技术分享——mongodb(2)
来填坑了!
ps.本次分享整理自imooc,菜鸟教程和无限百度
这次想说的是分片
定义:将数据进行拆分,按数据水平分散到不用的服务器上
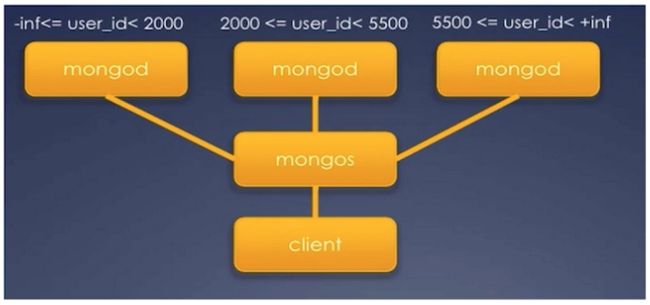
为什么要分片:改善单台机器数据的存储及数据吞吐性能,提高在大数据下随机访问的性能
什么时候用分片:
1.硬件、部署瓶颈
2.性能
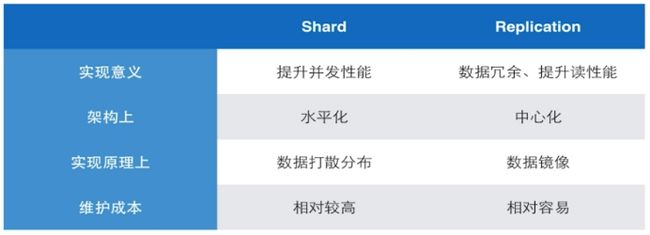
和复制集对比:
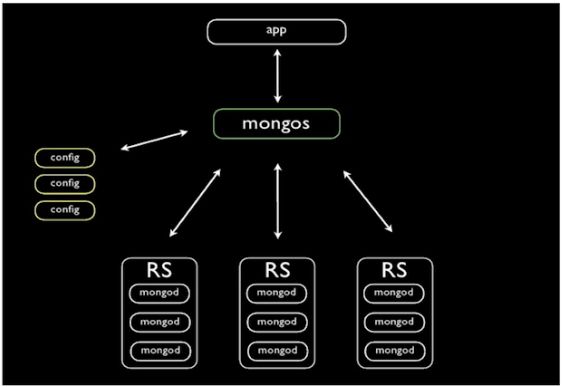
节点成员介绍:
1.Shard节点:存储数据的节点(单个mongod或者复制集)
2.Config server:存储元数据,为mongos服务,将数据路由到shard
3.Mongos:接入前端请求,进行对应消息路由
三者之间的关联
成员节点启动参数:
1.shard节点:
(1)mongod --shardsvr
(2)mongod --shardsvr --rpelSet(副本集)
2.config server:mongod --configsvr
3.mongos --configdb
Mongo分片实战
1.准备材料
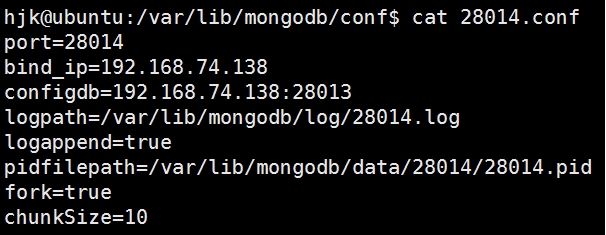
(1)一堆conf
![]()
(1)三个shard节点(28010~28012.conf)
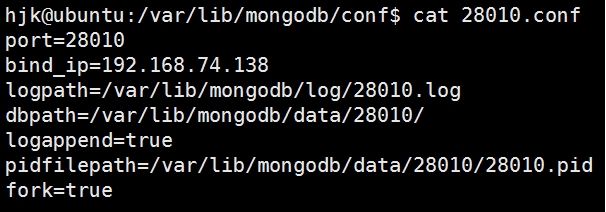
(2)一个config节点用(28013.conf)

(3)一个mongos节点(28014.conf)
2.开启节点
(1)开启shard节点
sudo mongod -f /var/lib/mongodb/conf/28010.conf
sudo mongod -f /var/lib/mongodb/conf/28011.conf
sudo mongod -f /var/lib/mongodb/conf/28012.conf
(2)开启config节点
sudo mongod -f /var/lib/mongodb/conf/28013.conf
(3)开启mongos节点
sudo mongos -f /var/lib/mongodb/conf/28014.conf
3.进入mongos节点
sudo mongo 192.168.74.138:28014
4.添加分片
use admin
db.runCommand({addshard:”192.168.74.138:28010”});
db.runCommand({addshard:”192.168.74.138:28011”});
db.runCommand({addshard:”192.168.74.138:28012”});
5.指定要分片的数据库
db.runCommand({enablesharding:”test”})
6.指定要分片的集合和指定分片片键
db.runCommand({ shardcollection: "test.user_id", key: {“user_id”:1}})
7.插入数据
use shardtest
For(var i=1;i<1000000;i++){db.userid.insert({“user_id”:i})}
8.查看分片状态
db.printShardingStatus()
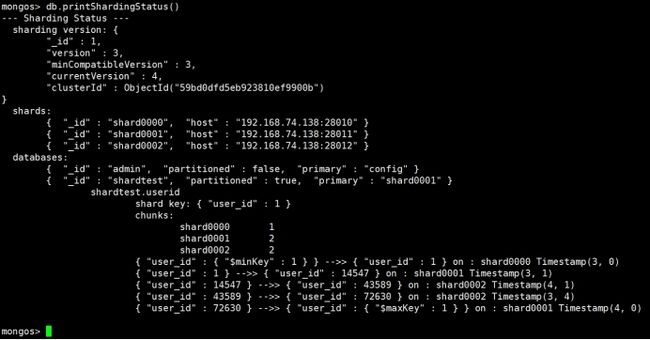
可以看到在三个分片里面都插入了数据
#success
分片片键:集合里面选一个键,用该键的值作为数据拆分的依据
Chunk:mongodb分片后,存储数据的单元块,默认64M,超过最大值后拆分并且拆分信息保存到config服务器
哈希分片:能让数据分布更加均衡
Eg.
//插入数据
Use shardtest
Db.userid_hash.insert({“user_id”:11})
Db.userid_hash.insert({“user_id”:22})
//为userid_hash集合设置哈希分片
Use admin

//写入测试数据
for(i=0;i<100000;i++){db.userid_hash.insert({"user_id":i})}
//查看状态
db.userid_hash.stats()
{
"sharded" : true,
"ns" : "shardtest.userid_hash",
"count" : 100000,
"numExtents" : 15,
"size" : 4000048,
"storageSize" : 8380416,
"totalIndexSize" : 8086064,
"indexSizes" : {
"_id_" : 3262224,
"user_id_hashed" : 4823840
},
"avgObjSize" : 40.00048,
"nindexes" : 2,
"nchunks" : 6,
"shards" : {
"shard0000" : {
"ns" : "shardtest.userid_hash",
"count" : 33755,
"size" : 1350216,
"avgObjSize" : 40.00047400385128,
"storageSize" : 2793472,
"numExtents" : 5,
"nindexes" : 2,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"systemFlags" : 1,
"userFlags" : 0,
"totalIndexSize" : 2755312,
"indexSizes" : {
"_id_" : 1103760,
"user_id_hashed" : 1651552
},
"ok" : 1
},
"shard0001" : {
"ns" : "shardtest.userid_hash",
"count" : 33142,
"size" : 1325696,
"avgObjSize" : 40.00048277110615,
"storageSize" : 2793472,
"numExtents" : 5,
"nindexes" : 2,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"systemFlags" : 1,
"userFlags" : 0,
"totalIndexSize" : 2681728,
"indexSizes" : {
"_id_" : 1079232,
"user_id_hashed" : 1602496
},
"ok" : 1
},
"shard0002" : {
"ns" : "shardtest.userid_hash",
"count" : 33103,
"size" : 1324136,
"avgObjSize" : 40.00048333987856,
"storageSize" : 2793472,
"numExtents" : 5,
"nindexes" : 2,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"systemFlags" : 1,
"userFlags" : 0,
"totalIndexSize" : 2649024,
"indexSizes" : {
"_id_" : 1079232,
"user_id_hashed" : 1569792
},
"ok" : 1
}
},
"ok" : 1
} 
可以看到三个成员的数据分布比较均衡
如何选择合适的片键:
(1)数据块大小(避免选择重复量大的key当作片键,避免按照片键分出来的数据块大小不均衡)
(2)数据写均匀分布(避免选择单调递增的key当作片键,因为这样会导致写操作都在最后一个副本集中添加数据,例如_id和时间,可以考虑用哈希分片)
讲完!溜了溜了。。。