2019独角兽企业重金招聘Python工程师标准>>> 
Kylin集群部署和cube使用
- 安装集群环境
| 节点 |
Kylin节点模式 |
Ip |
内存 |
磁盘 |
| Node1 |
All |
192.167.71.11 |
2G |
80G |
| Node2 |
query |
192.168.71.12 |
1.5G |
80G |
| Node3 |
query |
192.168.71.13 |
1.5G |
80G |
Kylin工作原理如下:
- 集群时间同步
Ntp服务自行设置
- 安装kylin之前所需要的环境
Hadoop-2.7.4
Hbase-1.4.0
Spark-2.2.0 可选
Zookeepr-3.3.6
Hive-2.1.1 使用mysql存放元数据,远程模式安装
Kylin-2.3.1
Hadoop环境,HBASE,zookeeper还有hive自行安装,集群环境变量如下:
##################HADOOP
export HADOOP_HOME=/home/zhouwang/hadoop-2.7.4
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djave.library.path=$HADOOP_HOME/lib"
###############ZOOKEEPER
export ZOOKEEPER_HOME=/home/zhouwang/zookeeper-3.3.6
export PATH=:$PATH:$ZOOKEEPER_HOME/bin
################HIVE
export HIVE_HOME=/home/zhouwang/apache-hive-2.1.1-bin
export HIVE_CONF_HOME=$HIVE_HOME/conf
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=:$PATH:$HIVE_HOME/bin:$HCAT_HOME/bin
#######################SCALA
export SCALA_HOME=/home/zhouwang/scala-2.10.5
export PATH=:$PATH:$SCALA_HOME/bin
################################SPARK
export SPARK_HOME=/home/zhouwang/spark-2.2.0-bin-hadoop2.7
export PATH=:$PATH:$SPARK_HOME/bin
#################HBASE
export HBASE_HOME=/home/zhouwang/hbase-1.4.0
export PATH=$PATH:/home/zhouwang/hbase-1.4.0/bin
##############KYLIN
export KYLIN_HOME=/home/zhouwang/apache-kylin-2.3.1-bin
export KYLIN_CONF_HOME=/home/zhouwang/apache-kylin-2.3.1-bin/conf
export PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/bin
export tomcat_root=$KYLIN_HOME/tomcat
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.1.1.jar
- 安装kylin
(1)第一步修改bin/kylin.sh,这么做的目的是为了加入$hive_dependency环境,解决后续的两个问题,都是没有hive依赖的原因。
第一个问题是kylinweb界面load hive表会失败,第二个问题是cube build的第二步会报org/apache/Hadoop/hive/conf/hiveConf的错误。
更改如下:
export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
(2)第二步就是hadoop支持压缩的问题,本例的hadoop不支持snappy压缩,会导致后续cube build报错。如果要hadoop支持的话,另行找解决方案
解决这个问题对应的要修改kylin的三个配置文件
Kylin_job_conf.xml
#不使用压缩
mapreduce.map.output.compress设置为false
mapreduce.output.fileoutputformat.compress 设置为false
kylin_hive_conf.xml
#不使用压缩
hive.exec.compress.output 设置为false
kylin.properties
修改见下文
(3)第三步修改kylin.properties
主节点配置
kylin.metadata.url=kylin_metadata@hbase ###hbase上存储kylin元数据
kylin.env.hdfs-working-dir=/kylin ###hdfs上kylin工作目录
kylin.env=DEV
kylin.env.zookeeper-base-path=/kylin
kylin.server.mode=all ###kylin主节点模式,从节点的模式为query,只有这一点不一样
kylin.rest.servers=node1:7070,node2:7070,node3:7070 ###集群的信息同步
kylin.web.timezone=GMT+8 ####改为中国时间
kylin.job.retry=2
kylin.job.mapreduce.default.reduce.input.mb=500
kylin.job.concurrent.max.limit=10
kylin.job.yarn.app.rest.check.interval.seconds=10
kylin.job.hive.database.for.intermediatetable=kylin_flat_db ###build cube 产生的Hive中间表存放的数据库
kylin.hbase.default.compression.codec=none ###不采用压缩
kylin.job.cubing.inmem.sampling.percent=100
kylin.hbase.regin.cut=5
kylin.hbase.hfile.size.gb=2
###定义kylin用于MR jobs的job.jar包和hbase的协处理jar包,用于提升性能(添加项)
kylin.job.jar=/home/zhouwang/apache-kylin-2.3.1-bin/lib/kylin-job-2.3.1.jar
kylin.coprocessor.local.jar=/home/zhouwang/apache-kylin-2.3.1-bin/lib/kylin-coprocessor-2.3.1.jar
配置完之后将kylin安装包传送搭配从节点
Scp -r apache-kylin-2.3.1-bin zhouwang@node2:~/apache-kylin-2.3.11-bin
Scp -r apache-kylin-2.3.1-bin zhouwang@node3:~/apache-kylin-2.3.11-bin
主从节点的配置的唯一不同就是kylin.server.mode,一个集群的所有节点必须只能有一个节点处于job或者all状态,其他节点全部为query状态。
- 启动kylin
第一步,启动zookeeper,所有几点运行zkServer.sh start
第二步,启动hadoop,主节点运行start-all.sh
第三步,启动JobHistoryserver服务,主节点启动mr-jobhistoryserver-deamon.sh start historyserver
第四步,启动hivemetastore服务,hive –service metastore &
第五步启动hbase集群,主节点启动start-hbase.sh
第六步,检查基础依赖的服务,hadoop,hbase,hive,环境变量,工作目录等,hive依赖检查find-hive-dependency.sh ,hbase依赖检查find-hbase-dependency.sh,所有的依赖检查可吃用chek-env.sh。
第六步,启动kylin服务,所有节点运行bin/kylin.sh start
- 登录
http://node1:7070/kylin
默认的秘钥:admin/KYLIN
- 样例数据测试
启动kylin之后运行sample.sh脚本
导入sample数据,模型,cube成功之后系统会提示重启kylin或者重新加载元数据让数据生效。我们选择重新加载。
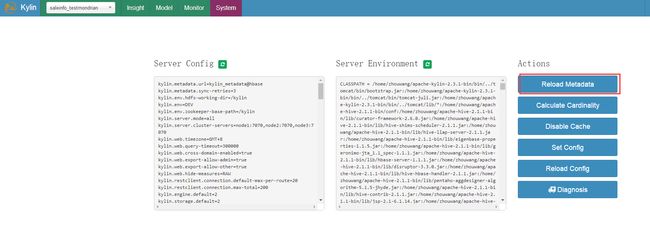
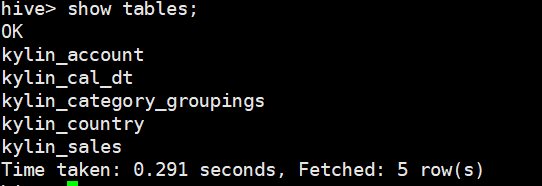
重新加载过后查看hive
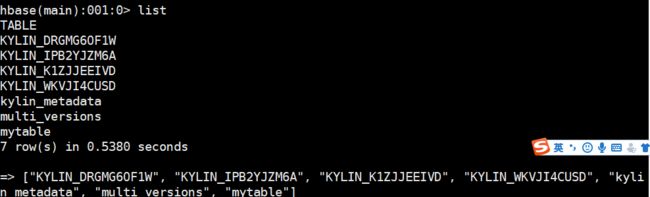
查看hbase中的数据多了一个kylin_metadata元数据表
默认的有一个cube需要build
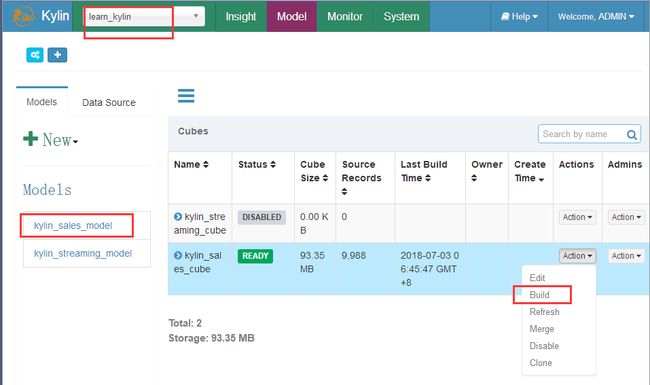
Build成功之后
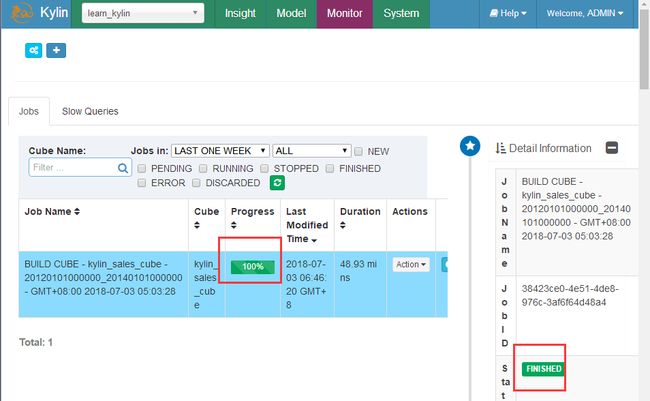
Build成功之后model里面会出现storage信息,之前是没有的,可以到hbase里面去找对应的表,同时cube状态变为ready,表示可查询。
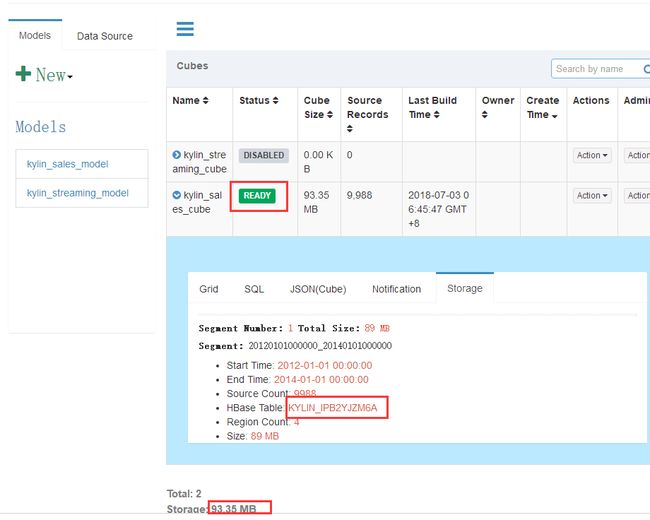
8.查询性能对比(为本地自己的数据建的cube,不是sample数据)
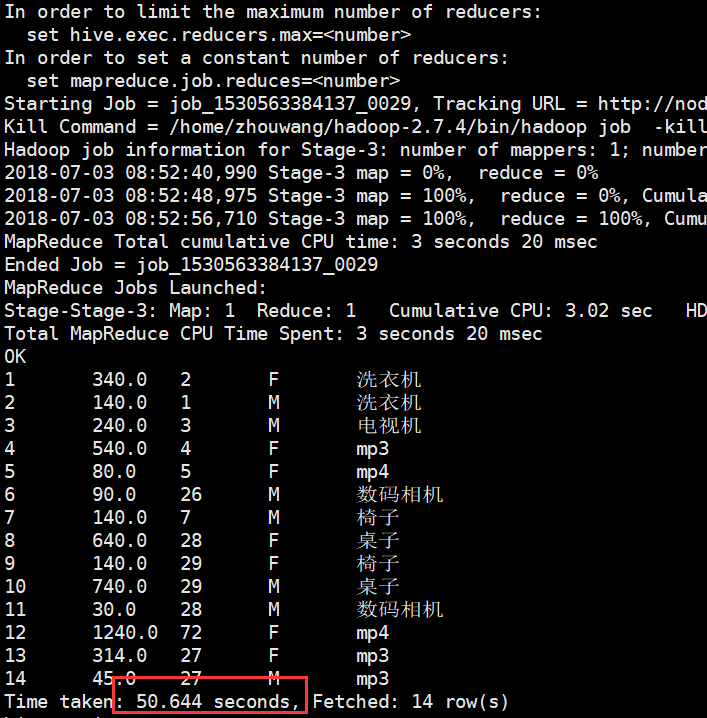
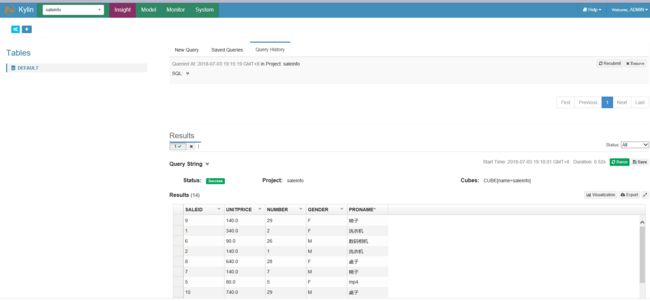
可以看出明细kylin要比hive快上很多倍,kylin集群部署结束。
- Cube使用
Cube使用分为五部:
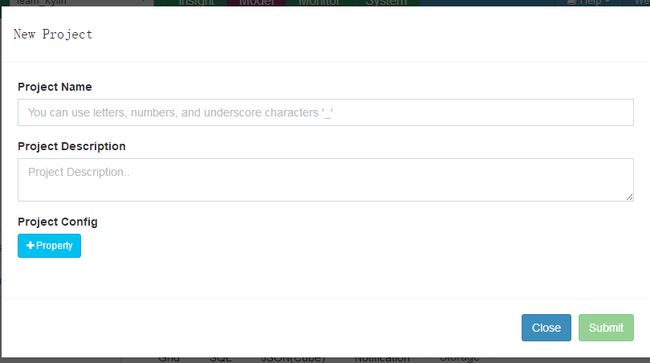
第一步:新建工程![]()
点击加号跳出下面的界面,输入工程名,提交即可。
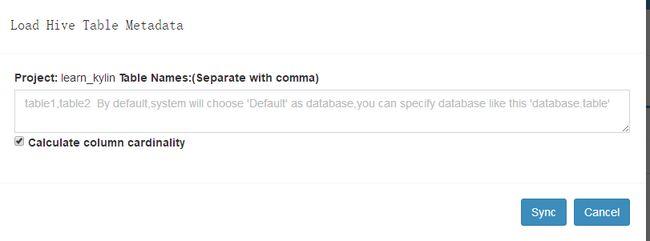
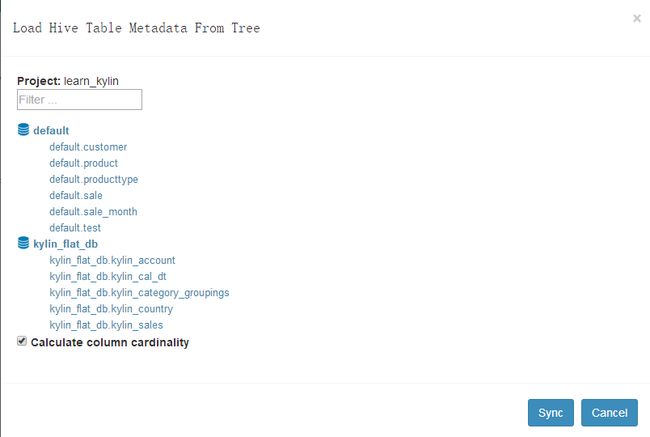
第二步,添加数据源![]()
三个按钮功能各不相同,自行了解,点击第一个输入表名同步,点击第二个加载出hive的元数据,点击选择表,同步。
第三步,新建model,自行设置各个步骤
第四部,新建cube,自行设置cube的每一步信息
第五步,cube的build
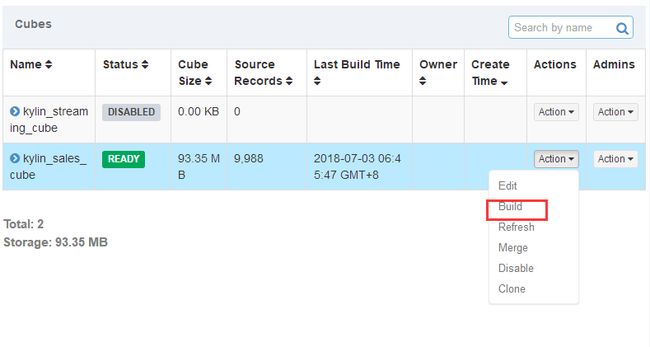
选择build,提交cube job,mapreduce计算(计算引擎自选mapreduce或者spark)。结果存在hbase。结果表在model的storage里面查看。