weka提供了几种处理数据的方式,其中分类和回归是平时用到最多的,也是非常容易理解的,分类就是在已有的数据基础上学习出一个分类函数或者构造出一个分类模型。这个函数或模型能够把数据集中地映射到某个给定的类别上,从而进行数据的预测。就是通过一系列的算法,将看起来本来分散的数据,给划分成一个个不同的类,我们可以知道某个数据为什么要划分到这个类别,后来的数据通过这个过程就可以知道把它划分到哪个类别,从而进行了数据的预测。
要进行分类,我们根据什么分类,这就需要把数据分为训练集和测试集两个部分,先分析训练集的数据的特点构建出分类模型。然后利用构建好的分类模型对测试集的数据进行分类,评估分类的准确性,从而进行分类器的选择。
常用的分类器也是最好容易理解的就是决策树,决策树的结构非常好理解,构建出来的决策树,用户也容易根据数据人工进行分类处理。决策树分类算法是将数据进行分类,生成一棵二叉或者多叉的树状结构。有一个根节点,没有入边(度),可能有多条出边,在树的内部的节点只有一个入边,没有出边的节点称为叶子节点,从根节点到叶子节点的一条路径是一条分类规则,一棵决策树有多条分类规则。
打开weka,选择Explorer

点击进去之后,在第一个选项卡下(Preprocess),选择Open file选择要打开的文件,注意:weka识别的文件只是arff后缀的文件,
arff格式文件主要由两个部分构成,头部定义和数据区。这种格式的文件以%开头的是注释,@attribute开头说明是属性,后面是属性名,属性取值或者属性值的类型,@data后的是数据集,以行为单位,一行代表一条数据,以逗号隔开每个属性值,注意用合适的软件打开,用记事本打开的时候,文件中的换行符号不识别,格式很难看,建议用EditPlus。
在weka的安装文件中有一个data文件夹,里面是weka自带的一些测试数据,我们可以利用他们进行练习,打开weather.nominal.arff文件,可以看到一些基本的信息,也可以利用Save按钮将csv格式的文件保存成arff格式的

,在这之前先将数据进行一下处理,利用提供的数据改成测试数据,从而对数据进行预测。把文件中的play属性值都变成?占位符,否则是无法识别的。选择第二个选项卡Classify分类
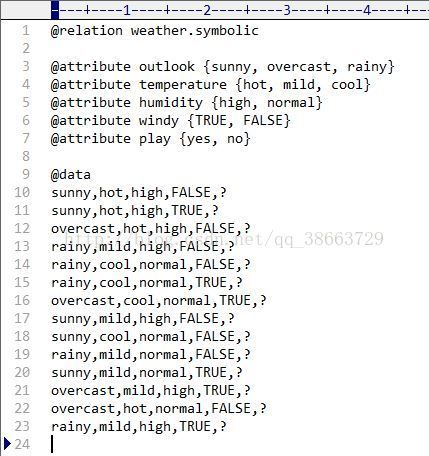
单击choose,在trees目录下选择J48,这是决策树的一个构建类,后期可以通过java调用完成这个操作,Test options中有四个单选按钮,选择第二个,单击右面的set按钮,设置测试数据集,Open file打开之前修改的测试数据集,单击Start,开始运行,右下角的那只鸟如果来回走动表示正在执行,可以看到右面的文本框输出信息

=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: weather.symbolic
Instances: 14
Attributes: 5
outlook
temperature
humidity
windy
play
Test mode: user supplied test set: size unknown (reading incrementally)
=== Classifier model (full training set) ===
J48 pruned tree
------------------
outlook = sunny
| humidity = high: no (3.0)
| humidity = normal: yes (2.0)
outlook = overcast: yes (4.0)
outlook = rainy
| windy = TRUE: no (2.0)
| windy = FALSE: yes (3.0)
Number of Leaves : 5
Size of the tree : 8
Time taken to build model: 0 seconds
=== Evaluation on test set ===
Time taken to test model on supplied test set: 0 seconds
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 14
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.000 0.000 0.000 0.000 0.000 0.000 ? ? yes
0.000 0.000 0.000 0.000 0.000 0.000 ? ? no
Weighted Avg. NaN NaN NaN NaN NaN NaN NaN NaN
=== Confusion Matrix ===
a b <-- classified as
0 0 | a = yes
0 0 | b = no
主要的我们看到输出了决策树的结构,我们可以根据输出的信息自己画出树的结构,也可以通过软件查看树的结构,在文本中在同一缩进距离的信息代表同一层的条件,
右键点击Result list中的选项,并选择visualize tree查看决策树的图形化结构,后期用户可以根据这个人工进行决策

右键点击Result list中的选项,并选择visualize classifier errors。

在出现的窗口中点击Sava按钮,保存输出的文件,之后我们打开输出的文件查看输出的结果,系统在文件中插入了两列数据,其中一列就是预测的值
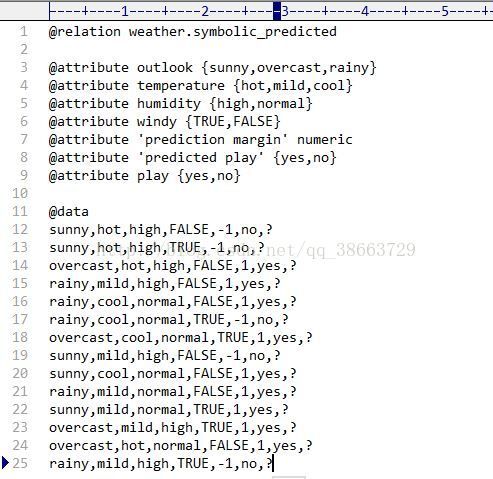
通过对比结果,正确率100%
用weka创建一个简单的回归模型:
准备了一组数据,是所在城市一个商圈附近的二手房价(从二手房网站上抓到),houseSize房屋面积,bedrooms卧室数量,livingrooms客厅数量,restrooms卫生间数量,hardcover是否是精装修(0否,1是)

单击 Classify 选项卡,单击 Choose 按钮,然后扩展 functions 分支,选择 LinearRegression 。在同一个分支还有另外一个选项,称为 SimpleLinearRegression 简单回归,简单回归只有一个变量,我们有多个变量,所以使用LinearRegression,和上面的一样,单击Start,构建模型,得到一个输出文本

有三个选择是:Supplied test set 允许提供一个不同的数据集来构建模型; Cross-validation 让 WEKA 基于所提供的数据的子集构建一个模型,然后求出它们的平均值来创建最终的模型;Percentage split WEKA 取所提供数据的百分之一来构建一个最终的模型。这些不同的选择对于不同的模型非常有用。对于回归,我们可以选择 Use training set。这会告诉weka为了构建我们想要的模型,可以使用我们在 ARFF 文件中提供的那些数据。
我们通过weka构建了一个房屋价格的模型,通过这个沃恩可以分析得到,房屋价格主要与房子面积和卧室数量有关,至于客厅数量和卫生间数量,因为大多数房子只有一个客厅和卫生间,进而对总面积影响小。对于是否是精装修,分析可能原因是,房子都处于商圈附近,房子的精装修并不能带动整体的房价。
sellingPrice =
1.9285 * houseSize +
-30.4737 * bedrooms +
-20.2685我们可以通过以上得到的模型大致预测出其他房屋的价格,但是,房屋价格受各个方面影响太多,只能是估计,可能和实际相差巨大。
如有不对,欢迎指正!