云打码平台
注册:普通用户和开发者用户 登录: 登录普通用户(查看余额) 登录开发者用户: 创建一个软件:我的软件->创建软件 下载示例代码:开发者中心->下载最新的DLL->pythonHttp示例代码下载
下载生成的DLL文件打开会有说明


import http.client, mimetypes, urllib, json, time, requests ###################################################################### class YDMHttp: apiurl = 'http://api.yundama.com/api.php' username = '' password = '' appid = '' appkey = '' def __init__(self, username, password, appid, appkey): self.username = username self.password = password self.appid = str(appid) self.appkey = appkey def request(self, fields, files=[]): response = self.post_url(self.apiurl, fields, files) response = json.loads(response) return response def balance(self): data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey} response = self.request(data) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['balance'] else: return -9001 def login(self): data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey} response = self.request(data) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['uid'] else: return -9001 def upload(self, filename, codetype, timeout): data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)} file = {'file': filename} response = self.request(data, file) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['cid'] else: return -9001 def result(self, cid): data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid)} response = self.request(data) return response and response['text'] or '' def decode(self, filename, codetype, timeout): cid = self.upload(filename, codetype, timeout) if (cid > 0): for i in range(0, timeout): result = self.result(cid) if (result != ''): return cid, result else: time.sleep(1) return -3003, '' else: return cid, '' def report(self, cid): data = {'method': 'report', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid), 'flag': '0'} response = self.request(data) if (response): return response['ret'] else: return -9001 def post_url(self, url, fields, files=[]): for key in files: files[key] = open(files[key], 'rb'); res = requests.post(url, files=files, data=fields) return res.text ###################################################################### # 用户名(普通用户) username = 'bobo328410948' # 密码 password = 'bobo328410948' # 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得! appid = 6003 # 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! appkey = '1f4b564483ae5c907a1d34f8e2f2776c' # 图片文件 filename = 'getimage.jpg' # 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html codetype = 1004 # 超时时间,秒 timeout = 10 # 检查 if (username == 'username'): print('请设置好相关参数再测试') else: # 初始化 yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码 uid = yundama.login(); print('uid: %s' % uid) # 查询余额 balance = yundama.balance(); print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果 cid, result = yundama.decode(filename, codetype, timeout); print('cid: %s, result: %s' % (cid, result)) ######################################################################
通过跳过验证码和登录获取数据
首先写出一个读取验证码的脚本
def getCodeDate(userName,pwd,codePath,codeType): # 用户名(普通用户) username = userName # 密码 password = pwd # 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得! appid = 6003 # 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! appkey = '1f4b564483ae5c907a1d34f8e2f2776c' # 图片文件 filename = codePath # 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html codetype = codeType # 超时时间,秒 timeout = 2 result = None # 检查 if (username == 'username'): print('请设置好相关参数再测试') else: # 初始化 yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码 uid = yundama.login(); #print('uid: %s' % uid) # 查询余额 balance = yundama.balance(); #print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果 cid, result = yundama.decode(filename, codetype, timeout); #print('cid: %s, result: %s' % (cid, result)) return result
#人人网的模拟登录 import requests import urllib from lxml import etree #获取session对象 session = requests.Session() #通过session 发送post请求数据来伪装登录时发送post的请求,发送的data数据要靠Fiddler来获取 #将验证码图片进行下载 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } url = 'http://www.renren.com/' page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) code_img_url = tree.xpath('//*[@id="verifyPic_login"]/@src')[0] urllib.request.urlretrieve(url=code_img_url,filename='code.jpg') #识别验证码图片中的数据值 code_data = getCodeDate('bobo328410948','bobo328410948','./code.jpg',2004) #模拟登录 login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201914927558' #data要通过Fillder工具抓包哦 data = { "email":"[email protected]", "icode":code_data, "origURL":"http://www.renren.com/home", "domain":"renren.com", "key_id":"1", "captcha_type":"web_login", "password":"4f0350f09aeffeef86307747218b214b0960bdf35e30811c0d611fe39db96ec1", "rkey":"9e75e8dc3457b14c55a74627fa64fb43", "f":"http%3A%2F%2Fwww.renren.com%2F289676607", } #该次请求产生的cookie会被自动存储到session对象中 session.post(url=login_url,data=data,headers=headers) url = 'http://www.renren.com/289676607/profile' page_text = session.get(url=url,headers=headers).text with open('renren.html','w',encoding='utf-8') as fp: fp.write(page_text)
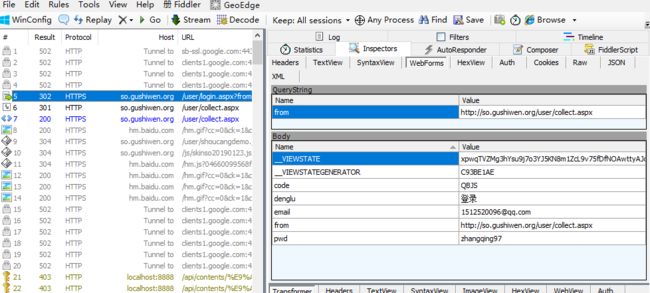
栗子2 换汤不换药
import requests import urllib from lxml import etree headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } #模拟登录古诗文网 s = requests.Session() login_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' page_text = requests.get(url=login_url,headers=headers).text tree = etree.HTML(page_text) img_src = +tree.xpath('//*[@id="imgCode"]/@src')[0] img_data = s.get(url=img_src,headers=headers).content with open('./img.jpg','wb') as fp: fp.write(img_data) img_text = getCodeDate('bobo328410948','bobo328410948','./img.jpg',1004) #模拟登录 url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx' data = { "__VIEWSTATE":"9AsGvh3Je/0pfxId7DYRUi258ayuEG4rrQ1Z3abBgLoDSOeAUatOZOrAIxudqiOauXpR9Zq+dmKJ28+AGjXYHaCZJTTtGgrEemBWI1ed7oS7kpB7Rm/4yma/+9Q=", "__VIEWSTATEGENERATOR":"C93BE1AE", "from":"http://so.gushiwen.org/user/collect.aspx", "email":"[email protected]", "pwd":"bobo328410948", "code":img_text, "denglu":"登录", } page_text = s.post(url=url,headers=headers,data=data).text with open('./gushiwen.html','w',encoding='utf-8') as fp: fp.write(page_text)