2019独角兽企业重金招聘Python工程师标准>>> 
由于下定决心开始攻克机器学习。辗转反侧,又是折腾线性代数,又是折腾概率论。然后又看了大学时候的高等数学。弄了大半天。不过今天还好有了收获,把思路进行罗列出来,与大家分享。
数学知识:
由于没法表示数学符号,我都现在这个进行罗列
![]() 向量A
向量A
①直线利用向量表示:{t*向量A | t 属性 R}
在二维平面中 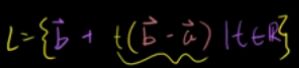 当向量A和向量B不垂直时,此时。这个表达式就可以表示任意一条直线。
当向量A和向量B不垂直时,此时。这个表达式就可以表示任意一条直线。
//由此进行推广,更高维度的直线我们该怎么去表示
②向量的点积 向量A 内积 向量B = 向量A的摸 * 向量B的摸 *cos //没找到数学符号,先将就的这看
就这两个数学概念就可以最简单的解决:文本相似度
----------------------------------------------------------------------------------------------------------------------------
程序思路:
1.读取文本
2.文本内容转码
3.文本分词
4. 剔除 文本分词后中 包含停用词的词组 之后统计剩余分词在 对比文本中分词出现的词频--》待分类词频
5.将待分类词频比标准分类词频 利用余弦定理计算夹角,夹角的大小就是相似的大小
下面我来解释下:
第四步 作用,实质就是利用字典统计,来统计词组出现的频率,然后把词组看做成一个多维空间的直线《----》直线的矩阵表示
第五步作用 把直线利用向量进行的表示,然后利用向量的内积,就可以算出他们的夹角。这个是不是很简单。这是我首次发现数学的作用
下面我把代码进行展示(Python3.4)
import numpy as np
import jieba
import copy
import codecs,sys
ftest1fn = "D:\Tempory\mobile2.txt"
ftest2fn = "D:\Tempory\war2.txt"
sampfn = "D:\Tempory\war1.txt"
def get_cossimi(x,y):
myx = np.array(x)
myy = np.array(y)
cos1 = np.sum(myx * myy)
cos21 = np.sqrt(sum(myx * myx))
cos22 = np.sqrt(sum(myy * myy))
return cos1 / (cos21 * cos22)
if __name__ == '__main__':
print("loading...")
print("working...")
f1 = codecs.open(sampfn,"r","utf-8")
try:
f1_text = f1.read()
finally:
f1.close()
f1_seg_list = jieba.cut(f1_text)
#first test
ftest1 = codecs.open(ftest1fn,"r", "utf-8")
try:
ftest1_text = ftest1.read()
finally:
ftest1.close()
ftest1_seg_list = jieba.cut(ftest1_text)
#second test
ftest2 = codecs.open(ftest2fn, "r", "utf-8")
try:
ftest2_text = ftest2.read()
finally:
ftest2.close()
ftest2_seg_list = jieba.cut(ftest2_text)
#read sample text
#remove stop word and constructor dict
f_stop = codecs.open("D:\Tempory\stopwords.txt","r","utf-8")
try:
f_stop_text = f_stop.read()
finally:
f_stop.close()
f_stop_seg_list = f_stop_text.split("\n")
test_words = {}
all_words = {}
for myword in f1_seg_list:
print(".")
if not(myword.strip()) in f_stop_seg_list:
test_words.setdefault(myword, 0)
all_words.setdefault(myword, 0)
all_words[myword] += 1
#read to be tested word
mytest1_words = copy.deepcopy(test_words)
for myword in ftest1_seg_list:
print(".")
if not(myword.strip()) in f_stop_seg_list:
if myword in mytest1_words:
mytest1_words[myword] += 1
mytest2_words = copy.deepcopy(test_words)
for myword in ftest2_seg_list:
print(".")
if not(myword.strip()) in f_stop_seg_list:
if myword in mytest2_words:
mytest2_words[myword] += 1
#calculate sample with to be tested text sample
sampdate = []
test1data = []
test2data = []
for key in all_words.keys():
sampdate.append(all_words[key])
test1data.append(mytest1_words[key])
test2data.append(mytest2_words[key])
test1simi = get_cossimi(sampdate,test1data)
test2simi = get_cossimi(sampdate,test2data)
print("{0}样本{1}的余弦相似度{2}".format(ftest1fn,sampdate,test1simi))
print("{0}样本{1}的余弦相似度{2}".format(ftest2fn,sampdate,test2simi))