标签: 半监督学习
作者:炼己者
欢迎大家访问 我的简书 以及 我的博客
本博客所有内容以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢!
---
摘要:半监督学习很重要,为什么呢?因为人工标注数据成本太高,现在大家参加比赛的数据都是标注好的了,那么如果老板给你一份没有标注的数据,而且有几百万条,让你做个分类什么的,你怎么办?不可能等标注好数据再去训练模型吧,所以你得会半监督学习算法。
不过我在这里先打击大家一下,用sklearn的包做不了大数据量的半监督学习,我用的数据量大概在15000条以上就要报MemoryError错误了,这个是我最讨厌的错误。暂时我还没有解决的办法,如果同志们是小数据量,那就用这个做着玩玩吧。大家如果有兴趣也可以看一下这篇文章——用半监督算法做文本分类
报MemoryError错误怎么办?sklearn提供这么全的文档当然会有这部分的考虑啦。看这里——sklearn 中的模型对于大数据集的处理。可以用partial_fit增量式计算,可惜只针对部分算法,对于半监督学习没有办法。
好了,该说正题了,最近看了sklearn关于半监督学习的例子,它里面有三个例子,在这里我主要想分享一下第三个例子——用半监督学习算法做数字识别
一. 数据集的解读
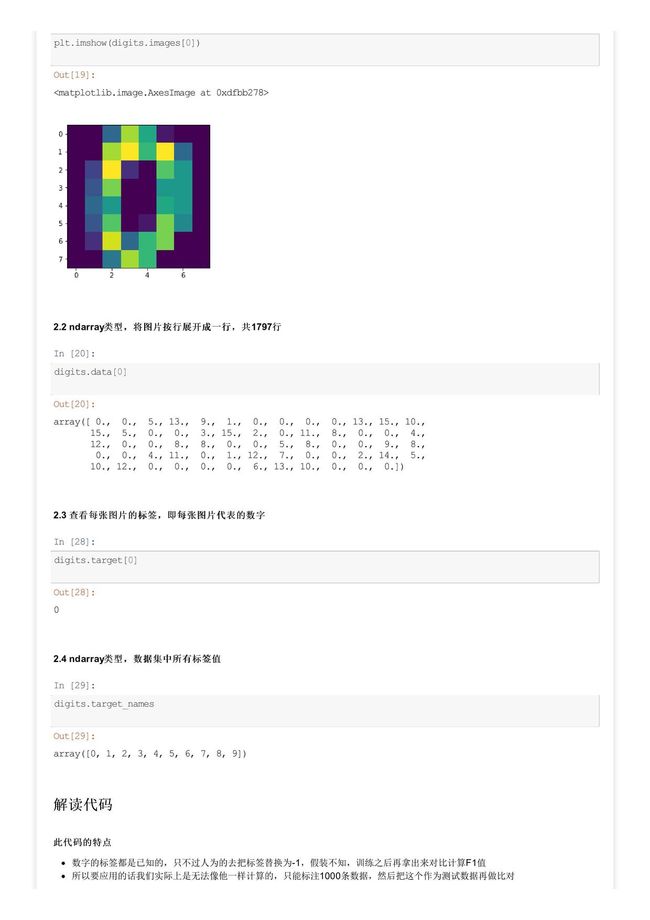
首先我们来看一下这份数据集的特点
二. 代码的解读
sklearn官方例子——用半监督学习做数字识别
我们来看一下操作流程
- 一共330个点,都是已经标注好的了,我们把其中的320个点赋值为-1,这样就可以假装这320个点都是没有标注的了
- 训练一个只有10个标记点的标签传播模型
- 然后从所有数据中选择要标记的前五个最不确定的点,把它们(带有正确标签)放到原来的10个点中
- 接下来可以训练15个标记点(原始10个 + 5个新点)
- 重复这个过程四次,就可以使用30个标记好的点来训练模型
- 可以通过改变max_iterations将这个值增加到30以上
以上是sklearn的操作流程,大家可能会有点糊涂
实际任务应该是这样的。假设我们有一份数据集,共330个数字,其中前十个是已知的,已经标注好了,后320个是未知的,需要我们预测出来的。
- 首先把这330个数据全部都放到半监督学习算法里,训练模型,预测那320个标签
- 然后用某种方法(看下面代码的操作)得知这320个数据里最不确定的前5个数据,对它进行人工标注,然后把它放到之前的10个数据里,现在就有15个已知数据了
- 这样循环个几次,已标注的数据就变多了,那么分类器的效果肯定也就变好了
1.导入各种数据包
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from sklearn import datasets
from sklearn.semi_supervised import label_propagation
from sklearn.metrics import classification_report,confusion_matrix
# 再加下面这个,不然会报错
from scipy.sparse.csgraph import *
2.读取数据集
digits = datasets.load_digits()
rng = np.random.RandomState(0)
# indices是随机产生的0-1796个数字,且打乱
indices = np.arange(len(digits.data))
rng.shuffle(indices)
# 取前330个数字来玩
X = digits.data[indices[:330]]
y = digits.target[indices[:330]]
images = digits.images[indices[:330]]
n_total_samples = len(y) # 330
n_labeled_points = 10 # 标注好的数据共10条
max_iterations = 5 # 迭代5次
unlabeled_indices = np.arange(n_total_samples)[n_labeled_points:] # 未标注的数据320条
f = plt.figure() # 画图用的3. 训练模型且画图
建议大家把自己不懂的地方打印出来看看是啥意思,比如下面
for i in range(max_iterations):
if len(unlabeled_indices) == 0:
print("no unlabeled items left to label") # 没有未标记的标签了,全部标注好了
break
y_train = np.copy(y)
y_train[unlabeled_indices] = -1 #把未标注的数据全部标记为-1,也就是后320条数据
lp_model = label_propagation.LabelSpreading(gamma=0.25,max_iter=5) # 训练模型
lp_model.fit(X,y_train)
predicted_labels = lp_model.transduction_[unlabeled_indices] # 预测的标签
true_labels = y[unlabeled_indices] # 真实的标签
cm = confusion_matrix(true_labels,predicted_labels,
labels = lp_model.classes_)
print("预测标签")
print(predicted_labels)
print("真实标签")
print(true_labels)
print('----------------------------------------------')经对比发现预测的标签只有7个类,而非10个类
- 原因就是我们一开始训练的那10个数据只有7个类,所以预测其他320条数据的时候只能预测出这7个类
预测标签
[2 8 6 6 6 6 1 9 5 8 8 2 8 7 7 6 7 9 2 9 7 7 6 8 9 1 8 1 9 1 1 6 7 7 9 9 7
6 2 1 9 6 7 9 9 9 9 1 6 9 9 2 8 7 2 9 2 6 9 1 8 9 5 1 2 1 2 2 9 7 2 8 6 9
9 8 7 5 1 2 9 9 8 1 7 7 1 1 6 1 5 9 2 6 8 9 2 1 7 7 9 7 8 9 7 5 8 2 1 9 2
9 8 1 1 7 9 6 1 5 8 9 9 6 9 9 5 7 9 6 2 8 6 9 6 1 5 1 5 9 9 1 8 9 6 1 8 9
1 7 6 7 6 5 6 9 8 8 9 8 6 1 9 7 2 6 8 8 6 7 1 9 6 9 9 8 9 8 9 7 7 9 7 8 9
7 8 9 6 7 5 9 1 7 6 1 9 8 9 9 9 9 2 1 1 2 1 1 1 9 2 1 9 8 7 6 1 8 8 1 6 9
9 6 9 2 2 9 7 6 1 1 9 7 2 7 8 6 6 7 5 2 8 7 2 7 9 5 7 9 9 2 6 5 9 7 1 8 8
9 8 6 7 6 9 2 6 1 8 8 1 6 7 5 2 1 5 8 2 1 6 9 1 5 7 9 1 6 2 9 9 1 2 2 9 9
6 9 7 2 9 7 5 8 6 7 8 2 8 7 9 7 2 6 5 1 5 1 9 8]
真实标签
[2 8 6 6 6 6 1 0 5 8 8 7 8 4 7 5 4 9 2 9 4 7 6 8 9 4 3 1 0 1 8 6 7 7 1 0 7
6 2 1 9 6 7 9 0 0 5 1 6 3 0 2 3 4 1 9 2 6 9 1 8 3 5 1 2 8 2 2 9 7 2 3 6 0
5 3 7 5 1 2 9 9 3 1 7 7 4 8 5 8 5 5 2 5 9 0 7 1 4 7 3 4 8 9 7 9 8 2 6 5 2
5 8 4 8 7 0 6 1 5 9 9 9 5 9 9 5 7 5 6 2 8 6 9 6 1 5 1 5 9 9 1 5 3 6 1 8 9
8 7 6 7 6 5 6 0 8 8 9 8 6 1 0 4 1 6 3 8 6 7 4 5 6 3 0 3 3 3 0 7 7 5 7 8 0
7 8 9 6 4 5 0 1 4 6 4 3 3 0 9 5 9 2 1 4 2 1 6 8 9 2 4 9 3 7 6 2 3 3 1 6 9
3 6 3 2 2 0 7 6 1 1 9 7 2 7 8 5 5 7 5 2 3 7 2 7 5 5 7 0 9 1 6 5 9 7 4 3 8
0 3 6 4 6 3 2 6 8 8 8 4 6 7 5 2 4 5 3 2 4 6 9 4 5 4 3 4 6 2 9 0 1 7 2 0 9
6 0 4 2 0 7 9 8 5 4 8 2 8 4 3 7 2 6 9 1 5 1 0 8]
----------------------------------------------
3.1 完整代码
- 大家也可以上官网看看最终打印的结果
用半监督学习做数字识别
for i in range(max_iterations):
if len(unlabeled_indices) == 0:
print("no unlabeled items left to label") # 没有未标记的标签了,全部标注好了
break
y_train = np.copy(y)
y_train[unlabeled_indices] = -1 #把未标注的数据全部标记为-1,也就是后320条数据
lp_model = label_propagation.LabelSpreading(gamma=0.25,max_iter=5) # 训练模型
lp_model.fit(X,y_train)
predicted_labels = lp_model.transduction_[unlabeled_indices] # 预测的标签
true_labels = y[unlabeled_indices] # 真实的标签
cm = confusion_matrix(true_labels,predicted_labels,
labels = lp_model.classes_)
print("iteration %i %s" % (i,70 * "_")) # 打印迭代次数
print("Label Spreading model: %d labeled & %d unlabeled (%d total)"
% (n_labeled_points,n_total_samples-n_labeled_points,n_total_samples))
print(classification_report(true_labels,predicted_labels))
print("Confusion matrix")
print(cm)
# 计算转换标签分布的熵
# lp_model.label_distributions_作用是Categorical distribution for each item
pred_entropies = stats.distributions.entropy(
lp_model.label_distributions_.T)
# 选择分类器最不确定的前5位数字的索引
# 首先计算出所有的熵,也就是不确定性,然后从320个中选择出前5个熵最大的
# numpy.argsort(A)提取排序后各元素在原来数组中的索引。具体情况可看下面
# np.in1d 用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组。具体情况可看下面
uncertainty_index = np.argsort(pred_entropies)[::1]
uncertainty_index = uncertainty_index[
np.in1d(uncertainty_index,unlabeled_indices)][:5] # 这边可以确定每次选前几个作为不确定的数,最终都会加回到训练集
# 跟踪我们获得标签的索引
delete_indices = np.array([])
# 可视化前5次的结果
if i < 5:
f.text(.05,(1 - (i + 1) * .183),
'model %d\n\nfit with\n%d labels' %
((i + 1),i*5+10),size=10)
for index,image_index in enumerate(uncertainty_index):
# image_index是前5个不确定标签
# index就是0-4
image = images[image_index]
# 可视化前5次的结果
if i < 5:
sub = f.add_subplot(5,5,index + 1 + (5*i))
sub.imshow(image,cmap=plt.cm.gray_r)
sub.set_title("predict:%i\ntrue: %i" % (
lp_model.transduction_[image_index],y[image_index]),size=10)
sub.axis('off')
# 从320条里删除要那5个不确定的点
# np.where里面的参数是条件,返回的是满足条件的索引
delete_index, = np.where(unlabeled_indices == image_index)
delete_indices = np.concatenate((delete_indices,delete_index))
unlabeled_indices = np.delete(unlabeled_indices,delete_indices)
# n_labeled_points是前面不确定的点有多少个被标注了
n_labeled_points += len(uncertainty_index)
f.suptitle("Active learning with label propagation.\nRows show 5 most"
"uncertain labels to learn with the next model")
plt.subplots_adjust(0.12,0.03,0.9,0.8,0.2,0.45)
plt.show()3.2 numpy.argsort()函数
- 提取排序后各元素在原来数组中的索引
import numpy as np
B=np.array([[4,2,3,55],[5,6,37,8],[-7,68,9,0]])
print('B:')
print(B)
print('')
print('默认输出')
print(np.argsort(B))#默认的输出每行元素的索引值。这些索引值对应的元素是从小到大排序的。看打印的结果
B:
[[ 4 2 3 55]
[ 5 6 37 8]
[-7 68 9 0]]
默认输出
[[1 2 0 3]
[0 1 3 2]
[0 3 2 1]]
3.3 np.in1d() 函数
- 用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2, 3, 6])看打印的结果
array([ True, False, False, True, True, False, True])三. 总结
这次主要是想用半监督学习算法做NLP文本分类,看到sklearn库里正好有这个算法包,想拿来试一下,结果跑不了那么大的数据量,算是失败了。但是我觉得还是从中了解了很多,后面会写一篇关于它的博客,里面关于文本的处理让我学到了很多,走了很多的弯路。接下来我还会继续探索怎么用少标注的数据来做文本分类。