2019独角兽企业重金招聘Python工程师标准>>> 
G1 VS CMS
GC分类:
-
Minor GC 会清理年轻代的内存。(正常情况大部分年轻代对象朝生夕灭,基本都不存在伊甸区拷贝更不说去老年代了)
-
Major GC 是清理老年代。
-
Full GC 是清理整个堆空间—包括年轻代和老年代
评价垃圾回收质量的两个指标:
-
停顿时间
-
吞吐量
CMS垃圾回收器(基于标记清除):
1、初始标记(STW):标记Gc root根对象,及新生代应用的老年代对象,并作标记。时间快;
2、并发标记:标记线程和用户线程并发执行,标记出根对象的可达路径。从初始标记开始找出所有存活对象(耗时长)。
3、重新标记(STW):从root开始重新扫描直接,间接关联对象,以及上述时间内程序产生的新垃圾对象(远比并发标记时间短)。
4、并发清除:清理垃圾对象。
优点:
并发收集、低停顿。
缺点:
1、内存碎片:由于基于标记清除,因此有内存碎片。
2、cpu敏感:由于并发执行,占用一定的内存cpu,吞吐量会下降
3、浮动垃圾:由于并发处理,用户线程正在使用垃圾无法收集,因此比较早(68%)就要启动收回,回收失败会导致降级为串行收集,有比较大的STW。
https://blog.csdn.net/zqz_zqz/article/details/70568819
老GC遵循原则:
-
年轻代、老年代是独立且连续的内存块;
-
年轻代收集使用单eden、双survivor进行复制算法;
-
老年代收集必须扫描整个老年代区域;
-
都是以尽可能少而块地执行GC为设计原则。
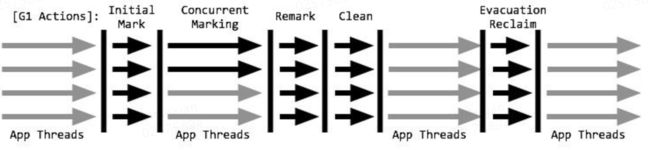
G1垃圾回收(划分若干Region、基于标记整理):
设计原则:
1、引入分区的思路,弱化了分代的概念,回收时则以分区为单位进行回收。每个分区都可能随G1的运行在不同代之间前后切换。(1MB~32MB, 默认2048个分区)
2、首先收集尽可能多的垃圾(Garbage First),采用启发式收集算法,在老年代找出具有高收集收益的分区进行收集(cms则会在将要耗尽内存时候再回收).
3、G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大。
4、G1的收集都是STW的,采用了混合(mixed)收集的方式,同时收集新生代、老年代,通过限制收集范围来控制停顿时间。
回收流程

1、初始标记(STW):标记Gc root根对象并发标记。时间快;
2、根区域扫描(root region scan):根分区扫描,所有新复制到Survivor分区的对象,都需要被扫描并标记成根,这个过程称为根分区扫描(Root Region Scanning)。
2、并发标记:标记线程和用户线程并发执行,标记出根对象的可达路径。从初始标记开始找出所有存活对象(耗时长)。
3、重新标记(STW):从root开始重新扫描直接,间接关联对象,以及上述时间内程序产生的新垃圾对象(远比并发标记时间短)。
4、筛选回收(清除):筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。
优点:
1、可根据用户设置停顿时间,制定回收计划(但是也可能存在超出用户的停顿时间).
2、无内存碎片:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
https://blog.csdn.net/coderlius/article/details/79272773