图卷积神经网络GCN---池化层代表作
GNN Pooling
文章目录
- GNN Pooling
- 1 Deep Convolutional Networks on Graph-Structured Data
- 2 Convolutional neural networks on graphs with fast localized spectral filtering
- 3 An End-to-End Deep Learning Architecture for Graph Classification
- 4 Hierarchical Graph Representation Learning with Differentiable Pooling
- 5 Graph U-Nets
- 6 Self-Attention Graph Pooling
- 参考文献
1 Deep Convolutional Networks on Graph-Structured Data
[Henaff M, 2015, 1] 提出通过层次图聚类的方式达到池化的效果。
2 Convolutional neural networks on graphs with fast localized spectral filtering
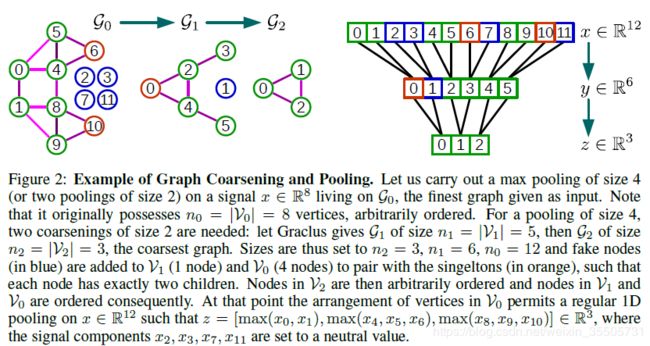
[Defferrard M, 2016, 2] 提出了将顶点构成一颗完全二叉树,不足部分补充虚拟顶点(类似于填充padding),经行分层池化。见下图。
3 An End-to-End Deep Learning Architecture for Graph Classification
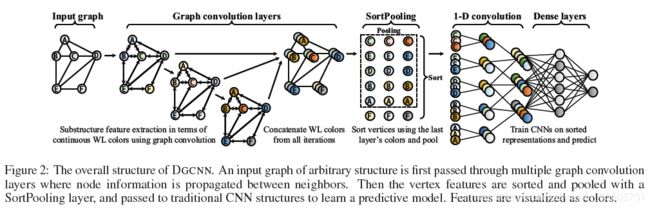
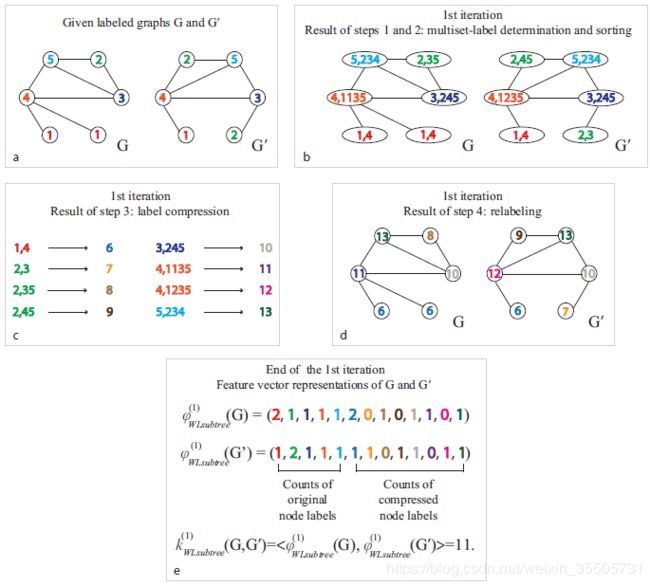
[Zhang M, 2018, 3] 提出了一种SortPooling的方法。简单地来说就是,使用WL算法[7]对顶点着色(赋值),在对顶点排序,截取部分得到池化的效果。
4 Hierarchical Graph Representation Learning with Differentiable Pooling
[Ying R, 2018, 4] 提出的池化方法可以微分可以学习。主要思想是通过GCN同时生成嵌入矩阵 Z ( l ) Z^{(l)} Z(l)和assignment matrix(分配矩阵) S ( l ) S^{(l)} S(l):
Z ( l ) = GNN l , embed ( A ( l ) , X ( l ) ) , S ( l ) = GNN l , pool ( A ( l ) , X ( l ) ) . (4.1) \begin{aligned} Z^{(l)} &= \text{GNN}_{l,\text{embed}} \left( A^{(l)}, X^{(l)} \right),\\ S^{(l)} &= \text{GNN}_{l,\text{pool}} \left( A^{(l)}, X^{(l)} \right). \end{aligned} \tag{4.1} Z(l)S(l)=GNNl,embed(A(l),X(l)),=GNNl,pool(A(l),X(l)).(4.1)
再利用嵌入矩阵 Z ( l ) Z^{(l)} Z(l)和assignment matrix(分配矩阵) S ( l ) S^{(l)} S(l)生成新的图,新的特征矩阵和邻接矩阵为:
X ( l + 1 ) = S ( l ) T Z ( l ) ∈ R n l + 1 × d , A ( l + 1 ) = S ( l ) T A ( l ) S ( l ) ∈ R n l + 1 × n l + 1 . (4.2) \begin{aligned} X^{(l+1)} &= {S^{(l)}}^{T} Z^{(l)} \in \reals^{n_{l+1} \times d}, \\ A^{(l+1)} &= {S^{(l)}}^{T} A^{(l)} S^{(l)} \in \reals^{n_{l+1} \times n_{l+1}}. \end{aligned} \tag{4.2} X(l+1)A(l+1)=S(l)TZ(l)∈Rnl+1×d,=S(l)TA(l)S(l)∈Rnl+1×nl+1.(4.2)
5 Graph U-Nets
[Gao H, 2019, 5] 提出了图数据上的U-net,其中的gPooling方法,对于第 l l l层:
- 使用可学习的投影向量 p ⃗ \vec{p} p对 X l X^l Xl投影: y ⃗ = X l p ⃗ l ∥ p ⃗ l ∥ \vec{y}=\frac{X^l \vec{p}^l }{\| \vec{p}^l \|} y=∥pl∥Xlpl;
- 截取前 k k k个索引: idx = rank ( y ⃗ , k ) \text{idx} = \text{rank}(\vec{y},k) idx=rank(y,k);
- 对保留部分激活投影 y ⃗ \vec{y} y: y ⃗ ~ = tanh ( y ⃗ ( idx ) ) \tilde{\vec{y}} = \tanh(\vec{y}(\text{idx})) y~=tanh(y(idx));
- 根据索引idx截取 X l X^l Xl: X ~ l = X l ( idx , : ) \tilde{X}^l = X^l (\text{idx},:) X~l=Xl(idx,:);
- 对保留下来顶点获得新的邻接矩阵: A l + 1 = A l ( idx , idx ) A^{l+1} = A^l (\text{idx}, \text{idx}) Al+1=Al(idx,idx);
- 对保留下来的顶点生成新的特征矩阵: X l + 1 = X ~ l ⊙ ( y ⃗ ~ 1 ⃗ C T ) X^{l+1} = \tilde{X}^l \odot \left( \tilde{\vec{y}} \vec{1}_C^T \right) Xl+1=X~l⊙(y~1CT)。
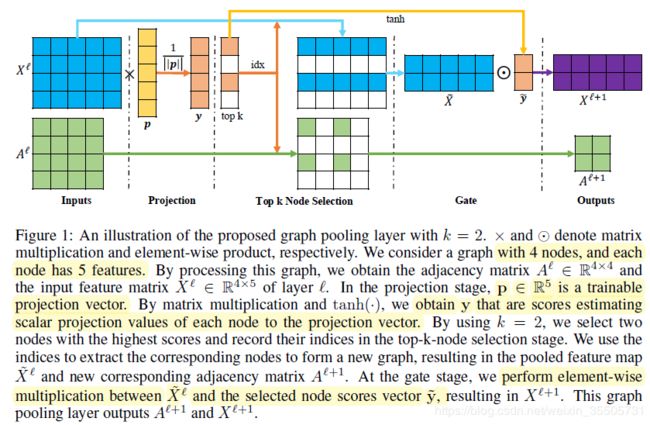
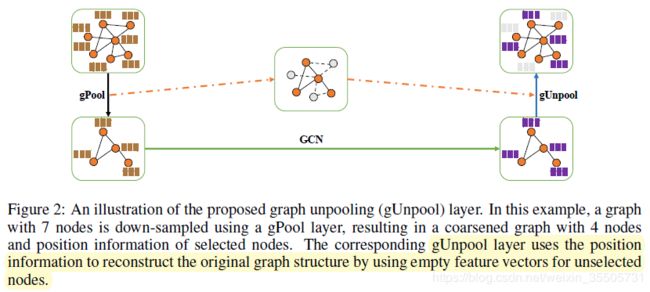
上图是gPooling池化过程。原文还有gUpooling,即上采样。在下采样的过程中,记录新图的顶点在原图的位置,在上采样时将根据这个位置信息将小图的顶点“还原”到大图上,见下图。
6 Self-Attention Graph Pooling
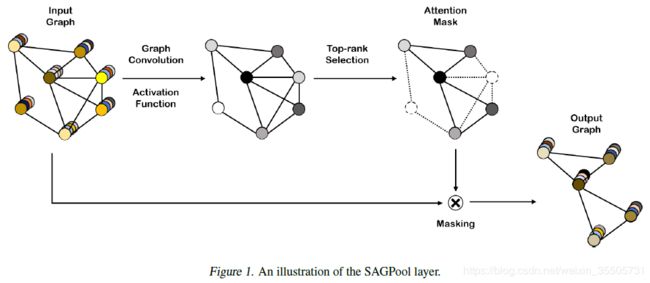
[Lee J, 2019, 6] 提出了一种自注意力池化方法SAGPool。
- 利用卷积生成自注意力,参数 T h e t a att Theta_{\text{att}} Thetaatt可学习: Z = σ ( D ~ − 1 2 A ~ D ~ − 1 2 X Θ att ) ∈ R N × 1 Z = \sigma \left( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} X \Theta_{\text{att}} \right) \quad \in \reals^{N \times 1} Z=σ(D~−21A~D~−21XΘatt)∈RN×1;
- 根据超参池化率 k ∈ ( 0 , 1 ] k\in (0,1] k∈(0,1],截取前 ⌈ k N ⌉ \lceil kN \rceil ⌈kN⌉,得到保留的索引idx和自注意力掩码 Z mask Z_{\text{mask}} Zmask: idx = top-rank ( Z , ⌈ k N ⌉ ) , Z mask = Z idx \text{idx} = \text{top-rank}(Z,\lceil kN \rceil), \quad Z_{\text{mask}} = Z_{\text{idx}} idx=top-rank(Z,⌈kN⌉),Zmask=Zidx;
- 根据索引idx和掩码 Z mask Z_{\text{mask}} Zmask获得新的特征和邻接矩阵: X out = X idx , : ⊙ Z mask , A out = A idx , idx X_{\text{out}} = X_{\text{idx},:} \odot Z_{\text{mask}}, \quad A_{\text{out}}= A_{\text{idx},\text{idx}} Xout=Xidx,:⊙Zmask,Aout=Aidx,idx。
原文对自注意力 Z Z Z的获得给出了多种变体:
Z = σ ( GNN ( X , A ) ) , Z = σ ( GNN ( X , A + A 2 ) ) , Z = σ ( GNN 2 ( σ ( GNN 1 ( X , A ) ) , A ) ) , Z = 1 M ∑ m σ ( GNN m ( X , A ) ) . \begin{aligned} Z &= \sigma \left( \text{GNN}(X,A)\right), \\ Z &= \sigma \left( \text{GNN}(X,A+A^2)\right), \\ Z &= \sigma \left( \text{GNN}_2 \left( \sigma \left( \text{GNN}_1(X,A)\right) ,A \right) \right), \\ Z &= \frac{1}{M} \sum_m \sigma \left( \text{GNN}_m(X,A)\right). \\ \end{aligned} ZZZZ=σ(GNN(X,A)),=σ(GNN(X,A+A2)),=σ(GNN2(σ(GNN1(X,A)),A)),=M1m∑σ(GNNm(X,A)).
参考文献
-
1 Henaff M, Bruna J, Lecun Y, et al. Deep Convolutional Networks on Graph-Structured Data.[J]. arXiv: Learning, 2015.
-
2 Defferrard M, Bresson X, Vandergheynst P, et al. Convolutional neural networks on graphs with fast localized spectral filtering[C]. neural information processing systems, 2016: 3844-3852.
-
3 Zhang M, Cui Z, Neumann M, et al. An End-to-End Deep Learning Architecture for Graph Classification[C]. national conference on artificial intelligence, 2018: 4438-4445.
-
4 Ying R, You J, Morris C, et al. Hierarchical Graph Representation Learning with Differentiable Pooling[J]. arXiv: Learning, 2018.
-
5 Gao H, Ji S. Graph U-Nets[C]. international conference on machine learning, 2019: 2083-2092.
-
6 Lee J, Lee I, Kang J, et al. Self-Attention Graph Pooling[C]. international conference on machine learning, 2019: 3734-3743.
-
7 Shervashidze N, Schweitzer P, Van Leeuwen E J, et al. Weisfeiler-Lehman Graph Kernels[J]. Journal of Machine Learning Research, 2011: 2539-2561.