How to use tf.data.Dataset API(读取数据)
前言
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。
tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
利用Tensorflow的队列多线程读取数据
十图详解tensorflow数据读取机制-知乎
tf.train.slice_input_producer定义了样本放入文件名队列的方式,包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
但是此类多线程基于队列的读取数据的方式,从TensorFlow 1.2版本以后被抛弃,后续不再提供支持更新,从1.2版本之后,提供DataSet以及tf.contrib.data来支持数据的读取,相关的教程请见:
TensorFlow数据读取(一)Dataset(独立翻译并修改了示例程序,弥补了官方程序的不明确)
TensorFlow 官方中文教程 导入数据(翻译得不太好)
TensorFlow 官方英文教程 导入数据
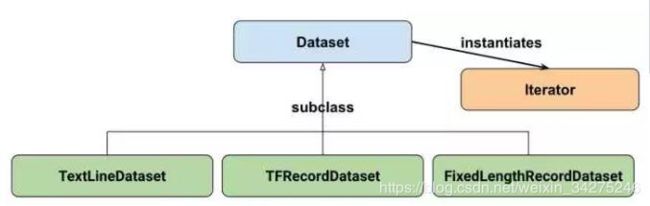
tf.data API 在 TensorFlow 中引入了两个新的抽象类:
-
tf.data.Dataset 表示一系列元素,其中每个元素包含一个或多个 Tensor 对象。例如,在图像管道中,元素可能是单个训练样本,具有一对表示图像数据和标签的张量。可以通过两种不同的方式来创建数据集:
- 创建 source (例如 Dataset.from_tensor_slices()),以通过一个或多个 tf.Tensor 对象构建数据集。
- 应用 transformation (例如 Dataset.batch()),以通过一个或多个 tf.data.Dataset 对象构建数据集。
-
tf.data.Iterator 提供了从数据集中提取元素的主要方法。Iterator.get_next() 返回的操作会在执行时生成 Dataset 的下一个元素,并且此操作通常充当输入管道代码和模型之间的接口。最简单的迭代器是“one-shot iterator”,它与特定的 Dataset 相关联,并对其进行一次迭代。要实现更复杂的用途,您可以通过 Iterator.initializer 操作使用不同的数据集重新初始化和参数化迭代器,这样一来,您就可以在同一个程序中对训练和验证数据进行多次迭代(举例而言)。
数据集结构
一个数据集包含多个元素,每个元素的结构都相同。一个元素包含一个或多个 tf.Tensor 对象,这些对象称为组件。每个组件都有一个 tf.DType,表示张量中元素的类型;以及一个 tf.TensorShape,表示每个元素(可能部分指定)的静态形状。您可以通过 Dataset.output_types 和 Dataset.output_shapes 属性检查数据集元素各个组件的推理类型和形状。这些属性的嵌套结构映射到元素的结构,此元素可以是单个张量、张量元组,也可以是张量的嵌套元组。例如:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
print(dataset1.output_types) # ==> "tf.float32"
print(dataset1.output_shapes) # ==> "(10,)"
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random_uniform([4]),
tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)))
print(dataset2.output_types) # ==> "(tf.float32, tf.int32)"
print(dataset2.output_shapes) # ==> "((), (100,))"
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
print(dataset3.output_types) # ==> (tf.float32, (tf.float32, tf.int32))
print(dataset3.output_shapes) # ==> "(10, ((), (100,)))"
tf.data.Dataset.from_tensor_slices的真正作用是切分传入Tensor的第一个维度,生成相应的dataset。
为元素的每个组件命名通常会带来便利性,例如,如果它们表示训练样本的不同特征。除了元组之外,还可以使用 collections.namedtuple 或将字符串映射到张量的字典来表示 Dataset 的单个元素。
dataset = tf.data.Dataset.from_tensor_slices(
{"a": tf.random_uniform([4]),
"b": tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)})
print(dataset.output_types) # ==> "{'a': tf.float32, 'b': tf.int32}"
print(dataset.output_shapes) # ==> "{'a': (), 'b': (100,)}"
Dataset 转换支持任何结构的数据集。在使用 Dataset.map()、Dataset.flat_map() 和 Dataset.filter() 转换时(这些转换会对每个元素应用一个函数),元素结构决定了函数的参数:
dataset1 = dataset1.map(lambda x: ...)
dataset2 = dataset2.flat_map(lambda x, y: ...)
# Note: Argument destructuring is not available in Python 3.
dataset3 = dataset3.filter(lambda x, (y, z): ...)
创建迭代器
构建了表示输入数据的 Dataset 后,下一步就是创建 Iterator 来访问该数据集中的元素。tf.data API 目前支持下列迭代器,复杂程度逐渐增大:
- one-shot,
- initializable,
- reinitializable,
- feedable.
one-shot是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。单次迭代器可以处理基于队列的现有输入管道支持的几乎所有情况,但它们不支持参数化。以 Dataset.range() 为例:
dataset = tf.data.Dataset.range(5) # [0, 1, 2, 3, 4]
# 创建一个迭代器,该迭代器默认是已经初始化过的,并且不支持重新初始化(不支持数据源的改动)
iterator = dataset.make_one_shot_iterator()
# 获取数据
next_element = iterator.get_next()
# tf.InteractiveSession()是一种交互式的session方式,它让自己成为了默认的session,
# 也就是说用户在不需要指明用哪个session运行的情况下,就可以运行起来,
# 这就是默认的好处。这样的话就是run()和eval()函数可以不指明session啦。
sess = tf.InteractiveSession()
for i in range(5):
value = sess.run(next_element)
print(value)
# 输出
0
1
2
3
4
initializable:您需要先运行显式 iterator.initializer 操作,然后才能使用可初始化迭代器。虽然有些不便,但它允许您使用一个或多个 tf.placeholder() 张量(可在初始化迭代器时馈送)参数化数据集的定义。
#该迭代形式可以和placeholder结合,动态调整数据,比起第一种灵活性提高
max_value = tf.placeholder(tf.int64, shape=[])
dataset = tf.data.Dataset.range(max_value)
# 创建一个迭代器,不同的是该迭代器是未被初始化的
# 在取数据之前,必须执行iterator.initializer节点进行初始化
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
# 获取数据之前要,初始化一个迭代器,并动态的传入你想传入的值
sess.run(iterator.initializer, feed_dict={max_value: 5})
for i in range(5):
# 获取数据
value = sess.run(next_element)
print(value)
# 输出
0
1
2
3
4
剩下两个迭代器见参考文章。
对Dataset中的元素做变换
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
常用的Transformation有:
- map
- batch
- shuffle
- repeat
下面就分别进行介绍。
(1)map
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
dataset = dataset.map(lambda x: x + 1) # 2.0, 3.0, 4.0, 5.0, 6.0
(2)batch
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
dataset = dataset.batch(32)
(3)shuffle
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小:
dataset = dataset.shuffle(buffer_size=10000)
(4)repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
dataset = dataset.repeat(5)
如果直接调用repeat()而不指定重复次数的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常。
读入磁盘图片与对应label
讲到这里,我们可以来考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本。在训练时重复10个epoch。
对应的程序为(从官方示例程序修改而来):
# 函数的功能时将filename对应的图片文件读进来,并缩放到统一的大小
def _parse_function(filename, label):
image_string = tf.read_file(filename)
image_decoded = tf.image.decode_image(image_string)
image_resized = tf.image.resize_images(image_decoded, [28, 28])
return image_resized, label
# 图片文件的列表
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...])
# label[i]就是图片filenames[i]的label
labels = tf.constant([0, 37, ...])
# 此时dataset中的一个元素是(filename, label)
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
# 此时dataset中的一个元素是(image_resized, label)
dataset = dataset.map(_parse_function)
# 此时dataset中的一个元素是(image_resized_batch, label_batch)
dataset = dataset.shuffle(buffersize=1000).batch(32).repeat(10)
测试
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg"])
labels = tf.constant([0, 37])
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
sess = tf.InteractiveSession()
print(sess.run(next_element))
==============================
(b'/var/data/image1.jpg', 0)
消耗迭代器中的值
Iterator.get_next() 方法返回一个或多个 tf.Tensor 对象,这些对象对应于迭代器有符号的下一个元素。每次评估这些张量时,它们都会获取底层数据集中下一个元素的值。(请注意,与 TensorFlow 中的其他有状态对象一样,调用 Iterator.get_next() 并不会立即使迭代器进入下个状态。您必须在 TensorFlow 表达式中使用此函数返回的 tf.Tensor 对象,并将该表达式的结果传递到 tf.Session.run(),以获取下一个元素并使迭代器进入下个状态。)
dataset = tf.data.Dataset.range(5)
iterator = dataset.make_one_shot_iterator() # one_shot迭代器即可
# iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
# Typically `result` will be the output of a model, or an optimizer's
# training operation.
result = tf.add(next_element, next_element)
sess = tf.InteractiveSession()
# sess.run(iterator.initializer) # 用one_shot时无需执行iterator.initializer节点进行初始化
print(sess.run(result)) # ==> "0"
print(sess.run(result)) # ==> "2"
print(sess.run(result)) # ==> "4"
print(sess.run(result)) # ==> "6"
print(sess.run(result)) # ==> "8"
try:
sess.run(result)
except tf.errors.OutOfRangeError:
print("End of dataset") # ==> "End of dataset"
如果迭代器到达数据集的末尾,则执行 Iterator.get_next() 操作会产生 tf.errors.OutOfRangeError。在此之后,迭代器将处于不可用状态;如果需要继续使用,则必须对其重新初始化。
一种常见模式是将“训练循环”封装在 try-except 块中:
sess.run(iterator.initializer)
while True:
try:
sess.run(result)
except tf.errors.OutOfRangeError:
break
如果数据集的每个元素都具有嵌套结构,则 Iterator.get_next() 的返回值将是一个或多个 tf.Tensor 对象,这些对象具有相同的嵌套结构:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
dataset2 = tf.data.Dataset.from_tensor_slices((tf.random_uniform([4]), tf.random_uniform([4, 100])))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
iterator = dataset3.make_initializable_iterator()
sess.run(iterator.initializer)
next1, (next2, next3) = iterator.get_next()
读取输入数据
1. 消耗 NumPy 数组
如果您的所有输入数据都适合存储在内存中,则根据输入数据创建 Dataset 的最简单方法是将它们转换为 tf.Tensor 对象,并使用 Dataset.from_tensor_slices()。
# Load the training data into two NumPy arrays, for example using `np.load()`.
with np.load("/var/data/training_data.npy") as data:
features = data["features"]
labels = data["labels"]
# Assume that each row of `features` corresponds to the same row as `labels`.
assert features.shape[0] == labels.shape[0]
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
请注意,上面的代码段会将 features 和 labels 数组作为 tf.constant() 指令嵌入在 TensorFlow 图中。这样非常适合小型数据集,但会浪费内存,因为会多次复制数组的内容,并可能会达到 tf.GraphDef 协议缓冲区的 2GB 上限。
作为替代方案,您可以根据 tf.placeholder() 张量定义 Dataset,并在对数据集初始化 Iterator 时馈送 NumPy 数组。
# Load the training data into two NumPy arrays, for example using `np.load()`.
with np.load("/var/data/training_data.npy") as data:
features = data["features"]
labels = data["labels"]
# Assume that each row of `features` corresponds to the same row as `labels`.
assert features.shape[0] == labels.shape[0]
features_placeholder = tf.placeholder(features.dtype, features.shape)
labels_placeholder = tf.placeholder(labels.dtype, labels.shape)
dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder))
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer, feed_dict={features_placeholder: features,
labels_placeholder: labels})
2. 消耗 TFRecord 数据
tfrecord数据文件是一种将图像数据和标签统一存储的二进制文件,能更好的利用内存,在tensorflow中快速的复制,移动,读取,存储等。
tf.data API 支持多种文件格式,因此您可以处理那些不适合存储在内存中的大型数据集。例如,TFRecord 文件格式是一种面向记录的简单二进制格式,很多 TensorFlow 应用采用此格式来训练数据。通过 tf.data.TFRecordDataset 类,您可以将一个或多个 TFRecord 文件的内容作为输入管道的一部分进行流式传输。
# Creates a dataset that reads all of the examples from two files.
filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"]
dataset = tf.data.TFRecordDataset(filenames)
TFRecordDataset 初始化程序的 filenames 参数可以是字符串、字符串列表,也可以是字符串 tf.Tensor。因此,如果您有两组分别用于训练和验证的文件,则可以使用 tf.placeholder(tf.string) 来表示文件名,并使用适当的文件名初始化迭代器:
filenames = tf.placeholder(tf.string, shape=[None])
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map() # Parse the record into tensors.
dataset = dataset.repeat() # Repeat the input indefinitely.
dataset = dataset.batch(32)
iterator = dataset.make_initializable_iterator()
# You can feed the initializer with the appropriate filenames for the current
# phase of execution, e.g. training vs. validation.
# Initialize `iterator` with training data.
training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"]
sess.run(iterator.initializer, feed_dict={filenames: training_filenames})
# Initialize `iterator` with validation data.
validation_filenames = ["/var/data/validation1.tfrecord", ...]
sess.run(iterator.initializer, feed_dict={filenames: validation_filenames})
3. 消耗文本数据
很多数据集都是作为一个或多个文本文件分布的。tf.data.TextLineDataset 提供了一种从一个或多个文本文件中提取行的简单方法。给定一个或多个文件名,TextLineDataset 会为这些文件的每行生成一个字符串值元素。像 TFRecordDataset 一样,TextLineDataset 将接受 filenames(作为 tf.Tensor),因此您可以通过传递 tf.placeholder(tf.string) 进行参数化。
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"]
dataset = tf.data.TextLineDataset(filenames)
默认情况下,TextLineDataset 会生成每个文件的每一行,这可能是不可取的(例如,如果文件以标题行开头或包含注释)。可以使用 Dataset.skip() 和 Dataset.filter() 转换来移除这些行。为了将这些转换分别应用于每个文件,我们使用 Dataset.flat_map() 为每个文件创建一个嵌套的 Dataset。
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"]
dataset = tf.data.Dataset.from_tensor_slices(filenames)
# Use `Dataset.flat_map()` to transform each file as a separate nested dataset,
# and then concatenate their contents sequentially into a single "flat" dataset.
# * Skip the first line (header row).
# * Filter out lines beginning with "#" (comments).
dataset = dataset.flat_map(
lambda filename: (
tf.data.TextLineDataset(filename)
.skip(1)
.filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#"))))
4. 消耗 CSV 数据
CSV 文件格式是用于以纯文本格式存储表格数据的常用格式。tf.contrib.data.CsvDataset 类提供了一种从符合 RFC 4180 的一个或多个 CSV 文件中提取记录的方法。给定一个或多个文件名以及默认值列表后,CsvDataset 将生成一个元素元组,元素类型对应于为每个 CSV 记录提供的默认元素类型。像 TFRecordDataset 和 TextLineDataset 一样,CsvDataset 将接受 filenames(作为 tf.Tensor),因此您可以通过传递 tf.placeholder(tf.string) 进行参数化。
# Creates a dataset that reads all of the records from two CSV files, each with
# eight float columns
filenames = ["/var/data/file1.csv", "/var/data/file2.csv"]
record_defaults = [tf.float32] * 8 # Eight required float columns
dataset = tf.contrib.data.CsvDataset(filenames, record_defaults)
如果某些列为空,则可以提供默认值而不是类型。
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values
record_defaults = [[0.0]] * 8
dataset = tf.contrib.data.CsvDataset(filenames, record_defaults)
默认情况下,CsvDataset 生成文件的每一列或每一行,这可能是不可取的;例如,如果文件以应忽略的标题行开头,或如果输入中不需要某些列。可以分别使用 header 和 select_cols 参数移除这些行和字段。
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [[0.0]] * 2 # Only provide defaults for the selected columns
dataset = tf.contrib.data.CsvDataset(filenames, record_defaults, header=True, select_cols=[2,4])