样例数据
为了更好的使用和理解ES,没有点样例数据还是不好模拟的。这里提供了一份官网上的数据,accounts.json。如果需要的话,也可以去这个网址玩玩,它可以帮助你自定义写随机的JSON数据。
1、导入数据
打开你的postman,输入对应的REST API,http://127.0.0.1:9200/bank/account/_bulk?pretty
选择post; body->binary; 选择文件,选中你下载好的account.json文件:
注意:
1 127.0.0.1:9200是ES得访问地址和端口
2 bank是索引的名称
3 account是类型的名称
4 索引和类型的名称在文件中如果有定义,可以省略;如果没有则必须要指定
5 _bulk是rest得命令,可以批量执行多个操作
6 pretty是将返回的信息以可读的JSON形式返回。(不过postman自带了pretty的功能)
send之后,可以很快看到结果:
accounts.json数据导入,报错:
1、parse_exception - request body is required
【确认Body->binary导入进了json文件】
2、"Content-Type header [application/x-www-form-urlencoded] is not supported
【需要在headers中添加 Content-Type application/json】
2、查询: http://127.0.0.1:9200/_cat/indices?v

插入1000条数据成功
3、保存对应的REST API到postman
点击save:
在弹出的save窗口中,给对应的request起一个合适的名字,比如这里createBankIndex,并将其保存到对应的collection中(在这里,我已提前创建了一个ElasticSearch的collection,专门用于保存和ES相对应的REST API的操作)。
搜索API
ES提供了两种搜索的方式:请求参数方式 和 请求体方式。
1、请求参数方式
curl 'localhost:9200/bank/_search?q=*&pretty'
其中bank是查询的索引名称,q后面跟着搜索的条件:q=*表示查询所有的内容
2、请求体方式(推荐这种方式)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
请求JSON体 {"query": { "match_all": {} }}
这种方式特别适合在postman里面用,因为postman里面可以使用配合使用各种变量,而且编辑起来更方便:
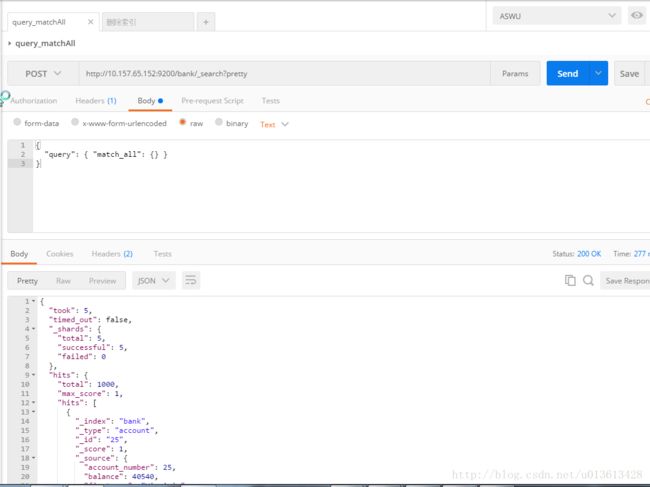
返回的内容大致可以如下讲解:
took:是查询花费的时间,毫秒单位
time_out:标识查询是否超时
_shards:描述了查询分片的信息,查询了多少个分片、成功的分片数量、失败的分片数量等
hits:搜索的结果,total是全部的满足的文档数目,hits是返回的实际数目(默认是10)
_score是文档的分数信息,与排名相关度有关,参考各大搜索引擎的搜索结果,就容易理解。
查询语言DSL
ES支持一种JSON格式的查询,叫做DSL,domain specific language。这门语言刚开始比较难理解,因此通过几个简单的例子开始:
下面的命令,可以搜索全部的文档:
{
"query": { "match_all": {} }
}
query定义了查询,match_all声明了查询的类型。还有其他的参数可以控制返回的结果:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"size": 1
}'
(记住,还是用postman来做客户端,绝逼比curl好用)
上面的命令 返回了所有文档数据中的第一条文档。如果size不指定,那么默认返回10条。
下面的命令请求了第10-20的文档。
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}'
下面的命令指定了文档返回的排序方式:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}'
同 "sort": { "balance": "desc" }
执行搜索
上面了解了基本的搜索语句,下面就开始深入一些常用的DSL了。
之前的返回数据都是返回文档的所有内容,这种对于网络的开销肯定是有影响的,下面的例子就指定了返回特定的字段(account_number和blance):
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}'
再回到query,之前的查询都是查询所有的文档,并不能称之为搜索引擎。下面就通过match方式查询特定字段的特定内容,比如查询余额为20的账户信息:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "account_number": 20 } }
}'
查询地址为mill或者lane的信息:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "address": "mill lane" } }
}'
可以结合之前的Head客户端来使用。
过滤查询
之前说过score字段指定了文档的分数,使用查询会计算文档的分数,最后通过分数确定哪些文档更相关,返回哪些文档。
有的时候我们可能对分数不感兴趣,就可以使用filter进行过滤,它不会去计算分值,因此效率也就更高一些。
filter过滤可以嵌套在bool查询内部使用,比如想要查询在2000-3000范围内的所有文档,可以执行下面的命令:curl -XPOST 'localhost:9200/bank/_search?pretty' -d '


{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}}}}}
}
ES除了上面介绍过的范围查询range、match_all、match、bool、filter还有很多其他的查询方式,这里就先不一一说明了。
参考:用postman快速学习ElasticSearch的搜索功能