而联邦学习的目的是在保护数据隐私的前提下为每个数据所有者建立一个联合模型,以便数据中包含的各种值和规则对我们的服务更好。
4 APPLICATIONS
联邦学习作为一种创新的建模机制,可以在不影响数据隐私和安全的情况下,对来自多个方面的数据进行统一的建模,在销售、金融和许多其他行业中有着很好的应用前景,在这些行业中,由于知识产权、隐私保护和数据安全等因素,数据不能直接汇聚用来训练机器学习模型。
以智能零售为例。其目的是利用机器学习技术为客户提供个性化服务,主要包括产品推荐和销售服务。智能零售业务涉及的数据特征主要包括用户购买力、用户个人偏好和产品特征。在实际应用中,这三个数据特性可能分散在三个不同的部门或企业中。例如,一个用户的购买力可以从她的银行存款中推断出来,她的个人偏好可以从她的社交网络中分析出来,而产品的特征则由一个电子商店记录下来。在这种情况下,我们面临两个问题。首先,为了保护数据隐私和数据安全,银行、社交网站和电子购物网站之间的数据壁垒很难打破。因此,不能直接聚合数据来训练模型。第二,三方存储的数据通常是异构的,传统的机器学习模型不能直接处理异构数据。目前,传统的机器学习方法还没有有效地解决这些问题,阻碍了人工智能在更多领域的推广应用。
联邦学习和迁移学习是解决这些问题的关键。首先,利用联邦学习的特点,可以在不导出企业数据的情况下,为三方建立机器学习模型,既充分保护了数据隐私和数据安全,又为客户提供个性化、有针对性的服务,还顺便实现了互惠互利。同时,我们可以利用迁移学习来解决数据异质性问题,突破传统人工智能技术的局限性。因此,联邦学习为我们构建跨企业、跨数据、跨域的大数据和人工智能生态圈提供了良好的技术支持。
可以使用联邦学习框架进行多方数据库查询,而无需公开数据。例如,假设在金融应用程序中,我们有兴趣检查多方借款,这是银行业的一个主要风险因素。当某些用户恶意向一家银行借款以支付另一家银行的贷款时,就会发生这种情况。多方借款是对金融稳定的威胁,因为大量的此类非法行为可能导致整个金融体系崩溃。为了找到这样的用户而不在银行A和银行B之间公开用户列表,我们可以利用联邦学习框架。特别是,我们可以使用联邦学习的加密机制,对每一方的用户列表进行加密,然后在联邦中找到加密列表之间的交集。最终结果的解密提供了多方借款人的列表,而不会将其他“好”用户暴露给另一方。正如我们将在下面看到的,这个操作对应于纵向联邦学习框架。
智慧医疗是另一个领域,我们预计这将大大受益于联邦学习技术的兴起。疾病症状、基因序列、医学报告等医学数据是非常敏感和私密的,然而医学数据很难收集,它们存在于孤立的医疗中心和医院中。数据源的不足和标签的缺乏导致机器学习模型的性能不理想,成为当前智慧医疗的瓶颈。我们设想,如果所有的医疗机构都联合起来,共享他们的数据,形成一个大型的医疗数据集,那么在该大型医疗数据集上训练的机器学习模型的性能将显著提高。联邦学习与迁移学习相结合是实现这一愿景的主要途径。迁移学习可以应用于填补缺失的标签,从而扩大可用数据的规模,进一步提高训练模型的性能。因此,联邦迁移学习将在智慧医疗发展中发挥关键作用,它可能将人类健康保健提升到一个全新的水平。
5 FEDERATED LEARNING AND DATA ALLIANCE OF ENTERPRISES
联邦学习不仅是一种技术标准,也是一种商业模式。当人们意识到大数据的影响时,他们首先想到的是将数据聚合在一起,通过远程处理器计算模型,然后下载结果供进一步使用。云计算就是在这种需求下产生的。然而,随着数据隐私和数据安全的重要性越来越高,以及公司利润与其数据之间的关系越来越密切,云计算模型受到了挑战。然而,联邦学习的商业模式为大数据的应用提供了一个新的范例。当各个机构所占用的孤立数据不能产生理想的模型时,联邦学习机制使得机构和企业可以在不进行数据交换的情况下共享一个统一的模型。此外,在区块链技术的共识机制的帮助下,联邦学习可以制定公平的利润分配规则。无论数据拥有的规模如何,数据拥有者都会被激励加入数据联盟,并获得自己的利润。我们认为,建立数据联盟的业务模型和联邦学习的技术机制应该一起进行。我们还将为各个领域的联邦学习制定标准,以便尽快投入使用。
6 CONCLUSIONS AND PROSPECTS
近年来,数据的隔离和对数据隐私的强调正成为人工智能的下一个挑战,但是联邦学习给我们带来了新的希望。它可以在保护本地数据的同时,为多个企业建立一个统一的模型,使企业在以数据安全为前提的情况下共同取胜。本文概述了联邦学习的基本概念、体系结构和技术,并讨论了它在各种应用中的潜力。预计在不久的将来,联邦学习将打破行业之间的障碍,建立一个可以与安全共享数据和知识的社区,并根据每个参与者的贡献公平分配利益。人工智能的好处最终会带到我们生活的每个角落。
REFERENCES
[1] Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ’16). ACM, New York, NY, USA, 308–318. https://doi.org/10.1145/2976749.2978318
[2] Abbas Acar, Hidayet Aksu, A. Selcuk Uluagac, and Mauro Conti. 2018. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. ACM Comput. Surv. 51, 4, Article 79 (July 2018), 35 pages. https://doi.org/10.1145/3214303
[3] Rakesh Agrawal and Ramakrishnan Srikant. 2000. Privacy-preserving Data Mining. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data (SIGMOD ’00). ACM, New York, NY, USA, 439–450. https://doi.org/10.1145/342009.335438
[4] Yoshinori Aono, Takuya Hayashi, Le Trieu Phong, and Lihua Wang. 2016. Scalable and Secure Logistic Regression via Homomorphic Encryption. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy (CODASPY ’16). ACM, New York, NY, USA, 142–144. https://doi.org/10.1145/2857705.2857731
[5] Toshinori Araki, Jun Furukawa, Yehuda Lindell, Ariel Nof, and Kazuma Ohara. 2016. High-Throughput Semi-Honest Secure Three-Party Computation with an Honest Majority. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ’16). ACM, New York, NY, USA, 805–817. https://doi.org/10.1145/2976749. 2978331
[6] Eugene Bagdasaryan, Andreas Veit, Yiqing Hua, Deborah Estrin, and Vitaly Shmatikov. 2018. How To Backdoor Federated Learning. arXiv:cs.CR/1807.00459
[7] Raad Bahmani, Manuel Barbosa, Ferdinand Brasser, Bernardo Portela, Ahmad-Reza Sadeghi, Guillaume Scerri, and Bogdan Warinschi. 2017. Secure Multiparty Computation from SGX. In Financial Cryptography and Data Security - 21st International Conference, FC 2017, Sliema, Malta, April 3-7, 2017, Revised Selected Papers. 477–497. https://doi.org/10.1007/978-3-319-70972-7_27
[8] Dan Bogdanov, Sven Laur, and Jan Willemson. 2008. Sharemind: A Framework for Fast Privacy-Preserving Computations. In Proceedings of the 13th European Symposium on Research in Computer Security: Computer Security (ESORICS ’08). Springer-Verlag, Berlin, Heidelberg, 192–206. https://doi.org/10.1007/978-3-540-88313-5_13
[9] Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS ’17). ACM, New York, NY, USA, 1175–1191. https://doi.org/10.1145/3133956.3133982
[10] Florian Bourse, Michele Minelli, Matthias Minihold, and Pascal Paillier. 2017. Fast Homomorphic Evaluation of Deep Discretized Neural Networks. IACR Cryptology ePrint Archive 2017 (2017), 1114.
[11] Hervé Chabanne, Amaury de Wargny, Jonathan Milgram, Constance Morel, and Emmanuel Prouff. 2017. Privacy-Preserving Classification on Deep Neural Network. IACR Cryptology ePrint Archive 2017 (2017), 35.
[12] Kamalika Chaudhuri and Claire Monteleoni. 2009. Privacy-preserving logistic regression. In Advances in Neural Information Processing Systems 21, D. Koller, D. Schuurmans, Y. Bengio, and L. Bottou (Eds.). Curran Associates, Inc., 289–296. http://papers.nips.cc/paper/3486-privacy-preserving-logistic-regression.pdf
[13] Fei Chen, Zhenhua Dong, Zhenguo Li, and Xiuqiang He. 2018. Federated Meta-Learning for Recommendation. CoRR abs/1802.07876 (2018). arXiv:1802.07876 http://arxiv.org/abs/1802.07876
[14] Nathan Dowlin, Ran Gilad-Bachrach, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. 2016. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. Technical Report. https://www.microsoft.com/en-us/research/publication/cryptonets-applying-neural-networks-to-encrypted-data-with-high-throughput-and-accuracy/
[15] W. Du and M. Atallah. 2001. Privacy-Preserving Cooperative Statistical Analysis. In Proceedings of the 17th Annual Computer Security Applications Conference (ACSAC ’01). IEEE Computer Society, Washington, DC, USA, 102–. http://dl.acm.org/citation.cfm?id=872016.872181
[16] Wenliang Du, Yunghsiang Sam Han, and Shigang Chen. 2004. Privacy-Preserving Multivariate Statistical Analysis: Linear Regression and Classification. In SDM.
[17] Wenliang Du and Zhijun Zhan. 2002. Building Decision Tree Classifier on Private Data. In Proceedings of the IEEE International Conference on Privacy, Security and Data Mining - Volume 14 (CRPIT ’14). Australian Computer Society, Inc., Darlinghurst, Australia, Australia, 1–8. http://dl.acm.org/citation.cfm?id=850782.850784
[18] Cynthia Dwork. 2008. Differential Privacy: A Survey of Results. In Proceedings of the 5th International Conference on Theory and Applications of Models of Computation (TAMC’08). Springer-Verlag, Berlin, Heidelberg, 1–19. http://dl.acm.org/citation.cfm?id=1791834.1791836
[19] EU. 2016. REGULATION (EU) 2016/679 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). Available at: https://eur-lex. europa. eu/legal-content/EN/TXT (2016).
[20] Boi Faltings, Goran Radanovic, and Ronald Brachman. 2017. Game Theory for Data Science: Eliciting Truthful Information. Morgan & Claypool Publishers.
[21] Jun Furukawa, Yehuda Lindell, Ariel Nof, and Or Weinstein. 2016. High-Throughput Secure Three-Party Computation for Malicious Adversaries and an Honest Majority. Cryptology ePrint Archive, Report 2016/944. https://eprint.iacr.org/2016/944.
[22] Adrià Gascón, Phillipp Schoppmann, Borja Balle, Mariana Raykova, Jack Doerner, Samee Zahur, and David Evans. 2016. Secure Linear Regression on Vertically Partitioned Datasets. IACR Cryptology ePrint Archive 2016 (2016), 892.
[23] Robin C. Geyer, Tassilo Klein, and Moin Nabi. 2017. Differentially Private Federated Learning: A Client Level Perspective. CoRR abs/1712.07557 (2017). arXiv:1712.07557 http://arxiv.org/abs/1712.07557
[24] Irene Giacomelli, Somesh Jha, Marc Joye, C. David Page, and Kyonghwan Yoon. 2017. Privacy-Preserving Ridge Regression with only Linearly-Homomorphic Encryption. Cryptology ePrint Archive, Report 2017/979. https://eprint.iacr.org/2017/979.
[25] O. Goldreich, S. Micali, and A. Wigderson. 1987. How to Play ANY Mental Game. In Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing (STOC ’87). ACM, New York, NY, USA, 218–229. https://doi.org/10.1145/28395.28420
[26] Rob Hall, Stephen E. Fienberg, and Yuval Nardi. 2011. Secure multiple linear regression based on homomorphic encryption. Journal of Official Statistics 27, 4 (2011), 669–691.
[27] Stephen Hardy, Wilko Henecka, Hamish Ivey-Law, Richard Nock, Giorgio Patrini, Guillaume Smith, and Brian Thorne. 2017. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. CoRR abs/1711.10677 (2017).
[28] Ehsan Hesamifard, Hassan Takabi, and Mehdi Ghasemi. 2017. CryptoDL: Deep Neural Networks over Encrypted Data. CoRR abs/1711.05189 (2017). arXiv:1711.05189 http://arxiv.org/abs/1711.05189
[29] Briland Hitaj, Giuseppe Ateniese, and Fernando Pérez-Cruz. 2017. Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning. CoRR abs/1702.07464 (2017).
[30] Qirong Ho, James Cipar, Henggang Cui, Jin Kyu Kim, Seunghak Lee, Phillip B. Gibbons, Garth A. Gibson, Gregory R. Ganger, and Eric P. Xing. 2013. More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server. In Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1 (NIPS’13). Curran Associates Inc., USA, 1223–1231. http://dl.acm.org/citation.cfm?id=2999611.2999748
[31] Murat Kantarcioglu and Chris Clifton. 2004. Privacy-Preserving Distributed Mining ofAssociation Rules on Horizontally Partitioned Data. IEEE Trans. on Knowl. and Data Eng. 16, 9 (Sept. 2004), 1026–1037. https://doi.org/10.1109/TKDE.2004.45
[32] Alan F. Karr, X. Sheldon Lin, Ashish P. Sanil, and Jerome P. Reiter. 2004. Privacy-Preserving Analysis of Vertically Partitioned Data Using Secure Matrix Products.
[33] Niki Kilbertus, Adria Gascon, Matt Kusner, Michael Veale, Krishna Gummadi, and Adrian Weller. 2018. Blind Justice: Fairness with Encrypted Sensitive Attributes. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research), Jennifer Dy and Andreas Krause (Eds.), Vol. 80. PMLR, Stockholmsmässan, Stockholm Sweden, 2630–2639. http://proceedings.mlr.press/v80/kilbertus18a.html
[34] Hyesung Kim, Jihong Park, Mehdi Bennis, and Seong-Lyun Kim. 2018. On-Device Federated Learning via Blockchain and its Latency Analysis. arXiv:cs.IT/1808.03949
[35] Miran Kim, Yongsoo Song, Shuang Wang, Yuhou Xia, and Xiaoqian Jiang. 2018. Secure Logistic Regression Based on Homomorphic Encryption: Design and Evaluation. JMIR Med Inform 6, 2 (17 Apr 2018), e19. https://doi.org/10.2196/medinform.8805
[36] Jakub Konecný, H. Brendan McMahan, Daniel Ramage, and Peter Richtárik. 2016. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. CoRR abs/1610.02527 (2016). arXiv:1610.02527 http://arxiv.org/abs/1610.02527
[37] Jakub Konecný, H. Brendan McMahan, Felix X. Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. 2016. Federated Learning: Strategies for Improving Communication Efficiency. CoRR abs/1610.05492 (2016). arXiv:1610.05492 http://arxiv.org/abs/1610.05492
[38] Gang Liang and Sudarshan S Chawathe. 2004. Privacy-preserving inter-database operations. In International Conference on Intelligence and Security Informatics. Springer, 66–82.
[39] Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William J. Dally. 2017. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. CoRR abs/1712.01887 (2017). arXiv:1712.01887 http://arxiv.org/abs/1712.01887
[40] Jian Liu, Mika Juuti, Yao Lu, and N. Asokan. 2017. Oblivious Neural Network Predictions via MiniONN Transformations. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS ’17). ACM, New York, NY, USA, 619–631. https://doi.org/10.1145/3133956.3134056
[41] H. Brendan McMahan, Eider Moore, Daniel Ramage, and Blaise Agüera y Arcas. 2016. Federated Learning of Deep Networks using Model Averaging. CoRR abs/1602.05629 (2016). arXiv:1602.05629 http://arxiv.org/abs/1602.05629
[42] H. Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang. 2017. Learning Differentially Private Language Models Without Losing Accuracy. CoRR abs/1710.06963 (2017).
[43] Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. 2018. Inference Attacks Against Collaborative Learning. CoRR abs/1805.04049 (2018). arXiv:1805.04049 http://arxiv.org/abs/1805.04049
[44] Payman Mohassel and Peter Rindal. 2018. ABY3: A Mixed Protocol Framework for Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18). ACM, New York, NY, USA, 35–52. https://doi.org/10.1145/3243734.3243760
[45] Payman Mohassel, Mike Rosulek, and Ye Zhang. 2015. Fast and Secure Three-party Computation: The Garbled Circuit Approach. In Proceedings of the 22Nd ACM SIGSAC Conference on Computer and Communications Security (CCS ’15). ACM, New York, NY, USA, 591–602. https://doi.org/10.1145/2810103.2813705
[46] Payman Mohassel and Yupeng Zhang. 2017. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In IEEE Symposium on Security and Privacy. IEEE Computer Society, 19–38.
[47] Payman Mohassel and Yupeng Zhang. 2017. SecureML: A System for Scalable Privacy-Preserving Machine Learning. IACR Cryptology ePrint Archive 2017 (2017), 396.
[48] Valeria Nikolaenko, Udi Weinsberg, Stratis Ioannidis, Marc Joye, Dan Boneh, and Nina Taft. 2013. Privacy-Preserving Ridge Regression on Hundreds of Millions of Records. In Proceedings of the 2013 IEEE Symposium on Security and Privacy (SP ’13). IEEE Computer Society, Washington, DC, USA, 334–348. https://doi.org/10.1109/SP.2013.30
[49] Richard Nock, Stephen Hardy, Wilko Henecka, Hamish Ivey-Law, Giorgio Patrini, Guillaume Smith, and Brian Thorne. 2018. Entity Resolution and Federated Learning get a Federated Resolution. CoRR abs/1803.04035 (2018). arXiv:1803.04035 http://arxiv.org/abs/1803.04035
[50] Sinno Jialin Pan and Qiang Yang. 2010. A Survey on Transfer Learning. IEEE Trans. on Knowl. and Data Eng. 22, 10 (Oct. 2010), 1345–1359. https://doi.org/10.1109/TKDE.2009.191
[51] Le Trieu Phong, Yoshinori Aono, Takuya Hayashi, Lihua Wang, and Shiho Moriai. 2018. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Information Forensics and Security 13, 5 (2018), 1333–1345.
[52] M. Sadegh Riazi, Christian Weinert, Oleksandr Tkachenko, Ebrahim M. Songhori, Thomas Schneider, and Farinaz Koushanfar. 2018. Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications. CoRR abs/1801.03239 (2018).
[53] R L Rivest, L Adleman, and M L Dertouzos. 1978. On Data Banks and Privacy Homomorphisms. Foundations of Secure Computation, Academia Press (1978), 169–179.
[54] Bita Darvish Rouhani, M. Sadegh Riazi, and Farinaz Koushanfar. 2017. DeepSecure: Scalable Provably-Secure Deep Learning. CoRR abs/1705.08963 (2017). arXiv:1705.08963 http://arxiv.org/abs/1705.08963
[55] Ashish P. Sanil, Alan F. Karr, Xiaodong Lin, and Jerome P. Reiter. 2004. Privacy Preserving Regression Modelling via Distributed Computation. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’04). ACM, New York, NY, USA, 677–682. https://doi.org/10.1145/1014052.1014139
[56] Monica Scannapieco, Ilya Figotin, Elisa Bertino, and Ahmed K. Elmagarmid. 2007. Privacy Preserving Schema and Data Matching. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data (SIGMOD ’07). ACM, New York, NY, USA, 653–664. https://doi.org/10.1145/1247480.1247553
[57] Amit P. Sheth and James A. Larson. 1990. Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases. ACM Comput. Surv. 22, 3 (Sept. 1990), 183–236. https://doi.org/10.1145/96602.96604
[58] Reza Shokri and Vitaly Shmatikov. 2015. Privacy-Preserving Deep Learning. In Proceedings of the 22Nd ACM SIGSAC Conference on Computer and Communications Security (CCS ’15). ACM, New York, NY, USA, 1310–1321. https://doi.org/10.1145/2810103.2813687
[59] David Silver, Aja Huang, Christopher J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. 2016. Mastering the game of Go with deep neural networks and tree search. Nature 529 (2016), 484–503. http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
[60] Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet S Talwalkar. 2017. Federated Multi-Task Learning. In Advances in Neural Information Processing Systems 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus,
S. Vishwanathan, and R. Garnett (Eds.). Curran Associates, Inc., 4424–4434. http://papers.nips.cc/paper/7029-federated-multi-task-learning.pdf
[61] Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. 2013. Stochastic gradient descent with differentially private updates. 2013 IEEE Global Conference on Signal and Information Processing (2013), 245–248.
[62] Lili Su and Jiaming Xu. 2018. Securing Distributed Machine Learning in High Dimensions. CoRR abs/1804.10140 (2018). arXiv:1804.10140 http://arxiv.org/abs/1804.10140
[63] Latanya Sweeney. 2002. K-anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 10, 5 (Oct. 2002), 557–570. https://doi.org/10.1142/S0218488502001648
[64] Jaideep Vaidya and Chris Clifton. [n. d.]. Privacy Preserving Naive Bayes Classifier for Vertically Partitioned Data. In Proceedings of the fourth SIAM Conference on Data Mining, 2004. 330–334.
[65] Jaideep Vaidya and Chris Clifton. 2002. Privacy Preserving Association Rule Mining in Vertically Partitioned Data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’02). ACM, New York, NY, USA, 639–644. https://doi.org/10.1145/775047.775142
[66] Jaideep Vaidya and Chris Clifton. 2003. Privacy-preserving K-means Clustering over Vertically Partitioned Data. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’03). ACM, New York, NY, USA, 206–215. https://doi.org/10.1145/956750.956776
[67] Jaideep Vaidya and Chris Clifton. 2005. Privacy-Preserving Decision Trees over Vertically Partitioned Data. In Data and Applications Security XIX, Sushil Jajodia and Duminda Wijesekera (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 139–152.
[68] Li Wan, Wee Keong Ng, Shuguo Han, and Vincent C. S. Lee. 2007. Privacy-preservation for Gradient Descent Methods. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’07). ACM, New York, NY, USA, 775–783. https://doi.org/10.1145/1281192.1281275
[69] Shiqiang Wang, Tiffany Tuor, Theodoros Salonidis, Kin K. Leung, Christian Makaya, Ting He, and Kevin Chan. 2018. When Edge Meets Learning: Adaptive Control for Resource-Constrained Distributed Machine Learning. CoRR abs/1804.05271 (2018). arXiv:1804.05271 http://arxiv.org/abs/1804.05271
[70] Wikipedia. 2018. https://en.wikipedia.org/wiki/Facebook-Cambridge_Analytica_data_scandal.
[71] Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2018. Federated Learning. Communications of The CCF 14, 11 (2018), 49–55.
[72] Andrew C. Yao. 1982. Protocols for Secure Computations. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (SFCS ’82). IEEE Computer Society, Washington, DC, USA, 160–164. http://dl.acm.org/citation.cfm?id=1382436.1382751
[73] Hwanjo Yu, Xiaoqian Jiang, and Jaideep Vaidya. 2006. Privacy-preserving SVM Using Nonlinear Kernels on Horizontally Partitioned Data. In Proceedings of the 2006 ACM Symposium on Applied Computing (SAC ’06). ACM, New York, NY, USA, 603–610. https://doi.org/10.1145/1141277.1141415
[74] Hwanjo Yu, Jaideep Vaidya, and Xiaoqian Jiang. 2006. Privacy-Preserving SVM Classification on Vertically Partitioned Data. In Proceedings of the 10th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining (PAKDD’06). Springer-Verlag, Berlin, Heidelberg, 647–656. https://doi.org/10.1007/11731139_74
[75] Jiawei Yuan and Shucheng Yu. 2014. Privacy Preserving Back-Propagation Neural Network Learning Made Practical with Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 25, 1 (Jan. 2014), 212–221. https://doi.org/10.1109/TPDS.2013.18
[76] Qingchen Zhang, Laurence T. Yang, and Zhikui Chen. 2016. Privacy Preserving Deep Computation Model on Cloud for Big Data Feature Learning. IEEE Trans. Comput. 65, 5 (May 2016), 1351–1362. https://doi.org/10.1109/TC.2015.2470255
[77] Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. 2018. Federated Learning with Non-IID Data. arXiv:cs.LG/1806.00582