原文链接:blog
本文简要介绍图的 2 种实现及其 BFS 遍历。参考:golang-data-structure-graph
前言
新坑
最近在校事情不多,趁着还记得就开了个新坑 algorithms,把常用数据结构和算法总结了一下。每个算法都有 README.md 介绍算法的运行流程、GIF 演示、复杂度分析及适用场景;每种数据结构会介绍基本概念、操作和应用场景。
参考书籍
《数据结构与算法分析:C 语言描述》
《算法与数据结构题目最优解》
图
图这种数据结构是网状结构的抽象,现实生活中有很多例子,比如航班路线网络、社交网络等。关于图的节点、边、权值、有向无向和强弱连通性等基础概念可参考第一本书第八章。
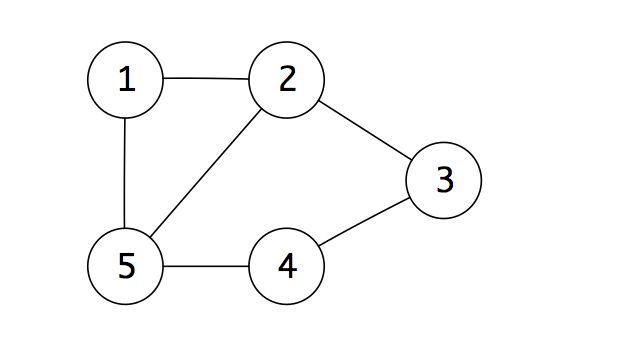
对于上方的无向图,有两种常见的表示方法:
邻接矩阵
对于节点 u 指向节点 v 的边 (u, v),可以表示为 A[u][v] = 1,不直接连接则为0。上图对应的邻接矩阵如下:
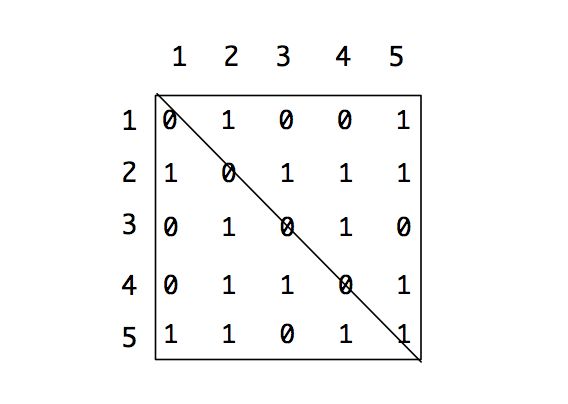
上图的矩阵完整描述了图的连接情况。由于是无向图,邻接矩阵相对主对角线是 对称的: A[u, v] = 1 意味着 A[v, u] = 1,对应到代码实现,是一个二维数组或 map 结构。
邻接表
对于每个节点,将与之直接连接的节点存储在表结构中,上图对应的邻接表如下:
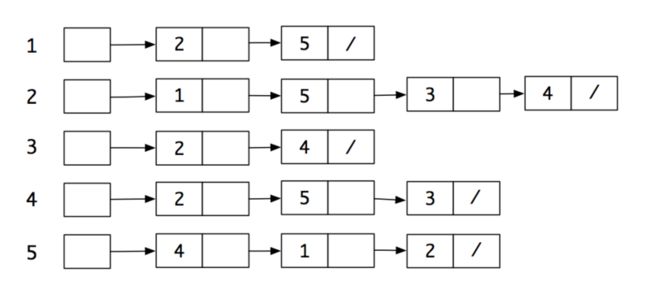
上图中的箭头可表示有向图,在实现上可使用 slice 或链表存储连接节点。
选择存储结构
根据图的 稠密程度 选择存储结构,假设图有 N 个节点 E 条边,若:
E << N^2 则为交叉少的稀疏图
使用邻接表存储只连接的节点,节省存储空间;使用邻接矩阵将要存储大量的 0 值,浪费空间。
E ≈ N^2 则为交叉多的稠密图
使用邻接矩阵将十分方便的查询连通性,较少的浪费存储空间。邻接表将查找麻烦。
图的实现
图有 2 个基本操作:AddNode() 添加节点、 AddEdge() 连接节点形成边。
基本定义
type Node struct {
value int
}
type Graph struct {
nodes []*Node // 节点集
edges map[Node][]*Node // 邻接表表示的无向图
lock sync.RWMutex // 保证线程安全
}操作实现
// 增加节点
func (g *Graph) AddNode(n *Node) {
g.lock.Lock()
defer g.lock.Unlock()
g.nodes = append(g.nodes, n)
}
// 增加边
func (g *Graph) AddEdge(u, v *Node) {
g.lock.Lock()
defer g.lock.Unlock()
// 首次建立图
if g.edges == nil {
g.edges = make(map[Node][]*Node)
}
g.edges[*u] = append(g.edges[*u], v) // 建立 u->v 的边
g.edges[*v] = append(g.edges[*v], u) // 由于是无向图,同时存在 v->u 的边
}
// 输出图
func (g *Graph) String() {
g.lock.RLock()
defer g.lock.RUnlock()
str := ""
for _, iNode := range g.nodes {
str += iNode.String() + " -> "
nexts := g.edges[*iNode]
for _, next := range nexts {
str += next.String() + " "
}
str += "\n"
}
fmt.Println(str)
}
// 输出节点
func (n *Node) String() string {
return fmt.Sprintf("%v", n.value)
}测试
package graph
import "testing"
func TestAdd(t *testing.T) {
g := Graph{}
n1, n2, n3, n4, n5 := Node{1}, Node{2}, Node{3}, Node{4}, Node{5}
g.AddNode(&n1)
g.AddNode(&n2)
g.AddNode(&n3)
g.AddNode(&n4)
g.AddNode(&n5)
g.AddEdge(&n1, &n2)
g.AddEdge(&n1, &n5)
g.AddEdge(&n2, &n3)
g.AddEdge(&n2, &n4)
g.AddEdge(&n2, &n5)
g.AddEdge(&n3, &n4)
g.AddEdge(&n4, &n5)
g.String()
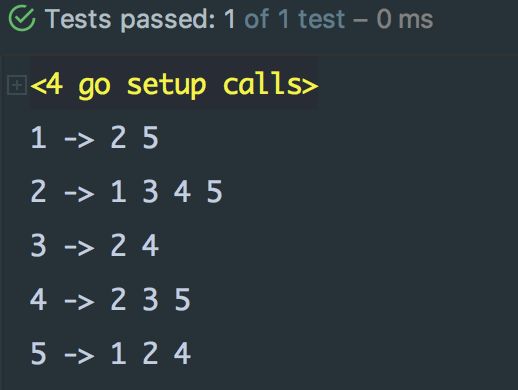
}测试成功:使用邻接表表示上边的无向图
BFS:广度优先搜索
BFS(Breadth First Search):广度优先搜索,广度指的是从一个节点开始 发散性地遍历 周围节点。从某个节点出发,访问它的所有邻接节点,再从这些节点出发,访问它们未被访问过得邻接节点…直到所有节点访问完毕。
有点类似树的层序遍历,但图存在成环的情形,访问过的节点可能会再次访问,所以需要用一个辅助队列来存放待访问的邻接节点。
遍历过程
- 选一节点入队列
-
节点出队列
- 若队列为空,则说明遍历完毕,直接返回
- 将节点的 所有未访问邻接节点 入队列
- 执行回调(可以是用于搜索的等值比较)
- 重复步骤 2
代码实现
package graph
import "sync"
type NodeQueue struct {
nodes []Node
lock sync.RWMutex
}
// 实现 BFS 遍历
func (g *Graph) BFS(f func(node *Node)) {
g.lock.RLock()
defer g.lock.RUnlock()
// 初始化队列
q := NewNodeQueue()
// 取图的第一个节点入队列
head := g.nodes[0]
q.Enqueue(*head)
// 标识节点是否已经被访问过
visited := make(map[*Node]bool)
visited[head] = true
// 遍历所有节点直到队列为空
for {
if q.IsEmpty() {
break
}
node := q.Dequeue()
visited[node] = true
nexts := g.edges[*node]
// 将所有未访问过的邻接节点入队列
for _, next := range nexts {
// 如果节点已被访问过
if visited[next] {
continue
}
q.Enqueue(*next)
visited[next] = true
}
// 对每个正在遍历的节点执行回调
if f != nil {
f(node)
}
}
}
// 生成节点队列
func NewNodeQueue() *NodeQueue {
q := NodeQueue{}
q.lock.Lock()
defer q.lock.Unlock()
q.nodes = []Node{}
return &q
}
// 入队列
func (q *NodeQueue) Enqueue(n Node) {
q.lock.Lock()
defer q.lock.Unlock()
q.nodes = append(q.nodes, n)
}
// 出队列
func (q *NodeQueue) Dequeue() *Node {
q.lock.Lock()
defer q.lock.Unlock()
node := q.nodes[0]
q.nodes = q.nodes[1:]
return &node
}
// 判空
func (q *NodeQueue) IsEmpty() bool {
q.lock.RLock()
defer q.lock.RUnlock()
return len(q.nodes) == 0
}测试
func TestBFS(t *testing.T) {
g.BFS(func(node *Node) {
fmt.Printf("[Current Traverse Node]: %v\n", node)
})
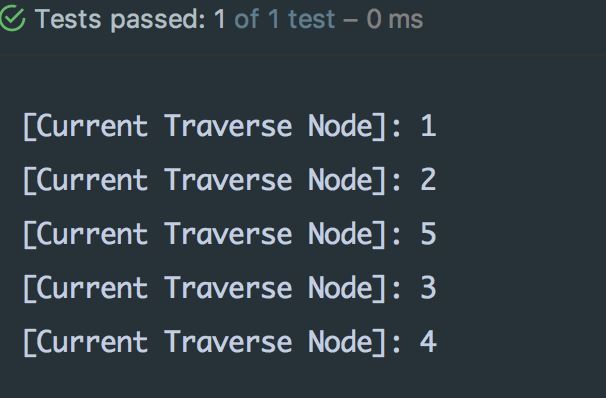
}测试成功:
- 先访问节点 1,再访问邻接 1 的 2 和 5,此时 1、2、5 均标记为已访问过
- 再遍历节点 2 未被访问过的邻接节点:3、4
- 此时所有节点都已被访问过,队列为空。遍历结束
复杂度分析
时间复杂度
对于 N 个节点,E 条边的图,节点和每条边都会被遍历到一次。时间复杂度为 O(N + E)
空间复杂度
对于发散图,辅助队列最多会存放 N 个节点。空间复杂度为 O(N)
总结
其实对于图的遍历有 2 种:BFS 和 DFS,前者使用辅助队列暂存节点,后者使用栈递归调用。二者各有优劣,比如 BFS 能控制队列长度,不像 DFS 那样不易控制栈的大小,DFS 适用于图和树的先序遍历,将放到树的章节学习。