20 个顶尖的 Python 机器学习开源项目
机器学习 2015-06-08 22:44:30 发布
您的评价:
0.0
收藏 1收藏
我们在Github上的贡献者和提交者之中检查了用Python语言进行机器学习的开源项目,并挑选出最受欢迎和最活跃的项目。”
图1:在GitHub上用Python语言机器学习的项目,图中颜色所对应的Bob, Iepy, Nilearn, 和NuPIC拥有最高的价值。
1. Scikit-learn
www.github.com/scikit-learn/scikit-learn
Scikit-learn 是基于Scipy为机器学习建造的的一个Python模块,他的特色就是多样化的分类,回归和聚类的算法包括支持向量机,逻辑回归,朴素贝叶斯分类器,随机森林,Gradient Boosting,聚类算法和DBSCAN。而且也设计出了Python numerical和scientific libraries Numpy and Scipy
2.Pylearn2
www.github.com/lisa-lab/pylearn2
Pylearn是一个让机器学习研究简单化的基于Theano的库程序。
3.NuPIC
www.github.com/numenta/nupic
NuPIC是一个以HTM学习算法为工具的机器智能平台。HTM是皮层的精确计算方法。HTM的核心是基于时间的持续学习算法和储存和撤销的时空模式。NuPIC适合于各种各样的问题,尤其是检测异常和预测的流数据来源。
4. Nilearn
www.github.com/nilearn/nilearn
Nilearn 是一个能够快速统计学习神经影像数据的Python模块。它利用Python语言中的scikit-learn 工具箱和一些进行预测建模,分类,解码,连通性分析的应用程序来进行多元的统计。
5.PyBrain
www.github.com/pybrain/pybrain
Pybrain是基于Python语言强化学习,人工智能,神经网络库的简称。 它的目标是提供灵活、容易使用并且强大的机器学习算法和进行各种各样的预定义的环境中测试来比较你的算法。
6.Pattern
www.github.com/clips/pattern
Pattern 是Python语言下的一个网络挖掘模块。它为数据挖掘,自然语言处理,网络分析和机器学习提供工具。它支持向量空间模型、聚类、支持向量机和感知机并且用KNN分类法进行分类。
7.Fuel
www.github.com/mila-udem/fuel
Fuel为你的机器学习模型提供数据。他有一个共享如MNIST, CIFAR-10 (图片数据集), Google's One Billion Words (文字)这类数据集的接口。你使用他来通过很多种的方式来替代自己的数据。
8.Bob
www.github.com/idiap/bob
Bob是一个免费的信号处理和机器学习的工具。它的工具箱是用Python和C++语言共同编写的,它的设计目的是变得更加高效并且减少开发时间,它是由处理图像工具,音频和视频处理、机器学习和模式识别的大量软件包构成的。
9.Skdata
www.github.com/jaberg/skdata
Skdata是机器学习和统计的数据集的库程序。这个模块对于玩具问题,流行的计算机视觉和自然语言的数据集提供标准的Python语言的使用。
10.MILK
www.github.com/luispedro/milk
MILK是Python语言下的机器学习工具包。它主要是在很多可得到的分类比如SVMS,K-NN,随机森林,决策树中使用监督分类法。 它还执行特征选择。 这些分类器在许多方面相结合,可以形成不同的例如无监督学习、密切关系金传播和由MILK支持的K-means聚类等分类系统。
11.IEPY
www.github.com/machinalis/iepy
IEPY是一个专注于关系抽取的开源性信息抽取工具。它主要针对的是需要对大型数据集进行信息提取的用户和想要尝试新的算法的科学家。
12.Quepy
www.github.com/machinalis/quepy
Quepy是通过改变自然语言问题从而在数据库查询语言中进行查询的一个Python框架。他可以简单的被定义为在自然语言和数据库查询中不同类型的问题。所以,你不用编码就可以建立你自己的一个用自然语言进入你的数据库的系统。
现在Quepy提供对于Sparql和MQL查询语言的支持。并且计划将它延伸到其他的数据库查询语言。
13.Hebel
www.github.com/hannes-brt/hebel
Hebel是在Python语言中对于神经网络的深度学习的一个库程序,它使用的是通过PyCUDA来进行GPU和CUDA的加速。它是最重要的神经网络模型的类型的工具而且能提供一些不同的活动函数的激活功能,例如动力,涅斯捷罗夫动力,信号丢失和停止法。
14.mlxtend
www.github.com/rasbt/mlxtend
它是一个由有用的工具和日常数据科学任务的扩展组成的一个库程序。
15.nolearn
www.github.com/dnouri/nolearn
这个程序包容纳了大量能对你完成机器学习任务有帮助的实用程序模块。其中大量的模块和scikit-learn一起工作,其它的通常更有用。
16.Ramp
www.github.com/kvh/ramp
Ramp是一个在Python语言下制定机器学习中加快原型设计的解决方案的库程序。他是一个轻型的pandas-based机器学习中可插入的框架,它现存的Python语言下的机器学习和统计工具(比如scikit-learn,rpy2等)Ramp提供了一个简单的声明性语法探索功能从而能够快速有效地实施算法和转换。
17.Feature Forge
www.github.com/machinalis/featureforge
这一系列工具通过与scikit-learn兼容的API,来创建和测试机器学习功能。
这个库程序提供了一组工具,它会让你在许多机器学习程序使用中很受用。当你使用scikit-learn这个工具时,你会感觉到受到了很大的帮助。(虽然这只能在你有不同的算法时起作用。)
18.REP
www.github.com/yandex/rep
REP是以一种和谐、可再生的方式为指挥数据移动驱动所提供的一种环境。
它有一个统一的分类器包装来提供各种各样的操作,例如TMVA, Sklearn, XGBoost, uBoost等等。并且它可以在一个群体以平行的方式训练分类器。同时它也提供了一个交互式的情节。
19.Python 学习机器样品
www.github.com/awslabs/machine-learning-samples
用亚马逊的机器学习建造的简单软件收集。
20.Python-ELM
www.github.com/dclambert/Python-ELM
这是一个在Python语言下基于scikit-learn的极端学习机器的实现。
在这样的背景下, InfoWorld近日公布了机器学习领域11个最受欢迎的开源项目,这11个开源项目大多与垃圾邮件过滤、人脸识别、推荐引擎相关。它们大多数基于现今最流行的语言以及平台,推广以及扩展了机器学习领域的很多重要算法。从中,用户不但可以找到LDA等主题模型,也可以找到HMM等隐马尔科夫模型。这些模型都是应用领域的热点,也是研究者们最需要的。 Scikit-learn Scikit-learn是一个非常强大的Python机器学习工具包。它通过在现有Python的基础上构建了NumPy和Matplotlib,提供了非常便利的数学工具。这个工具包包括了很多简单且高效的工具,很适合用于数据挖掘和数据分析。 在主页中,可以看到User Guide,这是整个机器学习的索引,其中用户可以学到各种有效的方法。在Reference里,用户可以找到各个类具体的用法索引。 Shogun Shogun是一个基于C++的最古老的机器学习开源库,它创建于1999年。作为一个SWIG库,Shogun可以轻松地嵌入Java、Python、C#等主流处理语言中。它的重点在于大尺度上的内核方法,特别是“支持向量机”的学习工具箱。其中,它包括了大量的线性方法,如LDA、LPM、HMM等等。 Accord Framework/AForge.net Accord是AForge.net的扩展,是一个基于.Net的机器学习与信号处理框架。它包括了一系列的对图像和音频的机器学习算法,如人脸检测、SIFT拼接等等。同时,Accord支持移动对象的实时跟踪等功能。它提供了一个从神经网络到决策树系统的机器学习库。 Mahout Mahout是一个广为人知的开源项目,它是Apache Software旗下的一个开源项目,提供了众多的机器学习经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout内包含了聚类、分类、推荐等很多经典算法,并且提供了很方便的云服务的接口。 MLlib MLlib是Apache自己的Spark和Hadoop机器学习库,它被设计用于大规模高速度地执行MLlib所包含的大部分常见机器学习算法。MLlib是基于Java开发的项目,同时可以方便地与Python等语言对接。用户可以自己设计针对MLlib编写代码,这是很具有个性化的设计。 H2O H2O是0xdata的旗舰产品,是一款核心数据分析平台。它的一部分是由R语言编写的,另一部分是由Java和Python语言编写的。用户可以部署H2O的R程序安装包,之后就可以在R语言环境下运行了。H2P的算法是面向业务欺诈活着趋势预测的,目前正在新一轮的融资中。 Cloudera Oryx Oryx也是由Hadoop所设计的机器学习开源项目,由Cloudera Hadoop Distribution的创造者所提供。Oryx能够让机器学习的模型使用在实时的数据流上,如垃圾邮件过滤等。 GoLearn GoLearn是谷歌所构建的Go语言的一体化机器学习库,目标是简单并且可定制。Go语言是谷歌的主打语言,目前使用已经越来越广泛。GoLearn的简单在于数据在库内被加载和处理,因此能够可定制地扩展数据结构以源码。 Weka >Weka是使用Java开发的用户数据挖掘的开源项目。Weka作为一个公开的数据挖掘工作平台,集合了大量能够承担数据挖掘人物的机器学习算法,包括了对数据进行预处理、分类、回归、聚类等等。同时,Weka实现了对大数据的可视化,通过Java设计的新式交互界面上,实现人与程序的交互。 CUDA-Convnet CUDA是我们众所周知的GPU加速套件。而CUDA-Convnet是一个基于GPU加速的神经网络应用程序机器学习库。它使用C++编写,并且使用了NVidia的CUDA GPU处理技术。 目前,这个项目已经被重组成为CUDA-Convnet2,支持多个GPU和Kepler-generation GPUs. Vuples项目与之类似,使用F#语言编写,并且适用于.Net平台上。 ConvNetJS ConvNetJS是一款基于JavaScript的在线深度学习库,它提供了在线的深度学习训练方式。它能够帮助深度学习的初学者更快、更加直观的理解算法,通过一些简单的Demo给用户最直观的解释。
最牛逼的开源机器学习框架,你知道几个 0条评论2015-12-31 10:23 来源:开发者头条 作者: 大白鲸团队 编辑: 崔月 【IT168 评论】机器学习毫无疑问是当今最热的话题,它已经渗透到生活的方方面面,在移动互联网中混不懂点机器学习都不好意思,说几个能看的到的,经常用邮箱吧,是不是感觉垃圾邮件比N年前变少了,无聊了和siri聊过天不,想坐一下无人驾驶汽车吗,手累了用脸解个锁,智能化产品推荐是不是让你更懒了。看不到的就更多了:信用卡欺诈监测保证你的交易安全,股票交易/量化投资(知道你的高收益理财怎么来的吗?),手势识别(用过海豚浏览器的手势吗),还有医学分析等等,巨头们为了在未来占领先机,前仆后继的开源他们的机器学习框架,加速了人类进入智能时代的步伐(说什么,机器人?) Facebook:用于Torch的模块库fbcunn (2015-01-17 开源) fbcunn可以替代Torch的默认模块,它们构建在Nvidia的cuFFT库(一个基于CUDA的库,用于深度神经网络)之上,可以在更短的时间内训练更大规模的神经网络模型,它对NVIDIA的GPU进行了优化。一部分可以用来训练大型计算机视觉系统。部分模块也可以用来训练处理不同类型数据的模型。既可以进行文本识别、图像识别,也能用于语言模型的训练。部分模块将大型卷积神经网络模型的训练速度提升了23.5倍。 fbcunn基于Fast Training of Convolutional Networks through FFTs这篇论文中的想法构建了这些模块,FAIR(Facebook人工智能实验室)的主任Yann LeCun是论文的合著者之一。与cuDNN相比,在卷积核较小的情况下(3x3),fbcunn的速度提升可达1.84倍;而在卷积核较大的情况下(5x5),速度提升可达23.5倍。 Torch和fbcunn的最早的用途之一:图片分类,它分类过ImageNet的120万张图片,可以参考这个地址:https://github.com/soumith/imagenet-multiGPU.torch 参考: http://torch.ch https://github.com/torch/ https://github.com/facebook/fbcunn https://research.facebook.com/blog/879898285375829/fair-open-sources-deep-learning-modules-for-torch/ 微软:DMTK(2015-11-16 开源) DMTK由参数服务器和客户端SDK两部分构成。参数服务器支持存储混合数据结构模型、接受并聚合工作节点服务器的数据模型更新、控制模型同步逻辑;客户端SDK负责维护节点模型缓存(与全局模型服务器同步)、本地训练和模型通讯之间的流水线控制以及片状调度大模型训练。它包含DMTK框架、LightLDA和分布式词向量(Word Embedding)三个组件。 DMTK采用了传统的客户端/服务器架构,有多个服务器实例运行在多台机器上负责维护全局模型参数,而训练例程(routines)则使用客户端API访问并更新这些参数。为了适应不同的集群环境,DMTK框架支持两种进程间的通信机制:MPI和ZMQ。应用程序端不需要修改任何代码就能够在这两种方式之间切换。DMTK支持Windows和Linux两种操作系统。 DMTK则是使用C++编写的,提供了一个客户端API和SDK。 DMTK的官网 对DMTK框架、LightLDA、分布式词向量的应用场景、下载、安装、配置、运行以及性能等方面都做了详尽的介绍(见参考部分)。 DMTK主要用于自然语言处理方面,比如:文本分类与聚类、话题识别以及情感分析等 参考: http://www.dmtk.io https://github.com/Microsoft/DMTK Google:TensorFlow(2015-11-10 开源) TensorFlow 是一个用来编写和执行机器学习算法的工具。计算在数据流图中完成,图中的节点进行数学运算,边界是在各个节点中交换的张量(Tensors--多维数组)。TensorFlow负责在不同的设备、内核以及线程上异步地执行代码,目前支持CNN、RNN和LSTM等图像、语音和自然语言处理(NLP)领域最流行的深度神经网络模型。 Google已将TensorFlow用于GMail(SmartReply)、搜索(RankBrain)、图片(生成图像分类模型--Inception Image Classification Model)、翻译器(字符识别)等产品。 TensorFlow能够在台式机、服务器或者移动设备的CPU和GPU上运行,也可以使用Docker容器部署到云环境中。在处理图像识别、语音识别和语言翻译等任务时,TensorFlow依赖于配备图像处理单元(GPU)的机器和被用于渲染游戏图像的芯片,它对这些芯片依赖度比想象中的高。当前开源的版本能够运行在单机上,暂不支持集群。操作系统方面,TensorFlow能够运行在Linux和MacOS上。 TensorFlow的核心是使用C++编写的,有完整的Python API和C++接口,同时还有一个基于C的客户端API。 参考: https://www.tensorflow.org https://github.com/tensorflow/tensorflow IBM:SystemML (2015-06 开源) SystemML是灵活的,可伸缩机器学习(ML) 语言,使用Java编写。可实现 可定制算法(述性分析、分类、聚类、回归、矩阵分解及生存分析等), 多个执行模式(单独运行、Hadoop 和 Spark ), 自动优化。它由 IBM 的 Almaden 实验室花了近 10年开发而成的机器学习技术。 SystemML语言,声明式机器学习 (DML)。SystemML 包含线性代数原语,统计功能和 ML 指定结构,可以更容易也更原生的表达 ML 算法。算法通过 R 类型或者 Python 类型的语法进行表达。DML 通过提供灵活的定制分析表达和独立于底层输入格式和物理数据表示的数据显著提升数据科学的生产力。 SystemML 运行环境支持 Windows、Linux 及 MacOS,可支持单机和分布式部署。单机部署显然有利于本地开发的工作,而分布式部署则可以真正发挥机器学习的威力,支持的框架包括 Hadoop 和 Spark 众所周知的IBM AIWaston融入了不少SystemML技术(不了解的同学可以看下《Jeopardy!》节目,来领教到沃森的威力) 参考: http://systemml.apache.org https://github.com/apache/incubator-systemml 三星:VELES VELES 是分布式深度学习应用系统,号称:用户只需要提供参数,剩下的我来搞,VELES使用 Python 编写,使用OpenCL 或者 CUDA,利用基于Flow 的编程方式。 参考: https://velesnet.ml https://github.com/Samsung/veles 百度:期待ING。。。 巨头之所以开源自己耗时多年打造的机器学习框架,是希望能够加速在人工智能方面的部署,在人工智能日益重要的未来抢占更多的主导权。而对于机器人创业公司来说,当这么多巨头将机器学习平台开源后,还有什么理由做不好机器人。
盘点 | 今年GitHub排名前20的Python机器学习开源项目 机器之心2016-11-27 13:05:06数据分析 技术 阅读(2277) 评论(0) 选自KDnuggets 作者:Prasad Pore 机器之心编译 参与:杨旋、吴攀 当今时代,开源是创新和技术快速发展的核心。本文来自 KDnuggets 的年度盘点,介绍了2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们的发展趋势。和去年一样,KDnuggets 介绍了 GitHub 上最新的并且排名前 20 的 Python 机器学习开源项目。令人吃惊的是,去年一些最活跃的项目已经停滞不前了,也有一些项目跌出了前 20 名(在 contribution 和 commit 方面),当然,也有 13 个新项目进入了前 20。 2016 年排名前 20 的 Python 机器学习开源项目 1.Scikit-learn是一种基于 NumPy、SciPy 和 matplotlib 的用于数据挖掘和数据分析的工具,其不仅使用起来简单高效,而且还是开源的,可供所有人使用,并且拥有商业可用的 BSD 许可证,在不同的环境下都能很好的被使用。 提交:21486,贡献者:736 链接:http://scikit-learn.org/ 2.TensorFlow 最初由 Google 机器智能研究机构的 Google Brain 团队的研究人员和工程师开发。该系统旨在促进对机器学习的研究,同时也让机器学习研究原型过渡到生产系统更加高效容易。 提交:10466,贡献者:493 链接:https://www.tensorflow.org/ 3.Theano 能让您更加高效地定义、优化和评估涉及多维数组的数学表达式。 提交:24108,贡献者:263 链接:http://deeplearning.net/software/theano/ 4.Caffe是一个由伯克利视觉与学习中心(BVLC)和社区贡献者开发的深度学习框架,它兼具表现力和速度,还有模块化的优点。 提交:3801,贡献者:215 链接:http://caffe.berkeleyvision.org/ 5.Gensim 是一个免费的 Python 库,它具有诸如可扩展的统计语义等特征,它可用于分析纯文本文档的语义结构和检索语义相似的文档。 提交:2702,贡献者:145 链接:https://radimrehurek.com/gensim/ 6.Pylearn2 是一个机器学习库。它的大部分功能都是建立在 Theano 的基础之上。这意味着你可以使用数学表达式编写 Pylearn2 插件(新模型、算法等),然后 Theano 将为你优化这些表达式让其更加稳定,并将根据你的选择把它编译适配相应的后端(CPU 或 GPU)。 提交:7100,贡献者:115 链接:http://github.com/lisa-lab/pylearn2 7.Statsmodels 是一个允许用户挖掘数据、估计统计模型和执行统计测试的 Python 模块。描述性统计、统计测试、绘图函数和结果统计的详细列表可用于不同类型的数据和估计器。 提交:8664,贡献者:108 链接:https://github.com/statsmodels/statsmodels/ 8.Shogun是一种提供大量高效且统一的机器学习(ML)方法的机器学习工具箱。它能容易地把多种数据表示,算法类和通用工具紧密地联系起来。 提交:15172,贡献者:105 链接:https://github.com/shogun-toolbox/shogun 9.Chainer 是一个基于 Python 并且独立的深度学习模型开源框架。Chainer 提供一种灵活、直观且高效的方法来实现整个深度学习模型,包括如循环神经网络和变分自动编码器等最先进的模型。 提交:6298,贡献者:84 链接:https://github.com/pfnet/chainer 10.NuPIC是一个基于一种被称为分层式即时记忆(HTM/ Hierarchical Temporal Memory)的新皮质理论的开源项目。HTM 理论中的一部分已经在应用中被实现、测试和使用了,而其他部分仍在开发中。 提交:6088,贡献者:76 链接:http://github.com/numenta/nupic 11.Neon 是 Nervana (http://nervanasys.com/) 公司的一个基于 Python 的深度学习库。它提供易用性的同时也提供了最高的性能。 提交:875,贡献者:47 链接:http://neon.nervanasys.com/ 12.Nilearn 是一个用于在 NeuroImaging 数据上快速轻松地进行统计学习的 Python 模块。它利用 scikit-learn Python 工具箱来处理如预测建模、分类、解码或连接分析等多变量统计信息。 提交:5254,贡献者:46 链接:http://github.com/nilearn/nilearn 13.Orange3是一个新手和专家都可以使用的开源机器学习和数据可视化工具。在交互式数据分析工作流程中拥有大型的工具箱。 提交:6356,贡献者:40 链接:https://github.com/biolab/orange3 14.Pymc 是一个实现贝叶斯统计模型和拟合算法的 Python 模块,其中包括马尔可夫链和蒙特卡罗方法。其灵活性和可扩展性使其适用于大量问题。 提交:2701,贡献者:37 链接:https://github.com/pymc-devs/pymc 15.PyBrain是 Python 的一个模块化机器学习库。它的目标是为机器学习任务提供灵活且易于使用但仍然强大的算法,以及各种预定义环境来对你的算法进行测试和比较。 提交:984,贡献者:31 链接:http://github.com/pybrain/pybrain 16.Fuel是一个数据管道框架(data pipeline framework),它为你的机器学习模型提供所需的数据。它将被 Blocks 和 Pylearn2 神经网络库使用。 提交:1053,贡献者:29 链接:http://github.com/mila-udem/fuel 17.PyMVPA 是一个用于简化大型数据集的统计学习分析 Python 包。它提供了一个可扩展的框架,具有大量用于分类、回归、特征选择、数据导入和导出等算法的高级接口。 提交:9258,贡献者:26 链接:https://github.com/PyMVPA/PyMVPA 18.Annoy(Approximate Nearest Neighbors Oh Yeah)是一个绑定 Python 的 C ++库,用来搜索在空间中距离给定查询点较近的点。它还创建了基于大型只读文件的数据结构,这些数据结构被映射到内存中,以便许多进程可以共享相同的数据。 提交:365,贡献者:24 链接:https://github.com/spotify/annoy 19.Deap 是一个用于快速原型和测试思想的新颖的进化计算框架。它试图使算法更加浅显易懂,数据结构更加透明。它与并行机制(例如 multiprocessing 和 SCOOP)能完美协调。 提交:1854,贡献者:21 链接:https://github.com/deap/deap 12.Pattern 是 Python 编程语言的 Web 挖掘模块。它捆绑了数据挖掘(Google + Twitter +维基百科 API、网络爬虫、HTML DOM 解析器)、自然语言处理(词性标记、n-gram 搜索、情感分析、WordNet)、机器学习(向量空间模型、k-means 聚类、朴素贝叶斯+ k-NN + SVM 分类器)和网络分析(图形中心性和可视化)等工具。 提交:943,贡献者:20 链接:https://pypi.python.org/pypi/Pattern 从下面的图表中我们可以得知,与其它项目相比,PyMVPA 具有最高的贡献率。令人吃惊的是,相比于其它项目,尽管 Scikit-learn 的贡献者最多,但是它的贡献率比较低。这背后的原因可能是因为 PyMVPA 是一个新的项目,经历了早期的发展阶段,由于新的想法/功能开发,缺陷修复,重构等原因导致了许多提交。而 Scikit-learn 是一个早期的并且比较稳定的项目,所以拥有较少的改进或缺陷修复等提交。 我们对 2015 年和 2016 年的项目进行了比较,它们都是排名前 20 名的项目。我们可以看到 Pattern、PyBrain 和 Pylearn2 的贡献率没有明显的改变,也没有新的贡献者。此外,我们可以在贡献者的数量和提交的数量中看到一个显著的相关性。贡献者的增加可能会导致提交的增加,这也是我认为开源项目和社区神奇的地方;它可以导致头脑风暴,产生新想法以及创造更好的软件工具。 以上就是 KDnuggets 团队根据贡献者数量和提交数量对 2016 年排名前 20 的 Python 机器学习开源项目的分析。 开源和知识共享是令人快乐的一件事! 原文连接:http://www.kdnuggets.com/2016/11/top-20-python-machine-learning-open-source-updated.html
28款GitHub最流行的开源机器学习项目
现在机器学习逐渐成为行业热门,经过二十几年的发展,机器学习目前也有了十分广泛的应用,如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、DNA序列测序、语音和手写识别、战略游戏和机器人等方面。
翻译整理了目前GitHub上最受欢迎的28款开源的机器学习项目,以供开发者参考使用。
1. TensorFlow

TensorFlow 是谷歌发布的第二代机器学习系统。据谷歌宣称,在部分基准测试中,TensorFlow的处理速度比第一代的DistBelief加快了2倍之多。
具体的讲,TensorFlow是一个利用数据流图(Data Flow Graphs)进行数值计算的开源软件库:图中的节点( Nodes)代表数学运算操作,同时图中的边(Edges)表示节点之间相互流通的多维数组,即张量(Tensors)。这种灵活的架构可以让使用者在多样化的将计算部署在台式机、服务器或者移动设备的一个或多个CPU上,而且无需重写代码;同时任一基于梯度的机器学习算法均可够借鉴TensorFlow的自动分化(Auto-differentiation);此外通过灵活的Python接口,要在TensorFlow中表达想法也变得更为简单。
TensorFlow最初由Google Brain小组(该小组隶属于Google's Machine Intelligence研究机构)的研究员和工程师开发出来的,开发目的是用于进行机器学习和深度神经网络的研究。但该系统的通用性足以使其广泛用于其他计算领域。
目前Google 内部已在大量使用 AI 技术,包括 Google App 的语音识别、Gmail 的自动回复功能、Google Photos 的图片搜索等都在使用 TensorFlow 。
开发语言:C++
许可协议:Apache License 2.0
GitHub项目地址:https://github.com/tensorflow/tensorflow
2. Scikit-Learn
Scikit-Learn是用于机器学习的Python 模块,它建立在SciPy之上。该项目由David Cournapeau 于2007年创立,当时项目名为Google Summer of Code,自此之后,众多志愿者都为此做出了贡献。
主要特点:
- 操作简单、高效的数据挖掘和数据分析
- 无访问限制,在任何情况下可重新使用
- 建立在NumPy、SciPy 和 matplotlib基础上
Scikit-Learn的基本功能主要被分为六个部分:分类、回归、聚类、数据降维、模型选择、数据预处理,具体可以参考官方网站上的文档。经过测试,Scikit-Learn可在 Python 2.6、Python 2.7 和 Python 3.5上运行。除此之外,它也应该可在Python 3.3和Python 3.4上运行。
注:Scikit-Learn以前被称为Scikits.Learn。
开发语言:Python
许可协议:3-Clause BSD license
GitHub项目地址: https://github.com/scikit-learn/scikit-learn
3.Caffe
Caffe 是由神经网络中的表达式、速度、及模块化产生的深度学习框架。后来它通过伯克利视觉与学习中心((BVLC)和社区参与者的贡献,得以发展形成了以一个伯克利主导,然后加之Github和Caffe-users邮件所组成的一个比较松散和自由的社区。
Caffe是一个基于C++/CUDA架构框架,开发者能够利用它自由的组织网络,目前支持卷积神经网络和全连接神经网络(人工神经网络)。在Linux上,C++可以通过命令行来操作接口,对于MATLAB、Python也有专门的接口,运算上支持CPU和GPU直接无缝切换。
Caffe的特点
- 易用性:Caffe的模型与相应优化都是以文本形式而非代码形式给出, Caffe给出了模型的定义、最优化设置以及预训练的权重,方便快速使用;
- 速度快:能够运行最棒的模型与海量的数据;
- Caffe可与cuDNN结合使用,可用于测试AlexNet模型,在K40上处理一张图片只需要1.17ms;
- 模块化:便于扩展到新的任务和设置上;
- 使用者可通过Caffe提供的各层类型来定义自己的模型;
目前Caffe应用实践主要有数据整理、设计网络结构、训练结果、基于现有训练模型,使用Caffe直接识别。
开发语言:C++
许可协议: BSD 2-Clause license
GitHub项目地址: https://github.com/BVLC/caffe
4. PredictionIO
PredictionIO 是面向开发人员和数据科学家的开源机器学习服务器。它支持事件采集、算法调度、评估,以及经由REST APIs的预测结果查询。使用者可以通过PredictionIO做一些预测,比如个性化推荐、发现内容等。PredictionIO 提供20个预设算法,开发者可以直接将它们运行于自己的数据上。几乎任何应用与PredictionIO集成都可以变得更“聪明”。其主要特点如下所示:
- 基于已有数据可预测用户行为;
- 使用者可选择你自己的机器学习算法;
- 无需担心可扩展性,扩展性好。
PredictionIO 基于 REST API(应用程序接口)标准,不过它还包含 Ruby、Python、Scala、Java 等编程语言的 SDK(软件开发工具包)。其开发语言是Scala语言,数据库方面使用的是MongoDB数据库,计算系统采用Hadoop系统架构。
开发语言:Scala
许可协议: Apache License 2.0
GitHub项目地址: https://github.com/PredictionIO/PredictionIO
5. Brain
Brain是 JavaScript 中的 神经网络库。以下例子说明使用Brain来近似 XOR 功能:
var net = new brain.NeuralNetwork();
net.train([{input: [0, 0], output: [0]},
{input: [0, 1], output: [1]},
{input: [1, 0], output: [1]},
{input: [1, 1], output: [0]}]);
var output = net.run([1, 0]); // [0.987]
当 brain 用于节点中,可使用npm安装:
npm install brain当 brain 用于浏览器,下载最新的 brain.js 文件。训练计算代价比较昂贵,所以应该离线训练网络(或者在 Worker 上),并使用 toFunction() 或者 toJSON()选项,以便将预训练网络插入到网站中。
开发语言:JavaScript
GitHub项目地址: https://github.com/harthur/brain
6. Keras
Keras是极其精简并高度模块化的神经网络库,在TensorFlow 或 Theano 上都能够运行,是一个高度模块化的神经网络库,支持GPU和CPU运算。Keras可以说是Python版的Torch7,对于快速构建CNN模型非常方便,同时也包含了一些最新文献的算法,比如Batch Noramlize,文档教程也很全,在官网上作者都是直接给例子浅显易懂。Keras也支持保存训练好的参数,然后加载已经训练好的参数,进行继续训练。
Keras侧重于开发快速实验,用可能最少延迟实现从理念到结果的转变,即为做好一项研究的关键。
当需要如下要求的深度学习的库时,就可以考虑使用Keras:
- 考虑到简单快速的原型法(通过总体模块性、精简性以及可扩展性);
- 同时支持卷积网络和递归网络,以及两者之间的组合;
- 支持任意连接方案(包括多输入多输出训练);
- 可在CPU 和 GPU 上无缝运行。
Keras目前支持 Python 2.7-3.5。
开发语言:Python
GitHub项目地址:https://github.com/fchollet/keras
7. CNTK
CNTK(Computational Network Toolkit )是一个统一的深度学习工具包,该工具包通过一个有向图将神经网络描述为一系列计算步骤。在有向图中,叶节点表示输入值或网络参数,其他节点表示该节点输入之上的矩阵运算。
CNTK 使得实现和组合如前馈型神经网络DNN、卷积神经网络(CNN)和循环神经网络(RNNs/LSTMs)等流行模式变得非常容易。同时它实现了跨多GPU 和服务器自动分化和并行化的随机梯度下降(SGD,误差反向传播)学习。
下图将CNTK的处理速度(每秒处理的帧数)和其他四个知名的工具包做了比较了。配置采用的是四层全连接的神经网络(参见基准测试脚本)和一个大小是8192 的高效mini batch。在相同的硬件和相应的最新公共软件版本(2015.12.3前的版本)的基础上得到如下结果:
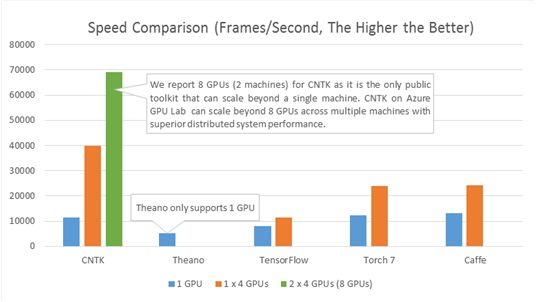
CNTK自2015年四月就已开源。
开发语言:C++
GitHub项目地址:https://github.com/Microsoft/CNTK
8. Convnetjs
ConvNetJS是利用Javascript实现的神经网络,同时还具有非常不错的基于浏览器的Demo。它最重要的用途是帮助深度学习初学者更快、更直观的理解算法。
它目前支持:
- 常见的神经网络模块(全连接层,非线性);
- 分类(SVM/ SOFTMAX)和回归(L2)的成本函数;
- 指定和训练图像处理的卷积网络;
- 基于Deep Q Learning的实验强化学习模型。
一些在线示例:
- Convolutional Neural Network on MNIST digits
- Convolutional Neural Network on CIFAR-10
- Toy 2D data
- Toy 1D regression
- Training an Autoencoder on MNIST digits
- Deep Q Learning Reinforcement Learning demo +Image Regression ("Painting") +Comparison of SGD/Adagrad/Adadelta on MNIST 开发语言:Javascript 许可协议:MIT License GitHub项目地址:https://github.com/karpathy/convnetjs
9. Pattern

Pattern是Python的一个Web挖掘模块。拥有以下工具:
- 数据挖掘:网络服务(Google、Twitter、Wikipedia)、网络爬虫、HTML DOM解析;
- 自然语言处理:词性标注工具(Part-Of-Speech Tagger)、N元搜索(n-gram search)、情感分析(sentiment analysis)、WordNet;
- 机器学习:向量空间模型、聚类、分类(KNN、SVM、 Perceptron);
- 网络分析:图形中心性和可视化。
其文档完善,目前拥有50多个案例和350多个单元测试。 Pattern目前只支持Python 2.5+(尚不支持Python 3),该模块除了在Pattern.vector模块中使用LSA外没有其他任何外部要求,因此只需安装 NumPy (仅在Mac OS X上默认安装)。
开发语言:Python
许可协议:BSD license
GitHub项目地址:https://github.com/clips/pattern
10. NuPIC
NuPIC是一个实现了HTM学习算法的机器智能平台。HTM是一个关于新(大脑)皮质(Neocortex)的详细人工智能算法。HTM的核心是基于时间的连续学习算法,该算法可以存储和调用时间和空间两种模式。NuPIC可以适用于解决各类问题,尤其是异常检测和流数据源预测方面。
NuPIC Binaries文件目前可用于:
- Linux x86 64bit
- OS X 10.9
- OS X 10.10
- Windows 64bit
NuPIC 有自己的独特之处。许多机器学习算法无法适应新模式,而NuPIC的运作接近于人脑,当模式变化的时候,它会忘掉旧模式,记忆新模式。
开发语言:Python
GitHub项目地址:https://github.com/numenta/nupic
11. Theano
Theano是一个Python库,它允许使用者有效地定义、优化和评估涉及多维数组的数学表达式,同时支持GPUs和高效符号分化操作。Theano具有以下特点:
- 与NumPy紧密相关--在Theano的编译功能中使用了Numpy.ndarray ;
- 透明地使用GPU--执行数据密集型计算比CPU快了140多倍(针对Float32);
- 高效符号分化--Theano将函数的导数分为一个或多个不同的输入;
- 速度和稳定性的优化--即使输入的x非常小也可以得到log(1+x)正确结果;
- 动态生成 C代码--表达式计算更快;
- 广泛的单元测试和自我验证--多种错误类型的检测和判定。
自2007年起,Theano一直致力于大型密集型科学计算研究,但它目前也很被广泛应用在课堂之上( 如Montreal大学的深度学习/机器学习课程)。
开发语言:Python
GitHub项目地址:https://github.com/Theano/Theano
12. MXNet

MXNet是一个兼具效率和灵活性的深度学习框架。它允许使用者将符号编程和命令式编程相结合,以追求效率和生产力的最大化。其核心是动态依赖调度程序,该程序可以动态自动进行并行化符号和命令的操作。其中部署的图形优化层使得符号操作更快和内存利用率更高。该库轻量且便携带,并且可扩展到多个GPU和多台主机上。
主要特点:
- 其设计说明提供了有用的见解,可以被重新应用到其他DL项目中;
- 任意计算图的灵活配置;
- 整合了各种编程方法的优势最大限度地提高灵活性和效率;
- 轻量、高效的内存以及支持便携式的智能设备;
- 多GPU扩展和分布式的自动并行化设置;
- 支持Python、R、C++和 Julia;
- 对“云计算”友好,直接兼容S3、HDFS和Azure。
MXNet不仅仅是一个深度学习项目,它更是一个建立深度学习系统的蓝图、指导方针以及黑客们对深度学习系统独特见解的结合体。
开发语言:Jupyter Notebook
开源许可:Apache-2.0 license
GitHub项目地址:https://github.com/dmlc/mxnet
13. Vowpal Wabbit
Vowpal Wabbit是一个机器学习系统,该系统推动了如在线、散列、Allreduce、Learning2search、等方面机器学习前沿技术的发展。 其训练速度很快,在20亿条训练样本,每个训练样本大概100个非零特征的情况下:如果特征的总位数为一万时,训练时间为20分钟;特征总位数为1000万时,训练时间为2个小时。Vowpal Wabbit支持分类、 回归、矩阵分解和LDA。
当在Hadoop上运行Vowpal Wabbit时,有以下优化机制:
- 懒惰初始化:在进行All Reduce之前,可将全部数据加载到内存中并进行缓存。即使某一节点出现了错误,也可以通过在另外一个节点上使用错误节点的数据(通过缓存来获取)来继续训练。
- Speculative Execution:在大规模集群当中,一两个很慢的Mapper会影响整个Job的性能。Speculative Execution的思想是当大部分节点的任务完成时,Hadoop可以将剩余节点上的任务拷贝到其他节点完成。
开发语言:C++
GitHub项目地址:https://github.com/JohnLangford/vowpal_wabbit
14. Ruby Warrior
通过设计了一个游戏使得Ruby语言和人工智能学习更加有乐趣和互动起来。
使用者扮演了一个勇士通过爬上一座高塔,到达顶层获取珍贵的红宝石(Ruby)。在每一层,需要写一个Ruby脚本指导战士打败敌人、营救俘虏、到达楼梯。使用者对每一层都有一些认识,但是你永远都不知道每层具体会发生什么情况。你必须给战士足够的人工智能,以便让其自行寻找应对的方式。
勇士的动作相关API:
-
Warrior.walk: 用来控制勇士的移动,默认方向是往前;
-
warrior.feel:使用勇士来感知前方的情况,比如是空格,还是有怪物;
-
Warrior.attack:让勇士对怪物进行攻击;
-
Warrior.health:获取勇士当前的生命值;
-
Warrior.rest:让勇士休息一回合,恢复最大生命值的10%。
勇士的感知API:
-
Space.empty:感知前方是否是空格;
-
Space.stairs:感知前方是否是楼梯;
-
Space.enemy: 感知前方是否有怪物;
-
Space.captive:感知前方是否有俘虏;
-
Space.wall:感知前方是否是墙壁。
开发语言:Ruby
GitHub项目地址:https://github.com/ryanb/ruby-warrior
15. XGBoost
XGBoot是设计为高效、灵活、可移植的优化分布式梯度 Boosting库。它实现了 Gradient Boosting 框架下的机器学习算法。XGBoost通过提供并行树Boosting(也被称为GBDT、GBM),以一种快速且准确的方式解决了许多数据科学问题。相同的代码可以运行在大型分布式环境如Hadoop、SGE、MP上。它类似于梯度上升框架,但是更加高效。它兼具线性模型求解器和树学习算法。
XGBoot至少比现有的梯度上升实现有至少10倍的提升,同时还提供了多种目标函数,包括回归、分类和排序。由于它在预测性能上的强大,XGBoot成为很多比赛的理想选择,其还具有做交叉验证和发现关键变量的额外功能。
值得注意的是:XGBoost仅适用于数值型向量,因此在使用时需要将所有其他形式的数据转换为数值型向量;在优化模型时,这个算法还有非常多的参数需要调整。
开发语言:C++
开源许可:Apache-2.0 license
GitHub项目地址:https://github.com/dmlc/xgboost
16. GoLearn
GoLearn 是Go 语言中“功能齐全”的机器学习库,简单性及自定义性是其开发目标。
在安装 GoLearn 时,数据作为实例被加载,然后可以在其上操作矩阵,并将操作值传递给估计值。GoLearn 实现了Fit/Predict的Scikit-Learn界面,因此用户可轻松地通过反复试验置换出估计值。此外,GoLearn还包括用于数据的辅助功能,例如交叉验证、训练以及爆裂测试。
开发语言:Go
GitHub项目地址: https://github.com/sjwhitworth/golearn
17. ML_for_Hackers
ML_for_Hackers 是针对黑客机器学习的代码库,该库包含了所有针对黑客的机器学习的代码示例(2012)。该代码可能和文中出现的并不完全相同,因为自出版以来,可能又添加了附加的注释和修改部分。
所有代码均为R语言,依靠众多的R程序包,涉及主题包括分类(Classification)、排行(Ranking)、以及回归(Regression)的所有常见的任务和主成分分析(PCA)和多维尺度(Multi-dimenstional Scaling)等统计方法。
开发语言:R
开源许可:Simplified BSD License
GitHub项目地址: https://github.com/johnmyleswhite/ML_for_Hackers
18. H2O-2
H2O使得Hadoop能够做数学运算!它可以通过大数据衡量统计数据、机器学习和数学。H2O是可扩展的,用户可以在核心区域使用简单的数学模型构建模块。H2O保留着与R、Excel 和JSON等相类似的熟悉的界面,使得大数据爱好者及专家们可通过使用一系列由简单到高级的算法来对数据集进行探索、变换、建模及评分。采集数据很简单,但判决难度却很大,而H2O却通过更快捷、更优化的预测模型,能够更加简单迅速地从数据中获得深刻见解。
0xdata H2O的算法是面向业务流程——欺诈或趋势预测。Hadoop专家可以使用Java与H2O相互作用,但框架还提供了对Python、R以及Scala的捆绑。
开发语言:Java
GitHub项目地址: https://github.com/h2oai/h2o-2
19. neon
neon 是 Nervana 基于 Python 语言的深度学习框架,在诸多常见的深层神经网络中都能够获得较高的性能,比如AlexNet、VGG 或者GoogLeNet。在设计 neon 时,开发者充分考虑了如下功能:
- 支持常用的模型及实例,例如 Convnets、 MLPs、 RNNs、LSTMs、Autoencoders 等,其中许多预训练的实现都可以在模型库中发现;
- 与麦克斯韦GPU中fp16 和 fp32(基准) 的nervanagpu 内核紧密集成;
- 在Titan X(1 GPU ~ 32 hrs上可完整运行)的AlexNet上为3s/macrobatch(3072图像);
- 快速影像字幕模型(速度比基于 NeuralTalk 的CPU 快200倍)。
- 支持基本自动微分;
- 框架可视化;
- 可交换式硬盘后端:一次编写代码,然后配置到 CPU、GPU、或者 Nervana 硬盘。
在 Nervana中,neon被用来解决客户在多个域间存在的各种问题。
开发语言:Python
开源许可:Apache-2.0 license
GitHub项目地址: https://github.com/NervanaSystems/neon
20. Oryx 2
开源项目Oryx提供了简单且实时的大规模机器学习、预测分析的基础设施。它可实现一些常用于商业应用的算法类:协作式过滤/推荐、分类/回归、集群等。此外,Oryx 可利用 Apache Hadoop 在大规模数据流中建立模型,还可以通过HTTP REST API 为这些模型提供实时查询,同时随着新的数据不断流入,可以近似地自动更新模型。这种包括了计算层和服务层的双重设计,能够分别实现一个Lambda 架构。模型在PMML格式交换。

Oryx本质上只做两件事:建模和为模型服务,这就是计算层和服务层两个独立的部分各自的职责。计算层是离线、批量的过程,可从输入数据中建立机器学习模型,它的经营收益在于“代”,即可利用某一点处输入值的快照建模,结果就是随着连续输入的累加,随时间生成一系列输出;服务层也是一个基于Java长期运行的服务器进程,它公开了REST API。使用者可从浏览器中访问,也可利用任何能够发送HTTP请求的语言或工具进行访问。
Oryx的定位不是机器学习算法的程序库,Owen关注的重点有四个:回归、分类、集群和协作式过滤(也就是推荐)。其中推荐系统非常热门,Owen正在与几个Cloudera的客户合作,帮他们使用Oryx部署推荐系统。
开发语言:Java
GitHub项目地址: https://github.com/cloudera/oryx
21. Shogun
Shogun是一个机器学习工具箱,由Soeren Sonnenburg 和Gunnar Raetsch(创建,其重点是大尺度上的内核学习方法,特别是支持向量机(SVM,Support Vector Machines)的学习工具箱。它提供了一个通用的连接到几个不同的SVM实现方式中的SVM对象接口,目前发展最先进的LIBSVM和SVMlight 也位于其中,每个SVM都可以与各种内核相结合。工具箱不仅为常用的内核程序(如线性、多项式、高斯和S型核函数)提供了高效的实现途径,还自带了一些近期的字符串内核函数,例如局部性的改进、Fischer、TOP、Spectrum、加权度内核与移位,后来有效的LINADD优化内核函数也已经实现。
此外,Shogun还提供了使用自定义预计算内核工作的自由,其中一个重要特征就是可以通过多个子内核的加权线性组合来构造的组合核,每个子内核无需工作在同一个域中。通过使用多内核学习可知最优子内核的加权。
目前Shogun可以解决SVM 2类的分类和回归问题。此外Shogun也添加了了像线性判别分析(LDA)、线性规划(LPM)、(内核)感知等大量线性方法和一些用于训练隐马尔可夫模型的算法。
开发语言:C/C++、Python
许可协议:GPLv3
GitHub项目地址: https://github.com/shogun-toolbox/shogun
22. HLearn
HLearn是由Haskell语言编写的高性能机器学习库,目前它对任意维度空间有着最快最近邻的实现算法。
HLearn同样也是一个研究型项目。该项目的研究目标是为机器学习发掘“最佳可能”的接口。这就涉及到了两个相互冲突的要求:该库应该像由C/C++/Fortran/Assembly开发的底层��那样运行快速;同时也应该像由Python/R/Matlab开发的高级库那样灵活多变。Julia在这个方向上取得了惊人的进步,但是 HLearn“野心”更大。更值得注意的是,HLearn的目标是比低级语言速度更快,比高级语言更加灵活。
为了实现这一目标,HLearn采用了与标准学习库完全不同的接口。在HLearn中H代表着三个不同的概念,这三个概念也是HLearn设计的基本要求:
-
H代表Haskell。机器学习是从数据中预测函数,所以功能性编程语言适应机器学习是完全说的通的。但功能性编程语言并没广泛应用于机器学习,这是因为它们固来缺乏支持学习算法的快速数值计算能力。HLearn通过采用Haskell中的SubHask库获得了快速数值计算能力;
-
H同时代表着Homomorphisms。Homomorphisms是抽象代数的基本概念,HLearn将该代数结构用于学习系统中;
-
H还代表着History monad。在开发新的学习算法过程中,最为困难的任务之一就是调试优化过程。在此之前,是没有办法减轻调试过程的工作量的,但History monad正在试图解决该问题。它可以让你在整个线程优化代码的过程中无需修改原代码。此外,使用该技术时没有增加其他的运行开销。
开发语言:Haskell
GitHub项目地址:https://github.com/mikeizbicki/HLearn
23. MLPNeuralNet
MLPNeuralNet是一个针对iOS和Mac OS系统的快速多层感知神经网络库,可通过已训练的神经网络预测新实例。它利用了向量运算和硬盘加速功能(如果可用),其建立在苹果公司的加速框架之上。

若你已经用Matlab(Python或R)设计了一个预测模型,并希望在iOS应用程序加以应用。在这种情况下,正好需要MLP NeuralNet,而MLP NeuralNet只能加载和运行前向传播方式的模型。MLP NeuralNet 有如下几个特点:
- 分类、多类分类以及回归输出;
- 向量化实现形式;
- 双精度;
- 多重隐含层数或空(此时相当于逻辑学/线性回归)。
开发语言:Objective-C
许可协议:BSD license
GitHub项目地址: https://github.com/nikolaypavlov/MLPNeuralNet
24. Apache Mahout
Mahout 是Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。Apache Mahout项目的目标是建立一个能够快速创建可扩展、高性能机器学习应用的环境。
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和 CF 方面。Mahout 的主要特性包括:
- Taste CF,Taste是Sean Owen在SourceForge上发起的一个针对CF的开源项目,并在2008年被赠予Mahout;
- 一些支持 Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift;
- Distributed Naive Bayes 和 Complementary Naive Bayes 分类实现;
- 针对进化编程的分布式适用性功能;
- Matrix 和矢量库。
使用 Mahout 还可实现内容分类。Mahout 目前支持两种根据贝氏统计来实现内容分类的方法:第一种方法是使用简单的支持 Map-Reduce 的 Naive Bayes 分类器;第二种方法是 Complementary Naive Bayes,它会尝试纠正Naive Bayes方法中的一些问题,同时仍然能够维持简单性和速度。
开发语言:Java
许可协议:Apache
GitHub项目地址: https://github.com/apache/mahout
25. Seldon Server
Seldon是一个开放式的预测平台,提供内容建议和一般的功能性预测。它在Kubernetes集群内运行,因此可以调配到Kubernetes范围内的任一地址:内部部署或云部署(例如,AWS、谷歌云平台、Azure)。另外,它还可以衡量大型企业安装的需求。
开发语言:Java
GitHub项目地址: https://github.com/SeldonIO/seldon-server
26. Datumbox - Framework
Datumbox机器学习框架是用Java编写的一个开源框架,该框架的涵盖大量的机器学习算法和统计方法,并能够处理大尺寸的数据集。
Datumbox API提供了海量的分类器和自然语言处理服务,能够被应用在很多领域的应用,包括了情感分析、话题分类、语言检测、主观分析、垃圾邮件检测、阅读评估、关键词和文本提取等等。目前,Datumbox所有的机器学习服务都能够通过API获取,该框架能够让用户迅速地开发自己的智能应用。目前,基于GPL3.0的Datumbox机器学习框架已经开源并且可以从GitHub上进行下载。
Datumbox的机器学习平台很大程度上已经能够取代普通的智能应用。它具有如下几个显著的优点:
- 强大并且开源。Datumbox API使用了强大的开源机器学习框架Datumbox,使用其高度精确的算法能够迅速地构建创新的应用;
- 易于使用。平台API十分易于使用,它使用了REST&JSON的技术,对于所有的分类器;
- 迅速使用。Datumbox去掉了那些很花时间的复杂机器学习训练模型。用户能够通过平台直接使用分类器。
Datumbox主要可以应用在四个方面:一个是社交媒体的监视,评估用户观点能够通过机器学习解决,Datumbox能够帮助用户构建自己的社交媒体监视工具;第二是搜索引擎优化,其中非常有效的方法就是文档中重要术语的定位和优化;第三点是质量评估,在在线通讯中,评估用户产生内容的质量对于去除垃圾邮件是非常重要的,Datumbox能够自动的评分并且审核这些内容;最后是文本分析,自然语言处理和文本分析工具推动了网上大量应用的产生,平台API能够很轻松地帮助用户进行这些分析。
开发语言:Java
许可协议:Apache License 2.0
GitHub项目地址: https://github.com/datumbox/datumbox-framework
27. Jubatus
Jubatus库是一个运行在分布式环境中的在线机器学习框架,即面向大数据数据流的开源框架。它和Storm有些类似,但能够提供更多的功能,主要功能如下:
- 在线机器学习库:包括分类、聚合和推荐;
- Fv_converter: 数据预处理(用自然语言);
- 在线机器学习框架,支持容错。
Jubatus认为未来的数据分析平台应该同时向三个方向展开:处理更大的数据,深层次的分析和实时处理。于是Jubatus将在线机器学习,分布式计算和随机算法等的优势结合在一起用于机器学习,并支持分类、回归、推荐等基本元素。根据其设计目的,Jubatus有如下的特点:
- 可扩展:支持可扩展的机器学习处理。在普通硬件集群上处理数据速度高达100000条/秒; +实时计算:实时分析数据和更新模型;
- 深层次的数据分析:支持各种分析计算:分类、回归、统计、推荐等。
如果有基于流数据的机器学习方面的需求,Jubatus值得关注。
开发语言:C/C++
许可协议:LGPL
GitHub项目地址: https://github.com/jubatus/jubatus
28. Decider
Decider 是另一个 Ruby 机器学习库,兼具灵活性和可扩展性。Decider内置了对纯文本和URI、填充词汇、停止词删除、字格等的支持,以上这些都可以很容易地在选项中组合。Decider 可支持Ruby中任何可用的存储机制。如果你喜欢,可以保存到数据库中,实现分布式分类。
Decider有几个基准,也兼作集成测试。这些都是定期运行并用于查明CPU和RAM的瓶颈。Decider可以进行大量数学运算,计算相当密集,所以对速度的要求比较高。这是经常使用Ruby1.9和JRuby测试其计算速度。此外,用户的数据集应该完全在内存中,否则将会遇到麻烦。
推荐GitHub上10 个开源深度学习框架
日前,Google 开源了 TensorFlow(GitHub),此举在深度学习领域影响巨大,因为 Google 在人工智能领域的研发成绩斐然,有着雄厚的人才储备,而且 Google 自己的 Gmail 和搜索引擎都在使用自行研发的深度学习工具。
无疑,来自 Google 军火库的 TensorFlow 必然是开源深度学习软件中的明星产品,登陆 GitHub 当天就成为最受关注的项目,当周获得评星数就轻松超过 1 万个。
对于希望在应用中整合深度学习功能的开发者来说,GitHub 上其实还有很多不错的开源项目值得关注,首先我们推荐目前规模人气最高的 TOP3:
一、Caffe。源自加州伯克利分校的 Caffe 被广泛应用,包括 Pinterest 这样的 web 大户。与 TensorFlow 一样,Caffe 也是由 C++ 开发,Caffe 也是 Google 今年早些时候发布的 DeepDream 项目(可以识别喵星人的人工智能神经网络)的基础。
二、Theano。2008 年诞生于蒙特利尔理工学院,Theano 派生出了大量深度学习 Python 软件包,最著名的包括 Blocks 和 Keras。
三、Torch。Torch 诞生已经有十年之久,但是真正起势得益于去年 Facebook 开源了大量 Torch 的深度学习模块和扩展。Torch 另外一个特殊之处是采用了不怎么流行的编程语言 Lua(该语言曾被用来开发视频游戏)。
除了以上三个比较成熟知名的项目,还有很多有特色的深度学习开源框架也值得关注:
四、Brainstorm。来自瑞士人工智能实验室 IDSIA 的一个非常发展前景很不错的深度学习软件包,Brainstorm 能够处理上百层的超级深度神经网络——所谓的公路网络 Highway Networks。
五、Chainer。来自一个日本的深度学习创业公司 Preferred Networks,今年 6 月发布的一个 Python 框架。Chainer 的设计基于 define by run 原则,也就是说,该网络在运行中动态定义,而不是在启动时定义,这里有 Chainer 的详细文档。
六、Deeplearning4j。 顾名思义,Deeplearning4j 是”for Java”的深度学习框架,也是首个商用级别的深度学习开源库。Deeplearning4j 由创业公司 Skymind 于 2014 年 6 月发布,使用 Deeplearning4j 的不乏埃森哲、雪弗兰、博斯咨询和 IBM 等明星企业。
DeepLearning4j 是一个面向生产环境和商业应用的高成熟度深度学习开源库,可与 Hadoop 和 Spark 集成,即插即用,方便开发者在 APP 中快速集成深度学习功能,可应用于以下深度学习领域:
· 人脸/图像识别
· 语音搜索
· 语音转文字(Speech to text)
· 垃圾信息过滤(异常侦测)
· 电商欺诈侦测
七、Marvin。是普林斯顿大学视觉工作组新推出的 C++ 框架。该团队还提供了一个文件用于将 Caffe 模型转化成语 Marvin 兼容的模式。
八、ConvNetJS。这是斯坦福大学博士生 Andrej Karpathy 开发浏览器插件,基于万能的 JavaScript 可以在你的游览器中训练神经网络。Karpathy 还写了一个 ConvNetJS 的入门教程,以及一个简洁的浏览器演示项目。
九、MXNet。出自 CXXNet、Minerva、Purine 等项目的开发者之手,主要用 C++ 编写。MXNet 强调提高内存使用的效率,甚至能在智能手机上运行诸如图像识别等任务。
十、Neon。由创业公司 Nervana Systems 于今年五月开源,在某些基准测试中,由 Python 和 Sass 开发的 Neon 的测试成绩甚至要优于 Caffeine、Torch 和谷歌的 TensorFlow。