Prometheus 概述与安装
之前我在2016年写过一个专题"zabbix2.x从入门到精通",而且之后的工作也一直使用zabbix来做监控系统,直到2018年年初我开始学习kubernetes而接触了prometheus,当初学习prometheus后的感受就是这东西除了能k8s与公有云集成可以快速发现弹性节点与内部资源的监控还能能干啥。恰恰现在这两个东西火的不行。但是zabbix能不能实现上面的功能,zabbix也肯定能行的,我记得四年前的文章就有讲过zabbix自定义监控的文章,但是prometheus已经提供了这些,你不用再去重复造轮子,这和两个开源软件的定位可能不同,zabbix更适用于传统监控,但是时代也不断在进步,zabbix也在发展,也许有一天zabbix能顺势而起,好了废话不多说,我们开始进入prometheus的世界吧。
Prometheus 简介
我们在官网上面可以看到官网给出的详细介绍: Prometheus 是由 SoundCloud 开源监控告警解决方案。受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来)。从 2012 年开始编写代码,许多公司和组织都使用了prometheus,该项目拥有非常活跃的开发人员和用户社区,2016 年 Prometheus 成为继 k8s 后,第二名 CNCF(Cloud Native Computing Foundation) 成员。作为新一代开源解决方案,很多理念与 Google SRE 运维之道不谋而合。
Prometheus 特性
- 多维数据模型(时序列数据由metric名和一组key/value组成)
- 在多维度上灵活的查询语言(PromQl)
- 不依赖分布式存储,单主节点工作.
- 通过基于HTTP的pull方式采集时序数据
- 可以通过push gateway进行时序列数据推送(pushing)
- 可以通过服务发现或者静态配置去获取要采集的目标服务器
- 多种可视化图表及仪表盘支持
Prometheus 架构
Prometheus 的整体架构图(图片来源):
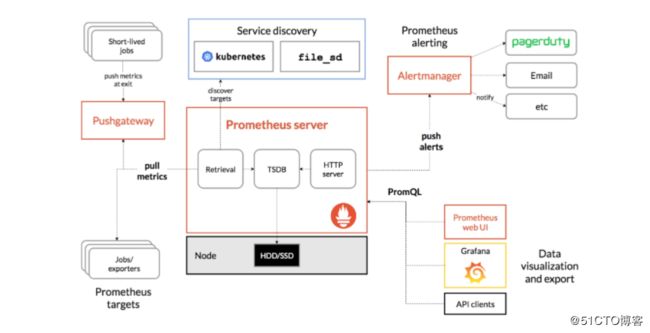
从上图可以看出,Prometheus 生态系统包含了几个关键的组件:Prometheus server、Pushgateway、Alertmanager、Web UI 等,但是大多数组件都不是必需的,其中最核心的组件当然是 Prometheus server,它负责收集和存储指标数据,支持表达式查询,和告警的生成。Prometheus 数据采集方式也非常灵活。要采集目标的监控数据,首先需要在目标处安装数据采集组件,这被称之为 Exporter,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus 查询,Prometheus 通过 Pull 的方式来采集数据,这和传统的 Push 模式不同。不过 Prometheus 也提供了一种方式来支持 Push 模式,你可以将你的数据推送到 Push Gateway,Prometheus 通过 Pull 的方式从 Push Gateway 获取数据。目前的 Exporter 已经可以采集绝大多数的第三方数据,比如 Docker、HAProxy、StatsD、JMX 等等,官网有一份 Exporter 的列表。接下来我们就来安装 Prometheus server。
Prometheus 场景
Prometheus 适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus 不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
Prometheus 安装
安装golang
$ yum install golang安装Prometheus
$ cd /usr/src
$ wget https://github.com/prometheus/prometheus/releases/download/v2.18.1/prometheus-2.18.1.linux-amd64.tar.gz
$ tar xzvf prometheus-2.18.1.linux-amd64.tar.gz
$ mv prometheus-2.18.1.linux-amd64.tar.gz /usr/local
$ cd /usr/local && mv prometheus-2.3.2.linux-amd64 prometheus检查版本
$ ./prometheus --version
prometheus, version 1.6.3 (branch: master, revision: c580b60c67f2c5f6b638c3322161bcdf6d68d7fc)
build user: root@a6410e65f5c7
build date: 20170522-09:15:06
go version: go1.8.1创建用户
$ groupadd prometheus
$ useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus创建Systemd服务
$ vim /etc/systemd/system/prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheus
Restart=on-failure
[Install]
WantedBy=multi-user.target
$ systemctl start prometheus访问自带Web http://ip:9090
Prometheus 配置
在上面的启动脚本我们可以看到Prometheus 有一个配置文件,通过参数 --config.file 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 prometheus.yml 看下里面的内容:
$ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090'] Prometheus 默认的配置文件分为四大块:
- global 块:Prometheus 的全局配置,比如
scrape_interval表示 Prometheus 多久抓取一次数据,evaluation_interval表示多久检测一次告警规则; - alerting 块:关于 Alertmanager 的配置,这个我们后面再看;
- rule_files 块:告警规则,这个我们后面再看;
- scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为
prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
使用 Exporter 收集指标
如果我们要在我们的生产环境真正使用 Prometheus,往往需要关注各种各样的指标,譬如服务器的 CPU负载、内存占用量、IO开销、入网和出网流量等等。正如上面所说,Prometheus 是使用 Pull 的方式来获取指标数据的,要让 Prometheus 从目标处获得数据,首先必须在目标上安装指标收集的程序,并暴露出 HTTP 接口供 Prometheus 查询,这个指标收集程序被称为 Exporter,不同的指标需要不同的 Exporter 来收集,目前已经有大量的 Exporter 可供使用,几乎囊括了我们常用的各种系统和软件,官网列出了一份 常用 Exporter 的清单,各个 Exporter 都遵循一份端口约定,避免端口冲突,即从 9100 开始依次递增,这里是 完整的 Exporter 端口列表。另外值得注意的是,有些软件和系统无需安装 Exporter,这是因为他们本身就提供了暴露 Prometheus 格式的指标数据的功能,比如 Kubernetes、Grafana、Etcd、Ceph 等。下面我们演示一个对服务器指标进行监控的案例,这需要安装 node_exporter,这个 exporter 用于收集 UNIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.0.0/node_exporter-1.0.0.linux-amd64.tar.gz
$ tar -zxvf node_exporter-1.0.0.linux-amd64.tar.gz
$ cd node_exporter-1.0.0.linux-amd64 && mv node_exporter /usr/local/prometheus/node_exporter
$ sudo vim /etc/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.targetnode_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
$ curl http://localhost:9100/metrics如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'server'
static_configs:
- targets: ['127.0.0.1:9100']修改配置后,需要重启 Prometheus 服务
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器: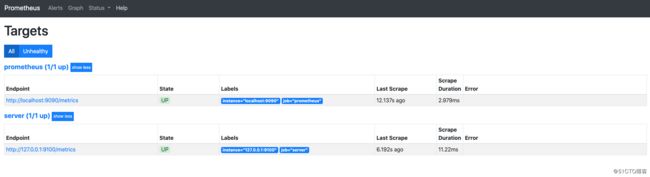
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:
