信用评分卡模型入门
一、背景介绍:
4.数据整理(数据清理过程)
大量取样的数据要真正最后进入模型,必须经过数据整理。在数据处理时应注意检查数据的逻辑性、区分“数据缺失”和“0”、根据逻辑推断某些值、寻找反常数据、评估是否真实。可以通过求最小值、最大值和平均值的方法,初步验证抽样数据是否随机、是否具有代表性。
常用清理过程包含:缺失值分析处理、单变量异常分析(LOF分析处理或聚类分析)
5.变量选择
变量选择要同时具有数学统计的正确性和信用卡实际业务的解释力。
一般性进行单变量统计分布分析和变量相关性分析:

图3. 变量分布是否满足假设(高斯)
Logistic回归同样需要检验多重共线性问题,不过此处由于各变量之间的相关性较小,可以初步判断不存在多重共线性问题,当然我们在建模后还可以用VIF(方差膨胀因子)来检验多重共线性问题。如果存在多重共线性,即有可能存在两个变量高度相关,需要降维或剔除处理。
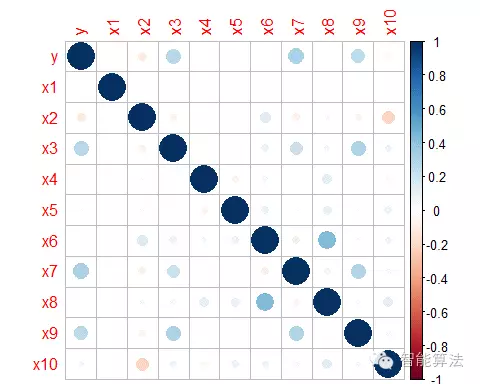
图4. 各维度变量的相关性分析
6.模型建立
关于Logistic回归方法可以查看之前历史文章:经典算法文章,这里不再赘述。其中SAS中也会有这样集成好的工具。这里主要说明一个重要的过程:
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
用WOE(x)替换变量x。WOE()=ln[(违约/总违约)/(正常/总正常)]。
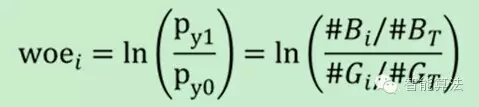

图5. 关于WOE定义与距离
表中以age年龄为某个自变量,由于年龄是连续型自变量,需要对其进行离散化处理,假设离散化分为5组,#bad和#good表示在这五组中违约用户和正常用户的数量分布,最后一列是woe值的计算,通过后面变化之后的公式可以看出,woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。再加上woe计算形式与logistic回归中目标变量的logistic转换(logist_p=ln(p/1-p))如此相似,因而可以将自变量woe值替代原先的自变量值;
这里还需补充一点:WOE转化IV(information value 信息价值):
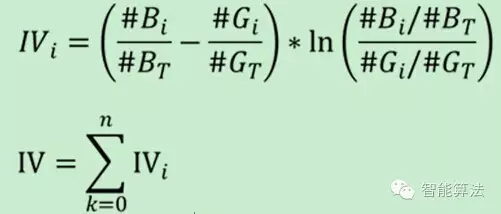
图6. IV公式定义
其实IV衡量的是某一个变量的信息量,从公式来看的话,相当于是自变量woe值的一个加权求和,其值的大小决定了自变量对于目标变量的影响程度;从另一个角度来看的话,IV公式与信息熵的公式极其相似。IV就是这样一种指标,可以用来衡量自变量的预测能力。类似的指标还有信息增益、基尼系数等等。
有了WOE和IV指标就可以进行下一步的模型验证了。
7.模型验证
在收集数据时,把所有整理好的数据分为用于建立模型的建模样本和用于模型验证的对照样本。对照样本用于对模型总体预测性、稳定性进行验证。申请评分模型的模型检验指标包括K-S值、ROC等指标。
通常一个二值分类器可以通过ROC(Receiver Operating Characteristic)曲线和AUC值来评价优劣。
很多二元分类器会产生一个概率预测值,而非仅仅是0-1预测值。我们可以使用某个临界点(例如0.5),以划分哪些预测为1,哪些预测为0。得到二元预测值后,可以构建一个混淆矩阵来评价二元分类器的预测效果。所有的训练数据都会落入这个矩阵中,而对角线上的数字代表了预测正确的数目,即true positive + true nagetive。同时可以相应算出TPR(真正率或称为灵敏度)和TNR(真负率或称为特异度)。我们主观上希望这两个指标越大越好,但可惜二者是一个此消彼涨的关系。除了分类器的训练参数,临界点的选择,也会大大的影响TPR和TNR。有时可以根据具体问题和需要,来选择具体的临界点。
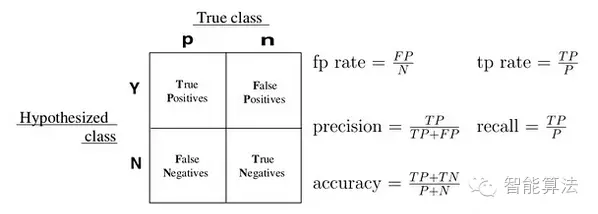
图7. 真假阴阳性定义
如果我们选择一系列的临界点,就会得到一系列的TPR和TNR,将这些值对应的点连接起来,就构成了ROC曲线。ROC曲线可以帮助我们清楚的了解到这个分类器的性能表现,还能方便比较不同分类器的性能。在绘制ROC曲线的时候,习惯上是使用1-TNR作为横坐标即FPR(false positive rate),TPR作为纵坐标。这是就形成了ROC曲线。
而AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
ROC交换曲线现实意义:衡量舍弃好账户和避免坏账户之间的交换关系。理想的情况是:舍弃0%好账户的情况下拒绝100%的坏账户,模型完全准确地把好账户和坏账户区别开来。
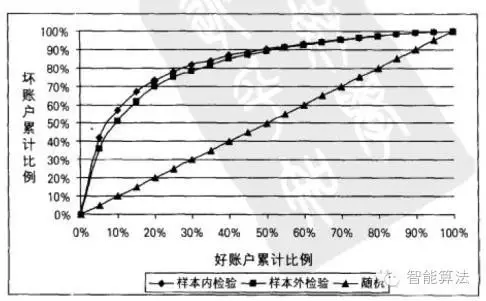
图8. ROC曲线中好坏客户比
k-s指标根据两个数学家命名,与交换曲线类似,衡量的是好账户和坏账户的累计分布比例之间具体最大的差距。好账户和坏账户之间的距离越大,k-s指标越高,模型的区分能力越强。
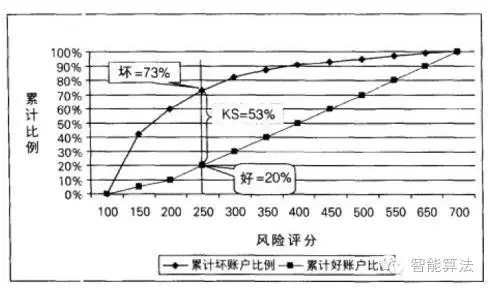
图9. K-S指标图:作为好坏客户的另一种区分标志
这些指标满足之后则基本完成评分卡模型的开发过程。