图卷积神经网络(Graph Convolutional Network)之谱卷积
本文主要参考了:
- 从CNN到GCN的联系与区别——GCN从入门到精(fang)通(qi)
- Chebyshev多项式作为GCN卷积核
- 拉普拉斯矩阵与拉普拉斯算子的关系
其他见参考文献部分。
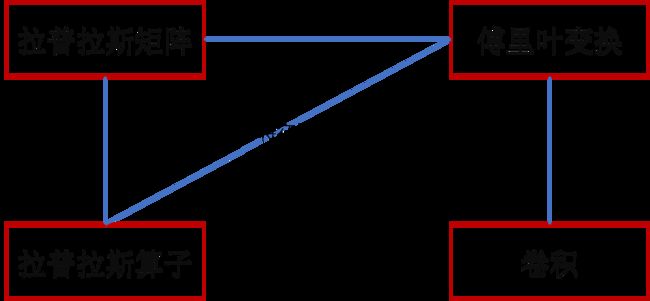
文章目录
- 1.拉普拉斯矩阵
- 1.1 简单图的拉普拉斯矩阵
- 1.2 对称归一化拉普拉斯算子
- 1.3 随机游走归一化拉普拉斯算子
- 1.4 拉普拉斯矩阵的基本性质
- 1.5拉普拉斯矩阵特征值分解
- 2.拉普拉斯算子
- 2.1拉普拉斯算子的定义[5]
- 2.2离散拉普拉斯算子
- 2.3图上的拉普拉斯算子
- 2.4拉普拉斯算子与拉普拉斯矩阵的关系
- 3.傅里叶变换
- 3.1傅里叶变换简要推导[15]
- 3.2离散傅里叶变换[15]
- 3.3图上傅里叶变换
- 3.4为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?特征值表示频率?
- 3.4.1为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?
- 3.4.2怎么理解拉普拉斯矩阵的特征值表示频率?
- 4.GCN卷积
- 4.1图上卷积
- 4.2第一代GCN
- 4.3第二代GCN
- 4.4利用Chebyshev多项式作为卷积核[12]
- 4.4.1Chebyshev多项式性质
- 4.4.2 Chebyshev多项式卷积核
- 4.5 Chebyshev多项式逼近法简化[9,10]
- 4.6 单参数法[9,10]
- 参考文献
1.拉普拉斯矩阵
1.1 简单图的拉普拉斯矩阵
给定一个具有 n n n个顶点的简单无向图 G ( V , E ) G(V,E) G(V,E),
- A A A是图 G = ( V , E ) G=(V,E) G=(V,E)的邻接矩阵
- D D D是顶点的度矩阵(对角矩阵), D i i = ∑ j A i j D_{ii} = \sum_{j}A_{ij} Dii=∑jAij
- 拉普拉斯矩阵 L n × n L_{n \times n} Ln×n为 L = D − A L = D - A L=D−A。
L L L中的元素定义为
L i , j = { d e g ( v i ) if i = j − 1 if i ≠ j and is v i adjacent to v j 0 otherwise L_{i,j} = \begin{cases} deg(v_i) & \text{if } i = j \\ -1 & \text{if } i \neq j \text{and is } v_i \text{ adjacent to } v_j\\ 0 & \text{otherwise} \end{cases} Li,j=⎩⎪⎨⎪⎧deg(vi)−10if i=jif i=jand is vi adjacent to vjotherwise
其中 d e g ( v i ) deg(v_i) deg(vi)是顶点 v i v_i vi的度。
可以验证,对于任意的图 G = ( V , E ) G=(V,E) G=(V,E)的顶点 V V V上的函数 f ∈ R n f \in \mathbb{R}^n f∈Rn都有[14]:
( L f ) ( v i ) = ∑ v i ∼ v j a i , j ( f ( v i ) − f ( v j ) ) . \left( \mathcal{L} f \right)(v_i) = \sum_{v_i \sim v_j} a_{i,j} \left( f(v_i) - f(v_j) \right). (Lf)(vi)=vi∼vj∑ai,j(f(vi)−f(vj)).
其中 v i ∼ v j v_i \sim v_j vi∼vj表示所有与顶点 v i v_i vi相连接的顶点集合, a i , j a_{i,j} ai,j是两顶点 v i , v j v_i,v_j vi,vj之间的连接权重。
1.2 对称归一化拉普拉斯算子
对称归一化拉普拉斯矩阵定义为:
L s y s = D − 1 2 L D − 1 2 = I N − D − 1 2 A D − 1 2 L^{sys} = D^{-\frac{1}{2}} L D^{-\frac{1}{2}} = I_{N} - D^{-\frac{1}{2}} A D^{-\frac{1}{2}} Lsys=D−21LD−21=IN−D−21AD−21
L s y s L^{sys} Lsys中的元素定义为
L i , j s y s = { 1 if i = j and d e g ( v i ) ≠ 0 − 1 d e g ( v i ) d e g ( v j ) if i ≠ j nd is v i adjacent to v j 0 otherwise L_{i,j}^{sys} = \begin{cases} 1 & \text{if } i = j \text{ and } deg(v_i) \neq 0\\ -\frac{1}{\sqrt{deg(v_i) deg(v_j)}}& \text{if } i \neq j \text{ nd is } v_i \text{ adjacent to } v_j\\ 0 & \text{otherwise} \end{cases} Li,jsys=⎩⎪⎪⎨⎪⎪⎧1−deg(vi)deg(vj)10if i=j and deg(vi)=0if i=j nd is vi adjacent to vjotherwise
1.3 随机游走归一化拉普拉斯算子
随机游走归一化拉普拉斯矩阵定义为:
L r w = D − 1 L = I N − D − 1 A L^{rw} = D^{-1} L = I_{N} - D^{-1} A Lrw=D−1L=IN−D−1A
L r w L^{rw} Lrw中的元素定义为
L i , j r w = { 1 if i = j and d e g ( v i ) ≠ 0 − 1 d e g ( v i ) if i ≠ j nd is v i adjacent to v j 0 otherwise L_{i,j}^{rw} = \begin{cases} 1 & \text{if } i = j \text{ and } deg(v_i) \neq 0\\ -\frac{1}{deg(v_i)}& \text{if } i \neq j \text{ nd is } v_i \text{ adjacent to } v_j\\ 0 & \text{otherwise} \end{cases} Li,jrw=⎩⎪⎨⎪⎧1−deg(vi)10if i=j and deg(vi)=0if i=j nd is vi adjacent to vjotherwise
1.4 拉普拉斯矩阵的基本性质
对于(无向)图 G ( V , E ) G(V,E) G(V,E)及其具有特征值的拉普拉斯矩阵 L L L,将其特征值排列为 λ 0 , λ 1 , ⋯ , λ n − 1 \lambda_0, \lambda_1, \cdots, \lambda_{n-1} λ0,λ1,⋯,λn−1:
- L L L是对称的。
- L L L是半正定的,即 λ i ≥ 0 \lambda_i \geq 0 λi≥0。
- L L L的每一行和列总和为零。
- L L L是M矩阵[6]。
L矩阵的定义[8]:若 A A A一个 n × n n\times n n×n的方阵,若 a i i > 0 a_{ii}>0 aii>0, 而 a i j ≤ 0 ( i ≠ j ) a_{ij} \leq 0 (i \neq j) aij≤0(i=j),则称 A A A为L矩阵。
M矩阵的定义[8]:若 A A A为L矩阵,其为M矩阵的条件为下列之一:
- A A A的所有特征值的实部皆为正。
- A A A的所有主子式皆为正。
- A A A的所有顺序主子式皆为正。
- A A A的逆存在且为非负矩阵。
- 有正向量 x ⃗ \vec{x} x,使 A x ⃗ A\vec{x} Ax为正向量。
- 有对角线主元素全为正的对角形矩阵(叫做正对角形矩阵) D D D,使 A D e ⃗ AD\vec{e} ADe为正向量,其中 e ⃗ = ( 1 , ⋯ , 1 ) T \vec{e}=(1,\cdots,1)^T e=(1,⋯,1)T。
- 对实向量 x ⃗ \vec{x} x,若 A x ⃗ A\vec{x} Ax非负,则 x ⃗ \vec{x} x非负。
- 若 D = d i a g ( A ) , C = D − A , B = D − 1 ∗ C D=diag(A), C=D-A,B=D^{-1}*C D=diag(A),C=D−A,B=D−1∗C,则 ρ ( B ) < 1 ρ(B)<1 ρ(B)<1,其中 ρ ( B ) ρ(B) ρ(B)为 B B B的特征值的模的最大值。
- B = λ I − A B=\lambda I-A B=λI−A为非负矩阵,其中 I I I为单位矩阵, λ > ρ ( B ) \lambda>ρ(B) λ>ρ(B)。
- 若 B B B为 L L L矩阵,且 b i j ≥ a i j , i , j = 1 , 2 , ⋯ , n b_{ij} \geq a_{ij}, i,j=1,2,\cdots,n bij≥aij,i,j=1,2,⋯,n,则 B B B的逆存在。
- 存在下三角矩阵 T T T和上三角矩阵 U U U,其中 T T T和 U U U均为L矩阵,使 A = T U A=TU A=TU.
1.5拉普拉斯矩阵特征值分解
对 L L L特征值分解为
L = U ( λ 0 ⋱ λ n − 1 ) U − 1 = U Λ U − 1 . L = U \begin{pmatrix} \lambda_0 & & \\ & \ddots & \\ & & \lambda_{n-1} \\ \end{pmatrix} U^{-1} = U \Lambda U^{-1}. L=U⎝⎛λ0⋱λn−1⎠⎞U−1=UΛU−1.
其中 U = ( u ⃗ 0 , u ⃗ 1 , ⋯ , u ⃗ n − 1 ) U = (\vec{u}_0,\vec{u}_1,\cdots, \vec{u}_{n-1}) U=(u0,u1,⋯,un−1)是由 L L L的特征向量(列向量)组成的矩阵,相应列的特征向量与特征值矩阵 Λ \Lambda Λ相应列的特征值相互对应。
由于 U U U是正交矩阵,即 U U T = I n U U^T = I_n UUT=In,即上面的式子又可以写成:
L = U Λ U T . L = U \Lambda U^T. L=UΛUT.
2.拉普拉斯算子
2.1拉普拉斯算子的定义[5]
梯度 : 设 f : R 3 → R f:\mathbb{R}^3 \rightarrow \mathbb{R} f:R3→R在空间区域 G G G上具有一阶连续偏导数,点 P ( x 1 , x 2 , x 3 ) ∈ G P(x_1, x_2, x_3) \in G P(x1,x2,x3)∈G,称向量
( ∂ f ∂ x 1 , ∂ f ∂ x 2 , ∂ f ∂ x 3 ) = ∂ f ∂ x 1 i 1 ⃗ + ∂ f ∂ x 2 i 2 ⃗ + ∂ f ∂ x 3 i 3 ⃗ \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \frac{\partial f}{\partial x_3} \right) = \frac{\partial f}{\partial x_1} \vec{i_1} + \frac{\partial f}{\partial x_2} \vec{i_2} + \frac{\partial f}{\partial x_3} \vec{i_3} (∂x1∂f,∂x2∂f,∂x3∂f)=∂x1∂fi1+∂x2∂fi2+∂x3∂fi3
为函数 f f f在点 P P P处的梯度,记作 ∇ f ( x 1 , x 2 , x 3 ) \nabla f (x_1, x_2, x_3) ∇f(x1,x2,x3)或 g r a d ( f ) grad(f) grad(f)。
其中
∇ = ∂ ∂ x 1 i 1 ⃗ + ∂ ∂ x 2 i 2 ⃗ + ∂ ∂ x 3 i 3 ⃗ \nabla = \frac{\partial}{\partial x_1} \vec{i_1} + \frac{\partial}{\partial x_2} \vec{i_2} + \frac{\partial}{\partial x_3} \vec{i_3} ∇=∂x1∂i1+∂x2∂i2+∂x3∂i3
称作(三维)向量的微分算子。多维的则为 ∇ = ∑ j = 1 n ∂ ∂ x j i j ⃗ \nabla = \sum_{j=1}^{n} \frac{\partial}{\partial x_j} \vec{i_j} ∇=∑j=1n∂xj∂ij。
散度 散度 " ∇ . \nabla . ∇. " (divergence)可用于表针空间中各点矢量场发散的强弱程度,物理上,散度的意义是场的有源性。当 d i v ( F ) > 0 div(F) > 0 div(F)>0,表示该点有散发通量的正源(发散源);当 d i v ( F ) < 0 div(F) < 0 div(F)<0 表示该点有吸收能量的负源(洞或汇);当 d i v ( F ) = 0 div(F) = 0 div(F)=0,表示该点无源。
拉普拉斯算子: 拉普拉斯算子(Laplace Operator)是 n n n维欧几里得空间中的一个二阶微分算子,定义为梯度( ∇ f \nabla f ∇f )的散度( ∇ . \nabla . ∇. )。 Δ f = ∇ 2 f = ∇ . ∇ f = d i v ( g r a d ( f ) ) \Delta f = \nabla^2 f = \nabla . \nabla f = div(grad(f)) Δf=∇2f=∇.∇f=div(grad(f))。
笛卡尔坐标系下的表示法:
Δ f = ∂ 2 f ∂ x 1 2 + ∂ 2 f ∂ x 2 2 + ∂ 2 f ∂ x 3 2 \Delta f = \frac{\partial^2 f}{\partial x_1^2} + \frac{\partial^2 f}{\partial x_2^2} + \frac{\partial^2 f}{\partial x_3^2} Δf=∂x12∂2f+∂x22∂2f+∂x32∂2f
n n n维时为 Δ = ∑ i ∂ 2 f ∂ x i 2 \Delta = \sum_{i} \frac{\partial^2 f}{\partial x_i^2} Δ=∑i∂xi2∂2f。
2.2离散拉普拉斯算子
在离散的情况下, ∂ f ∂ x = f ′ ( x ) = f ( x + 1 ) − f ( x ) \frac{\partial f}{ \partial x} = f^{'}(x) = f(x+1) - f(x) ∂x∂f=f′(x)=f(x+1)−f(x),
则
∂ 2 f ∂ x 2 = f ′ ′ ( x ) ≈ f ′ ( x ) − f ′ ( x − 1 ) = f ( x + 1 ) + f ( x − 1 ) − 2 f ( x ) . \begin{aligned} \frac{\partial^2 f}{\partial x^2} &= f^{''}(x) \approx f^{'}(x) - f^{'}(x-1) \\ &= f(x+1) + f(x-1) - 2f(x). \end{aligned} ∂x2∂2f=f′′(x)≈f′(x)−f′(x−1)=f(x+1)+f(x−1)−2f(x).
以二维情况为例子,见下图:
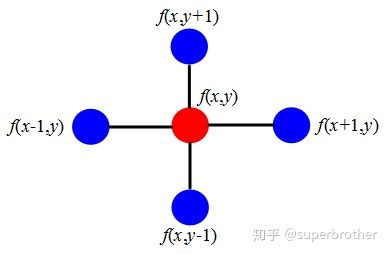
Δ f = ∂ 2 f ∂ x 2 + ∂ 2 f ∂ y 2 = ( f ( x + 1 , y ) + f ( x − 1 , y ) − 2 f ( x , y ) ) + ( f ( x , y + 1 ) + f ( x , y − 1 ) − 2 f ( x , y ) ) = f ( x + 1 , y ) + f ( x − 1 , y ) + f ( x , y + 1 ) + f ( x , y − 1 ) − 4 f ( x , y ) \begin{aligned} \Delta f &= \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2} \\ &= \left( f(x+1, y) + f(x-1, y) - 2f(x, y) \right) + \left( f(x, y+1) + f(x, y-1) - 2f(x, y) \right) \\ &= f(x+1, y) + f(x-1, y) + f(x, y+1) + f(x, y-1) - 4f(x, y) \end{aligned} Δf=∂x2∂2f+∂y2∂2f=(f(x+1,y)+f(x−1,y)−2f(x,y))+(f(x,y+1)+f(x,y−1)−2f(x,y))=f(x+1,y)+f(x−1,y)+f(x,y+1)+f(x,y−1)−4f(x,y)
现在用散度的概念解读一下:
- 如果 Δ f = 0 \Delta f = 0 Δf=0 ,可以近似认为中心点 f ( x , y ) f(x,y) f(x,y) 的势和其周围点的势是相等的, f ( x , y ) f(x,y) f(x,y)局部范围内不存在势差。所以该点无源
- Δ f > 0 \Delta f > 0 Δf>0 ,可以近似认为中心点 f ( x , y ) f(x,y) f(x,y)的势低于周围点,可以想象成中心点如恒星一样发出能量,补给周围的点,所以该点是正源
- Δ f < 0 \Delta f < 0 Δf<0 ,可以近似认为中心点 f ( x , y ) f(x,y) f(x,y)的势高于周围点,可以想象成中心点如吸引子一样在吸收能量,所以该点是负源
另一个角度,拉普拉斯算子计算了周围点与中心点的梯度差。当 f ( x , y ) f(x,y) f(x,y)受到扰动之后,其可能变为相邻的 f ( x + 1 , y ) , f ( x − 1 , y ) , f ( x , y + 1 ) , f ( x , y − 1 ) f(x+1,y),f(x-1,y),f(x,y+1),f(x,y-1) f(x+1,y),f(x−1,y),f(x,y+1),f(x,y−1)之一,拉普拉斯算子得到的是对该点进行微小扰动后可能获得的总增益 (或者说是总变化)。
2.3图上的拉普拉斯算子
现在将这个结论推广到图: 假设具有 N N N个节点的图 G G G,此时以上定义的函数 f f f不再是二维,而是 N N N维向量: f = ( f 1 , f 2 , ⋯ , f N ) f=(f_1,f_2,\cdots,f_N) f=(f1,f2,⋯,fN) ,其中 f i f_i fi为函数 f f f在图中节点 v i v_i vi处的函数值。类比于 f ( x , y ) f(x,y) f(x,y)在节点 ( x , y ) (x,y) (x,y)处的值。对 v i v_i vi节点进行扰动,它可能变为任意一个与它相邻的节点 v j ∈ N i v_j \in N_i vj∈Ni, N i N_i Ni表示节点 v i v_i vi的一阶邻域节点。
如下图:
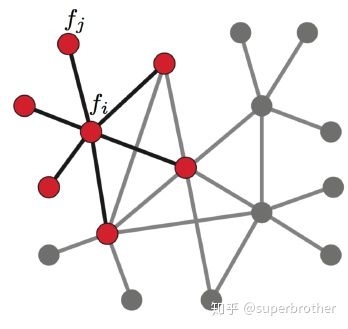
上面已经知道拉普拉斯算子可以计算一个点到它所有自由度上微小扰动的增益,则通过图来表示就是任意一个节点 v j v_j vj变化到节点 v i v_i vi所带来的增益,考虑图中边的权值相等(简单说就是1)则有:
Δ f i = ∑ v j ∈ N i ( f i − f j ) . \Delta f_i = \sum_{v_j \in N_i} (f_i - f_j). Δfi=vj∈Ni∑(fi−fj).
而如果 e i , j e_{i,j} ei,j具有权重 a i j a_{ij} aij时,则为:
Δ f i = ∑ v j ∈ N i a i j ( f i − f j ) . \Delta f_i = \sum_{v_j \in N_i} a_{ij}(f_i - f_j). Δfi=vj∈Ni∑aij(fi−fj).
上式即为 ( L f ) ( v i ) = ∑ v i ∼ v j a i , j ( f ( v i ) − f ( v j ) ) \left( \mathcal{L} f \right)(v_i) = \sum_{v_i \sim v_j} a_{i,j} \left( f(v_i) - f(v_j) \right) (Lf)(vi)=∑vi∼vjai,j(f(vi)−f(vj))。
可以看到上面的式子仅限于 v j ∈ N i v_j \in N_i vj∈Ni(或 v i ∼ v j v_i \sim v_j vi∼vj),如果令 a i j = 0 a_{ij}=0 aij=0表示节点 v i , v j v_i,v_j vi,vj不相连。则可以拓展:
Δ f i = ∑ v j ∈ V a i j ( f i − f j ) = ∑ v j ∈ V a i j f i − ∑ v j ∈ V a i j f j = ( ∑ v j ∈ V a i j ) f i − a i ⃗ f ⃗ . \begin{aligned} \Delta f_i &= \sum_{v_j \in V} a_{ij}(f_i - f_j) \\ &= \sum_{v_j \in V} a_{ij} f_i - \sum_{v_j \in V} a_{ij} f_j \\ &= \left( \sum_{v_j \in V} a_{ij} \right) f_i - \vec{a_i} \vec{f}. \end{aligned} Δfi=vj∈V∑aij(fi−fj)=vj∈V∑aijfi−vj∈V∑aijfj=⎝⎛vj∈V∑aij⎠⎞fi−aif.
记 d i = ∑ v j ∈ V a i j d_i = \sum_{v_j \in V} a_{ij} di=∑vj∈Vaij是顶点 v i v_i vi的度。
对所有的 N N N个节点有:
Δ f = ( Δ f 1 ⋮ Δ f N ) = ( d 1 f 1 − a 1 ⃗ f ⃗ ⋮ d N f N − a N ⃗ f ⃗ ) = ( d 1 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ d N ) f − ( a 1 ⃗ ⋮ a N ⃗ ) f = d i a g ( d i ) f − A f = ( D − A ) f = L f \begin{aligned} \Delta f &= \begin{pmatrix} \Delta f_1 \\ \vdots \\ \Delta f_N \end{pmatrix} =\begin{pmatrix} d_1 f_1 - \vec{a_1} \vec{f} \\ \vdots \\ d_N f_N - \vec{a_N} \vec{f} \end{pmatrix} \\ & = \begin{pmatrix} d_1 & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & d_N \end{pmatrix} f - \begin{pmatrix} \vec{a_1}\\ \vdots \\ \vec{a_N} \end{pmatrix} f \\ &= diag(d_i) f - Af \\ &= (D - A)f \\ &= Lf \end{aligned} Δf=⎝⎜⎛Δf1⋮ΔfN⎠⎟⎞=⎝⎜⎛d1f1−a1f⋮dNfN−aNf⎠⎟⎞=⎝⎜⎛d1⋮0⋯⋱⋯0⋮dN⎠⎟⎞f−⎝⎜⎛a1⋮aN⎠⎟⎞f=diag(di)f−Af=(D−A)f=Lf
2.4拉普拉斯算子与拉普拉斯矩阵的关系
再次考虑二维情况,离散化的拉普拉斯算子得到的
Δ f = f ( x + 1 , y ) + f ( x − 1 , y ) + f ( x , y + 1 ) + f ( x , y − 1 ) − 4 f ( x , y ) \Delta f = f(x+1, y) + f(x-1, y) + f(x, y+1) + f(x, y-1) - 4f(x, y) Δf=f(x+1,y)+f(x−1,y)+f(x,y+1)+f(x,y−1)−4f(x,y)
与图上拉普拉斯矩阵得到的[14]
( L f ) ( x , y ) = 4 f ( x , y ) − ( f ( x + 1 , y ) + f ( x − 1 , y ) + f ( x , y + 1 ) + f ( x , y − 1 ) ) \left( \mathcal{L} f \right)(x,y) = 4f(x, y) - \left( f(x+1, y) + f(x-1, y) + f(x, y+1) + f(x, y-1) \right) (Lf)(x,y)=4f(x,y)−(f(x+1,y)+f(x−1,y)+f(x,y+1)+f(x,y−1))
两者只相差一个符号。
3.傅里叶变换
3.1傅里叶变换简要推导[15]
用 e j π x L i e^{\frac{j \pi x}{L}i} eLjπxi作基, c j c_j cj作因子,表示函数 f ( x ) f(x) f(x):
f ( x ) = ∑ j = − ∞ ∞ c j e j π x L i . f(x) = \sum_{j=-\infty}^{\infty} c_j e^{\frac{j \pi x}{L}i}. f(x)=j=−∞∑∞cjeLjπxi.
其中的因子 c j c_j cj为:
c j = 1 2 L ∫ − L L f ( t ) e − j π t L i d t , − ∞ < j < ∞ . c_j = \frac{1}{2L} \int_{-L}^{L} f(t) e^{-\frac{j \pi t}{L}i} dt, \qquad -\infty < j <\infty. cj=2L1∫−LLf(t)e−Ljπtidt,−∞<j<∞.
将因子代入有:
f ( x ) = ∑ j = − ∞ ∞ [ 1 2 L ∫ − L L f ( t ) e − j π t L i d t ] e j π x L i . f(x) = \sum_{j=-\infty}^{\infty} \left[ \frac{1}{2L} \int_{-L}^{L} f(t) e^{-\frac{j \pi t}{L}i} dt \right] e^{\frac{j \pi x}{L}i}. f(x)=j=−∞∑∞[2L1∫−LLf(t)e−Ljπtidt]eLjπxi.
令 ξ j = π j L , Δ ξ = π L \xi_j = \frac{\pi j}{L}, \Delta \xi = \frac{\pi}{L} ξj=Lπj,Δξ=Lπ,上面二式改写成:
F L ( ξ ) = 1 2 π ∫ − L L f ( t ) e − i ξ t d t f ( x ) = ∑ j = − ∞ ∞ F L ( ξ j ) e i ξ t Δ ξ . \begin{aligned} F_{L}(\xi) &= \frac{1}{2\pi} \int_{-L}^{L} f(t) e^{-i \xi t} dt \\ f(x) &= \sum_{j=-\infty}^{\infty} F_{L}(\xi_j) e^{i \xi t} \Delta \xi. \end{aligned} FL(ξ)f(x)=2π1∫−LLf(t)e−iξtdt=j=−∞∑∞FL(ξj)eiξtΔξ.
令 L → ∞ L \rightarrow \infty L→∞,将黎曼和转为积分则:
f ( x ) = ∫ j = − ∞ ∞ [ 1 2 π ∫ − ∞ ∞ f ( t ) e − i ξ t d t ] e i ξ t d ξ . = 1 2 π ∫ j = − ∞ ∞ [ 1 2 π ∫ − ∞ ∞ f ( t ) e − i ξ t d t ] e i ξ t d ξ . \begin{aligned} f(x) &= \int_{j=-\infty}^{\infty} \left[ \frac{1}{2\pi} \int_{-\infty}^{\infty} f(t) e^{-i \xi t} dt \right] e^{i \xi t} d \xi. \\ &= \frac{1}{\sqrt{2 \pi}} \int_{j=-\infty}^{\infty} \left[ \frac{1}{\sqrt{2 \pi}} \int_{-\infty}^{\infty} f(t) e^{-i \xi t} dt \right] e^{i \xi t} d \xi. \end{aligned} f(x)=∫j=−∞∞[2π1∫−∞∞f(t)e−iξtdt]eiξtdξ.=2π1∫j=−∞∞[2π1∫−∞∞f(t)e−iξtdt]eiξtdξ.
得到傅里叶变换及其逆变换:
f ^ ( ξ ) = 1 2 π ∫ − ∞ ∞ f ( t ) e − i ξ t d t f ( x ) = 1 2 π ∫ j = − ∞ ∞ f ^ ( ξ ) e i ξ t d ξ . \begin{aligned} \hat{f}(\xi) &= \frac{1}{\sqrt{2 \pi}} \int_{-\infty}^{\infty} f(t) e^{-i \xi t} dt\\ f(x) &= \frac{1}{\sqrt{2 \pi}} \int_{j=-\infty}^{\infty} \hat{f}(\xi) e^{i \xi t} d \xi. \end{aligned} f^(ξ)f(x)=2π1∫−∞∞f(t)e−iξtdt=2π1∫j=−∞∞f^(ξ)eiξtdξ.
3.2离散傅里叶变换[15]
在连续的情况中,因子 c j c_j cj为:
c j = 1 2 π ∫ 0 2 π f ( t ) e − i j x d t , − ∞ < j < ∞ . c_j = \frac{1}{2 \pi} \int_{0}^{2 \pi} f(t) e^{-ijx} dt, \qquad -\infty < j <\infty. cj=2π1∫02πf(t)e−ijxdt,−∞<j<∞.
将其离散化:
c j ≈ 1 n ∑ k = 0 n − 1 f ( x k ) e i j x k . c_j \approx \frac{1}{n} \sum_{k=0}^{n-1} f(x_k) e^{ijx_k}. cj≈n1k=0∑n−1f(xk)eijxk.
类比,得到离散的傅里叶变换:
y ^ k = ∑ j = 0 n − 1 w n − k j y j , 0 ≤ k ≤ n − 1 , \hat{y}_k = \sum_{j=0}^{n-1} w_{n}^{-kj} y_j,\qquad 0 \leq k \leq n-1, y^k=j=0∑n−1wn−kjyj,0≤k≤n−1,
其中 w n = e 2 π i n w_n = e^{\frac{2 \pi i}{n}} wn=en2πi。
将其写成矩阵形式:
( y ^ 0 y ^ 1 y ^ 2 ⋮ y ^ n − 1 ) = ( 1 1 1 ⋯ 1 1 w n − 1 w n − 2 ⋯ w n − ( n − 1 ) 1 w n − 2 w n − 4 ⋯ w n − 2 ( n − 1 ) ⋮ ⋮ ⋮ ⋱ ⋮ 1 w n − ( n − 1 ) ) w n − ( n − 1 ) ⋯ w n − ( n − 1 ) 2 ) ( y 0 y 1 y 2 ⋮ y n − 1 ) . \begin{pmatrix} \hat{y}_0 \\ \hat{y}_1 \\ \hat{y}_2 \\ \vdots \\ \hat{y}_{n-1} \\ \end{pmatrix} =\begin{pmatrix} 1 & 1 & 1 & \cdots & 1 \\ 1 & w_{n}^{-1} & w_{n}^{-2} & \cdots & w_{n}^{-(n-1)} \\ 1 & w_{n}^{-2} & w_{n}^{-4} & \cdots & w_{n}^{-2(n-1)} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & w_{n}^{-(n-1))} & w_{n}^{-(n-1)} & \cdots & w_{n}^{-(n-1)^2} \\ \end{pmatrix} \begin{pmatrix} y_0 \\ y_1 \\ y_2 \\ \vdots \\ y_{n-1} \\ \end{pmatrix}. ⎝⎜⎜⎜⎜⎜⎛y^0y^1y^2⋮y^n−1⎠⎟⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎜⎜⎛111⋮11wn−1wn−2⋮wn−(n−1))1wn−2wn−4⋮wn−(n−1)⋯⋯⋯⋱⋯1wn−(n−1)wn−2(n−1)⋮wn−(n−1)2⎠⎟⎟⎟⎟⎟⎟⎞⎝⎜⎜⎜⎜⎜⎛y0y1y2⋮yn−1⎠⎟⎟⎟⎟⎟⎞.
记
F n = ( 1 1 1 ⋯ 1 1 w n 1 w n 2 ⋯ w n ( n − 1 ) 1 w n 2 w n 4 ⋯ w n 2 ( n − 1 ) ⋮ ⋮ ⋮ ⋱ ⋮ 1 w n ( n − 1 ) ) w n ( n − 1 ) ⋯ w n ( n − 1 ) 2 ) . F_n = \begin{pmatrix} 1 & 1 & 1 & \cdots & 1 \\ 1 & w_{n}^{1} & w_{n}^{2} & \cdots & w_{n}^{(n-1)} \\ 1 & w_{n}^{2} & w_{n}^{4} & \cdots & w_{n}^{2(n-1)} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & w_{n}^{(n-1))} & w_{n}^{(n-1)} & \cdots & w_{n}^{(n-1)^2} \\ \end{pmatrix}. Fn=⎝⎜⎜⎜⎜⎜⎜⎛111⋮11wn1wn2⋮wn(n−1))1wn2wn4⋮wn(n−1)⋯⋯⋯⋱⋯1wn(n−1)wn2(n−1)⋮wn(n−1)2⎠⎟⎟⎟⎟⎟⎟⎞.
即离散傅里叶变换为:
y ^ ⃗ = F n ˉ y ⃗ . \vec{\hat{y}} = \bar{F_n} \vec{y}. y^=Fnˉy.
根据
( F n ˉ ) − 1 = 1 n F n , (\bar{F_n})^{-1} = \frac{1}{n} F_n, (Fnˉ)−1=n1Fn,
得到逆离散傅里叶变换为:
y ⃗ = 1 n F n y ^ ⃗ . \vec{y} = \frac{1}{n} F_n \vec{\hat{y}}. y=n1Fny^.
3.3图上傅里叶变换
在傅里叶变换中,使用的基函数 e − i w t e^{-iwt} e−iwt是因为它是拉普拉斯算子的特征函数(满足特征方程), w w w就和特征值有关。
广义的特征方程定义为:
A V = λ V AV = \lambda V AV=λV
其中 A A A是一种变换, V V V是特征向量或者特征函数(无穷维的向量), λ \lambda λ是特征值。
e − i w t e^{-iwt} e−iwt满足:
Δ e − i w t = ∂ 2 ∂ 2 t e − i w t = − w 2 e − i w t . \Delta e^{-iwt} = \frac{\partial^2}{\partial^2 t} e^{-iwt} = -w^2 e^{-iwt}. Δe−iwt=∂2t∂2e−iwt=−w2e−iwt.
当然 e − i w t e^{-iwt} e−iwt就是变换 Δ \Delta Δ的特征函数, w w w和特征值密切相关。
L L L是拉普拉斯矩阵, V V V是其特征向量,自然满足下式:
L V = λ V . LV = \lambda V. LV=λV.
由此得到图上的傅里叶变换:
F [ f ( λ l ) ] = f ^ ( λ l ) = < f , u ⃗ l > = ∑ v i ∈ V f ( v i ) u l ∗ ( v i ) \mathcal{F}[f(\lambda_l)] = \hat{f}(\lambda_l) = \left< f, \vec{u}_l \right>= \sum_{v_i \in V} f(v_i) u_l^{*}(v_i) F[f(λl)]=f^(λl)=⟨f,ul⟩=vi∈V∑f(vi)ul∗(vi)
矩阵形式为:
图上傅里叶变换: f ^ = U T f 图上逆傅里叶变换: f = U f ^ \begin{aligned} &\text{图上傅里叶变换: } &\hat{f} = U^T f \\ &\text{图上逆傅里叶变换: } &f = U \hat{f} \end{aligned} 图上傅里叶变换: 图上逆傅里叶变换: f^=UTff=Uf^
3.4为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?特征值表示频率?
3.4.1为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?
傅里叶变换一个本质理解就是:把任意一个函数表示成了若干个正交函数(由sin,cos 构成)的线性组合。
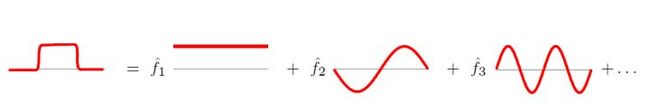
图上傅里叶变换也把图上定义的任意向量 f ⃗ \vec{f} f,表示成了拉普拉斯矩阵特征向量的线性组合,即:
f ⃗ = ∑ i = 0 n − 1 f ^ ( λ 0 ) u ⃗ 0 . \vec{f} = \sum_{i=0}^{n-1}\hat{f}(\lambda_0) \vec{u}_0. f=i=0∑n−1f^(λ0)u0.
为什么graph上任意的向量 f ⃗ \vec{f} f都可以表示成这样的线性组合?
原因是, u ⃗ 0 , u ⃗ 1 , ⋯ , u ⃗ n − 1 \vec{u}_0,\vec{u}_1,\cdots, \vec{u}_{n-1} u0,u1,⋯,un−1是图上 n n n维空间中的 n n n个线性无关的正交向量。
3.4.2怎么理解拉普拉斯矩阵的特征值表示频率?
在图空间上无法可视化展示“频率”这个概念,那么从特征方程上来抽象理解。
因为 L 1 n × 1 = 0 ⃗ n × 1 L \mathbb{1}_{n \times 1} = \vec{0}_{n \times 1} L1n×1=0n×1可知 L L L的最小特征值 λ 0 = 0 \lambda_0 = 0 λ0=0。
从特征方程的数学理解来看:
L u ⃗ = λ u ⃗ . L \vec{u} = \lambda \vec{u}. Lu=λu.
在由图确定的 n n n维空间中,越小的特征值 λ l \lambda_l λl表明:拉普拉斯矩阵 L L L其所对应的基 u ⃗ l \vec{u}_l ul上的分量、“信息”越少,那么当然就是可以忽略的低频部分了。
其实图像压缩就是这个原理,把像素矩阵特征分解后,把小的特征值(低频部分)全部变成0,PCA降维也是同样的,把协方差矩阵特征分解后,按从大到小取出前K个特征值对应的特征向量作为新的“坐标轴”。
4.GCN卷积
4.1图上卷积
卷积定理[7] :
F [ f 1 ( t ) ⋆ f 2 ( t ) ] = F [ f 1 ( t ) ] ⊙ F [ f 2 ( t ) ] \mathcal{F} \left[ f_1(t) \star f_2(t) \right] = \mathcal{F} \left[ f_1(t)\right] \odot \mathcal{F} \left[ f_2(t)\right] F[f1(t)⋆f2(t)]=F[f1(t)]⊙F[f2(t)]
其中 ⋆ \star ⋆为卷积运算符, ⊙ \odot ⊙表示Hadamard product(哈达马积),对于两个维度相同的向量、矩阵、张量进行对应位置的逐元素乘积运算。
卷积定理将卷积与傅里叶变换联系起来。由此我们得到了图上的卷积:
( f ⋆ h ) G = U [ ( U T h ) ⊙ ( U T f ) ] . \left( f \star h\right)_G = U \left[ \left(U^T h\right) \odot \left(U^T f\right) \right]. (f⋆h)G=U[(UTh)⊙(UTf)].
这里为了后续说明问题的方便,不再使用 ⊙ \odot ⊙。两向量 U T h , U T f U^T h, U^T f UTh,UTf做逐点乘积,等价于把其中一个向量对角化做矩阵乘积:
( U T h ) ⊙ ( U T f ) = ( h ^ ( λ 0 ) h ^ ( λ 1 ) ⋮ h ^ ( λ n − 1 ) ) ⊙ ( f ^ ( λ 0 ) f ^ ( λ 1 ) ⋮ f ^ ( λ n − 1 ) ) = ( h ^ ( λ 0 ) h ^ ( λ 1 ) ⋱ h ^ ( λ n − 1 ) ) ( f ^ ( λ 0 ) f ^ ( λ 1 ) ⋮ f ^ ( λ n − 1 ) ) = d i a g ( h ^ ( λ l ) ) U T f . \begin{aligned} \left(U^T h\right) \odot \left(U^T f\right) &= \begin{pmatrix} \hat{h}(\lambda_0) \\ \hat{h}(\lambda_1) \\ \vdots \\ \hat{h}(\lambda_{n-1}) \end{pmatrix} \odot \begin{pmatrix} \hat{f}(\lambda_0) \\ \hat{f}(\lambda_1) \\ \vdots \\ \hat{f}(\lambda_{n-1}) \end{pmatrix} \\ &= \begin{pmatrix} \hat{h}(\lambda_0) \\ & \hat{h}(\lambda_1) & & \\ & & \ddots & \\ & & & \hat{h}(\lambda_{n-1}) \end{pmatrix} \begin{pmatrix} \hat{f}(\lambda_0) \\ \hat{f}(\lambda_1) \\ \vdots \\ \hat{f}(\lambda_{n-1}) \end{pmatrix}\\ &= diag(\hat{h}(\lambda_l) ) U^T f. \end{aligned} (UTh)⊙(UTf)=⎝⎜⎜⎜⎛h^(λ0)h^(λ1)⋮h^(λn−1)⎠⎟⎟⎟⎞⊙⎝⎜⎜⎜⎛f^(λ0)f^(λ1)⋮f^(λn−1)⎠⎟⎟⎟⎞=⎝⎜⎜⎛h^(λ0)h^(λ1)⋱h^(λn−1)⎠⎟⎟⎞⎝⎜⎜⎜⎛f^(λ0)f^(λ1)⋮f^(λn−1)⎠⎟⎟⎟⎞=diag(h^(λl))UTf.
因此用矩阵形式:
( f ⋆ h ) G = U ( h ^ ( λ 0 ) h ^ ( λ 1 ) ⋱ h ^ ( λ n − 1 ) ) U T f = U d i a g ( h ^ ( λ l ) ) U T f . \left( f \star h\right)_G = U \begin{pmatrix} \hat{h}(\lambda_0) \\ & \hat{h}(\lambda_1) & & \\ & & \ddots & \\ & & & \hat{h}(\lambda_{n-1}) \\ \end{pmatrix} U^T f = U diag(\hat{h}(\lambda_l)) U^T f. (f⋆h)G=U⎝⎜⎜⎛h^(λ0)h^(λ1)⋱h^(λn−1)⎠⎟⎟⎞UTf=Udiag(h^(λl))UTf.
4.2第一代GCN
Spectral Networks and Locally Connected Networks on Graphs中简单粗暴地把 d i a g ( h ^ ( λ l ) ) diag(\hat{h}(\lambda_l)) diag(h^(λl))变成卷积核 d i a g ( θ l ) diag(\theta_l) diag(θl),即:
y o u t = σ ( U g θ ( Λ ) U T x i n ) . y_{out} = \sigma \left( U g_{\theta}(\Lambda) U^T x_{in}\right). yout=σ(Ugθ(Λ)UTxin).
其中 σ ( . ) \sigma(.) σ(.)是激活函数,卷积核 g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ)为
g θ ( Λ ) = ( θ 0 ⋱ θ n − 1 ) . g_{\theta}(\Lambda) = \begin{pmatrix} \theta_0 \\ & \ddots \\ & & \theta_{n-1} \end{pmatrix}. gθ(Λ)=⎝⎛θ0⋱θn−1⎠⎞.
第一代的参数方法存在着一些弊端:主要在于:
- 每次前向传播需要计算 U , d i a g ( θ l ) , U T U,diag(\theta_l), U^T U,diag(θl),UT三者的矩阵乘积,计算复杂度为 O ( n 2 ) \mathcal{O}(n^2) O(n2)。
- 卷积核不具有spatial localization。
- 卷积核需要 n n n个参数。
4.3第二代GCN
Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering把 h ^ ( λ l ) \hat{h}(\lambda_l) h^(λl)巧妙地设计成了 ∑ j = 0 K α j λ l j \sum_{j=0}^{K} \alpha_j \lambda_{l}^{j} ∑j=0Kαjλlj,即:
g θ ( Λ ) = ( ∑ j = 0 K α j λ 0 j ⋱ ∑ j = 0 K α j λ n − l j ) = ∑ j = 0 K [ α j ( λ 0 j ⋱ λ n − l j ) ] = ∑ j = 0 K α j Λ j . \begin{aligned} g_{\theta}(\Lambda) &= \begin{pmatrix} \sum_{j=0}^{K} \alpha_j \lambda_{0}^{j} \\ & \ddots \\ & & \sum_{j=0}^{K} \alpha_j \lambda_{n-l}^{j} \end{pmatrix} \\ &= \sum_{j=0}^{K} \left[ \alpha_j \begin{pmatrix} \lambda_{0}^{j} \\ & \ddots \\ & & \lambda_{n-l}^{j} \end{pmatrix} \right] \\ &= \sum_{j=0}^{K} \alpha_j \Lambda^{j}. \end{aligned} gθ(Λ)=⎝⎜⎛∑j=0Kαjλ0j⋱∑j=0Kαjλn−lj⎠⎟⎞=j=0∑K⎣⎡αj⎝⎛λ0j⋱λn−lj⎠⎞⎦⎤=j=0∑KαjΛj.
利用拉普拉斯矩阵特征值分解的性质 L 2 = U Λ U T U Λ U T = U Λ 2 U T L^2 = U \Lambda U^T U \Lambda U^T = U \Lambda^2 U^T L2=UΛUTUΛUT=UΛ2UT,进而有:
U g θ ( Λ ) U T = U ( ∑ j = 0 K α j Λ j ) U T = ∑ j = 0 K ( α j U Λ j U T ) = ∑ j = 0 K α j L j . \begin{aligned} U g_{\theta}(\Lambda) U^T &= U \left( \sum_{j=0}^{K} \alpha_j \Lambda^{j} \right) U^T \\ & = \sum_{j=0}^{K} \left( \alpha_j U \Lambda^{j} U^T \right)\\ & = \sum_{j=0}^{K} \alpha_j L^{j}. \end{aligned} Ugθ(Λ)UT=U(j=0∑KαjΛj)UT=j=0∑K(αjUΛjUT)=j=0∑KαjLj.
卷积层为:
y o u t = σ ( U g θ ( Λ ) U T x i n ) = σ ( ∑ j = 0 K α j L j x i n ) . y_{out} = \sigma \left( U g_{\theta}(\Lambda) U^T x_{in}\right) = \sigma \left( \sum_{j=0}^{K} \alpha_j L^{j} x_{in}\right). yout=σ(Ugθ(Λ)UTxin)=σ(j=0∑KαjLjxin).
第二代卷积核其优点在于在于:
- 卷积核只需要 K K K个参数 ( α 0 , α 1 , ⋯ , α n − 1 ) (\alpha_0, \alpha_1, \cdots, \alpha_{n-1}) (α0,α1,⋯,αn−1),一般 K K K远小于 n n n。
- 不需要再做特征值分解了。计算机复杂仍然是 O ( n 2 ) \mathcal{O}(n^2) O(n2)。
- 卷积核具有很好的spatial localization。特别地, K K K就是卷积核的receptive field,也就是说每次卷积会将中心顶点K-hop neighbor上的feature进行加权求和,权系数就是 α k \alpha_k αk。
4.4利用Chebyshev多项式作为卷积核[12]
4.4.1Chebyshev多项式性质
- 递归定义 T k ( y ) = 2 y T k − 1 ( y ) − T k − 2 ( y ) T_k(y) = 2yT_{k-1}(y) - T_{k-2}(y) Tk(y)=2yTk−1(y)−Tk−2(y)
- T 0 = 1 , t 1 = y T_0=1,t_1=y T0=1,t1=y
- y ∈ [ − 1 , 1 ] y\in[-1,1] y∈[−1,1]
- T k ( y ) = cos ( k arccos ( y ) ) T_k(y) = \cos \left( k \arccos (y) \right) Tk(y)=cos(karccos(y))
∫ − 1 1 T l ( y ) T m ( y ) 1 − y 2 d y = { π 2 δ l . m if m , l > 0 π if m = l = 0. \int_{-1}^{1} \frac{T_l(y) T_m(y)}{\sqrt{1-y^2}} dy = \begin{cases} \frac{\pi}{2} \delta_{l.m} \qquad &\text{if } m,l >0 \\ \pi \qquad &\text{if } m=l=0. \end{cases} ∫−111−y2Tl(y)Tm(y)dy={2πδl.mπif m,l>0if m=l=0.
Every h ∈ L 2 ( [ − 1 , 1 ] , d y 1 − y 2 ) h \in L^2([-1,1],\frac{dy}{\sqrt{1-y^2}}) h∈L2([−1,1],1−y2dy) has a convergent (in L 2 L^2 L2 norm) Chebyshev series
h ( y ) = 1 2 c 0 + ∑ k = 1 ∞ c k T k ( y ) h(y) = \frac{1}{2} c_0 + \sum_{k=1}^{\infty} c_k T_k (y) h(y)=21c0+k=1∑∞ckTk(y)
with Chebyshev coefficients
c k = 2 π ∫ − 1 1 T l ( y ) T m ( y ) 1 − y 2 d y = 2 π ∫ 0 π cos ( k θ ) h ( cos ( θ ) ) d θ . c_k = \frac{2}{\pi} \int_{-1}^{1} \frac{T_l(y) T_m(y)}{\sqrt{1-y^2}} dy = \frac{2}{\pi} \int_{0}^{\pi} \cos(k\theta)h(\cos(\theta)) d \theta. ck=π2∫−111−y2Tl(y)Tm(y)dy=π2∫0πcos(kθ)h(cos(θ))dθ.
4.4.2 Chebyshev多项式卷积核
将 g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ)用Chebyshev多项式 T k ( x ) T_{k}(x) Tk(x)逼近:
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( Λ ~ ) , Λ ~ = 2 λ m a x ( Λ ) Λ − I n g_{\theta^{'}}(\Lambda) \approx \sum_{k=0}^{K} \theta_{k}^{'} T_{k}( \tilde{\Lambda} ), \qquad \tilde{\Lambda} = \frac{2}{\lambda_{max}(\Lambda)} \Lambda - I_n gθ′(Λ)≈k=0∑Kθk′Tk(Λ~),Λ~=λmax(Λ)2Λ−In
由 T k ( y ) = cos ( k arccos ( y ) ) T_k(y) = \cos \left( k \arccos (y) \right) Tk(y)=cos(karccos(y))可以知道Chebyshev多项式的输入必须是在 [ − 1 , 1 ] [-1,1] [−1,1]之间,所以需要将 Λ \Lambda Λ做变换为 Λ ~ \tilde{\Lambda} Λ~。
因此得到Chebyshev多项式逼近图上谱卷积为:
g θ ′ ⋆ x ≈ U ( ∑ k = 0 K θ k ′ T k ( Λ ~ ) ) U T x = ∑ k = 0 K ( U θ k ′ T k ( Λ ~ ) U T ) x = ∑ k = 0 K θ k ′ T k ( U Λ ~ U T ) ) x = ∑ k = 0 K θ k ′ T k ( L ~ ) x \begin{aligned} g_{\theta^{'}} \star x & \approx U \left( \sum_{k=0}^{K} \theta_{k}^{'} T_{k}( \tilde{\Lambda} ) \right) U^T x \\ & = \sum_{k=0}^{K} \left( U \theta_{k}^{'} T_{k}( \tilde{\Lambda} ) U^T \right) x \\ & = \sum_{k=0}^{K} \theta_{k}^{'} T_{k}\left( U \tilde{\Lambda} U^T \right) ) x \\ & = \sum_{k=0}^{K} \theta_{k}^{'} T_{k}(\tilde{L}) x \end{aligned} gθ′⋆x≈U(k=0∑Kθk′Tk(Λ~))UTx=k=0∑K(Uθk′Tk(Λ~)UT)x=k=0∑Kθk′Tk(UΛ~UT))x=k=0∑Kθk′Tk(L~)x
其中 L ~ = 2 λ m a x ( L ) L − I N \tilde{L} = \frac{2}{\lambda_{max}(L)} L - I_N L~=λmax(L)2L−IN。
4.5 Chebyshev多项式逼近法简化[9,10]
如果取 λ m a x ≈ 2 \lambda_{max} \approx 2 λmax≈2则有 L ~ = L − I N \tilde{L} = L - I_N L~=L−IN。Chebyshev多项式只取前两项,即 K = 1 K = 1 K=1 有
g θ ′ ⋆ x ≈ ( θ 0 ′ + θ 1 ′ ( L − I N ) ) x = ( θ 0 ′ − θ 1 ′ D − 1 2 A D − 1 2 ) x . \begin{aligned} g_{\theta^{'}} \star x & \approx \left( \theta_{0}^{'} + \theta_{1}^{'} (L - I_N) \right) x \\ & = \left( \theta_{0}^{'} - \theta_{1}^{'} D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \right) x \end{aligned}. gθ′⋆x≈(θ0′+θ1′(L−IN))x=(θ0′−θ1′D−21AD−21)x.
4.6 单参数法[9,10]
令参数 θ 0 ′ = − θ 1 ′ = θ \theta_{0}^{'} = - \theta_{1}^{'} = \theta θ0′=−θ1′=θ,图上谱卷积又可以简化为
g θ ′ ⋆ x ≈ θ ( I N + D − 1 2 A D − 1 2 ) x g_{\theta^{'}} \star x \approx \theta \left( I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \right) x gθ′⋆x≈θ(IN+D−21AD−21)x
注意 I N + D − 1 2 A D − 1 2 I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} IN+D−21AD−21拥有范围为 [ 0 , 2 ] [0,2] [0,2]的特征值,这将会导致数值不稳定性和梯度爆炸/消失。因此我们介绍下面的归一化技巧(renormalization trick):
I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 . I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \rightarrow \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}. IN+D−21AD−21→D~−21A~D~−21.
其中 A ~ = A + I N , D ~ i , i = ∑ j A ~ i , j = ∑ j ( A i , j + ( I N ) i , j ) = D i , i + 1 \tilde{A}=A+I_N,\tilde{D}_{i,i} = \sum_{j}\tilde{A}_{i,j} = \sum_{j} \left( A_{i,j} + (I_N)_{i,j}\right) = D_{i,i} + 1 A~=A+IN,D~i,i=∑jA~i,j=∑j(Ai,j+(IN)i,j)=Di,i+1。上式展开为
I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 = ( D + I N ) − 1 2 ( A + I N ) ( D + I N ) − 1 2 = ( D + I N ) − 1 2 A ( D + I N ) − 1 2 + ( D + I N ) − 1 . \begin{aligned} I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} & \rightarrow \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} \\ & = (D + I_N)^{-\frac{1}{2}} (A+I_N) (D + I_N)^{-\frac{1}{2}} \\ & = (D + I_N)^{-\frac{1}{2}} A (D + I_N)^{-\frac{1}{2}} + (D + I_N)^{-1} \end{aligned}. IN+D−21AD−21→D~−21A~D~−21=(D+IN)−21(A+IN)(D+IN)−21=(D+IN)−21A(D+IN)−21+(D+IN)−1.
输入 X ∈ R N × C X \in \mathbb{R}^{N \times C} X∈RN×C, C C C为输入的通道数,经过滤波 Θ ∈ R C × F \Theta \in \mathbb{R}^{C \times F} Θ∈RC×F得到含有 F F F个通道的卷积后结果 Z ∈ R N × F Z \in \mathbb{R}^{N \times F} Z∈RN×F:
Z = D ~ − 1 2 A ~ D ~ − 1 2 X Θ Z = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} X \Theta Z=D~−21A~D~−21XΘ
参考文献
- [1] 从CNN到GCN的联系与区别——GCN从入门到精(fang)通(qi)
- [2] Chebyshev多项式作为GCN卷积核
- [3] 解读三种经典GCN中的Parameter Sharing
- [4] 【其实贼简单】拉普拉斯算子和拉普拉斯矩阵
- [5] 拉普拉斯矩阵与拉普拉斯算子的关系
- [6] 图卷积神经网络(GCN)详解:包括了数学基础(傅里叶,拉普拉斯)
- [7] 卷积定理
- [8] M矩阵
- [9] 【GCN】论文笔记:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
- [10] 机器学习论文笔记-Semi-Supervised Classification with Graph Convolutional Networks
- [11] Spectral Networks and Locally Connected Networks on Graphs
- [12] Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
- [13] The Emerging Field of Signal Processing on Graphs
- [14] Wavelets on graphs via spectral graph theory
- [15] Weimin HanKendall,E. Atkinson.Theoretical Numerical Analysis A Functional Analysis Framework Third Edition[M].Springer:New York,2009:167.