SpringCloud--09服务链路追踪Sleuth
1.为什么需要Spring Cloud Sleuth
一个微服务系统往往有多个服务单元,由于服务单元数量众多,业务的复杂性较高,如果出现了错误和异常,很难去定位,所以在分布式架构中必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的。
常见的链路追踪组建有Google的Dapper,Twitter的Zipkin,以及阿里的鹰眼。
本博客主要讲述在Spring Cloud Sleuth如何集成Zipkin。
本文的案例主要有四个工程组成:
eureka-server,作为注册中心,
zipkin-server,它的主要作用使用ZipkinServer 的功能,收集调用数据,并展示,在spring Cloud更加高版本的时候,已经不需要自己构建Zipkin Server了,只需要下载jar即可,下载地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
user-service:一个服务提供者,同时作为链路追踪的客户端负责生产数据。
gateway-service:网关服务,负责请求的转发,同时作为服务链路追踪的客户端,负责生产数据。
zipkin-server工程,下载jar包下来启动,访问:http://localhost:9411/zipkin/
user-service工程,pom文件:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
com.wx
user-service
0.0.1-SNAPSHOT
user-service
Demo project for Spring Boot
UTF-8
UTF-8
1.8
Finchley.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.cloud
spring-cloud-starter-eureka
1.4.4.RELEASE
org.springframework.cloud
spring-cloud-starter-zipkin
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-surefire-plugin
true
yml文件:
server:
port: 8774
spring:
application:
name: user-service
sleuth:
sampler:
probability: 1.0
zipkin:
base-url: http://localhost:9411
eureka:
client:
serviceUrl:
defaultZone: http://peer1:8761/eureka/sleuth:sampler:probability: 1.0 表示以百分之百的概率将链路数据上传给zipkin-server,默认情况下,该值为0.1。
在测试的过程中我们会发现,有时候,程序刚刚启动后,刷新几次,并不能看到任何数据,原因就是我们的spring-cloud-sleuth收集信息是有一定的比率的,默认的采样率是0.1,配置此值的方式在配置文件中增加spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。但是当这样调整后,我们会发现我们的rest接口调用速度比0.1的情况下慢了很多,即使在0.1的采样率下,我们多次刷新consumer的接口,会发现对同一个请求两次耗时信息相差非常大,如果取消spring-cloud-sleuth后我们再测试,会发现并没有这种情况,可以看到这种方式追踪服务调用链路会给我们业务程序性能带来一定的影响。sleuth采样率,默认为0.1,值越大收集越及时,但性能影响也越大
启动类上加注解开启eureka-client的功能.
编写测试类:
@RestController
@RequestMapping("/user")
public class TestController {
@GetMapping("/hi")
public String hi(){
return "I am iron man";
}
}新建gateway-server model
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
com.wx
gateway-service
0.0.1-SNAPSHOT
gateway-service
Demo project for Spring Boot
UTF-8
UTF-8
1.8
Finchley.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.cloud
spring-cloud-starter-eureka
1.4.4.RELEASE
org.springframework.cloud
spring-cloud-starter-netflix-zuul
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-starter-zipkin
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-surefire-plugin
true
yml文件:
eureka:
client:
serviceUrl:
defaultZone: http://peer1:8761/eureka/
server:
port: 8775
spring:
application:
name: gateway-service
sleuth:
sampler:
probability: 1.0
zipkin:
base-url: http://localhost:9411
zuul:
routes:
api-hi:
path: /user-api/**
serviceId: user-service加上注解开启eureka和网关的功能:
启动eureka-server,zipkin-server,user-service,geteway-service
访问:
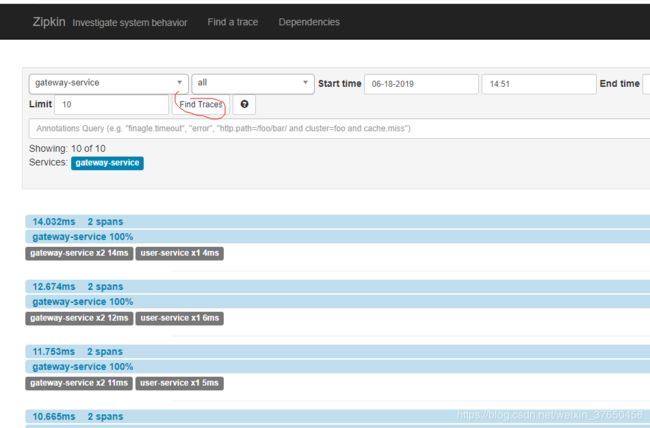
可以查看请求的调用情况。
可以查看依赖关系

2.使用RabbitMQ来传输链路数据
ziplin的客户端是通过http的上传给ziplin-server,每次发送的时候涉及到连接和发送过程,当我们的zipkin-server程序关闭或者重启过程中,因为客户端收集信息的发送采用http的方式会被丢失。所以需要采用socket或者其他效率更高的通信方式。客户端数据的发送尽量减少业务线程的时间消耗,采用异步等方式发送收集信息,客户端与zipkin-server之间增加缓存类的中间件,例如redis、MQ等,在zipkin-server程序挂掉或重启过程中,客户端依旧可以正常的发送自己收集的信息。相信采用以上三种方式会很大的提高我们的效率和可靠性。其实spring-cloud已经为我们提供采用MQ或redis等其他的采用socket方式通信,利用消息中间件或数据库缓存的实现方式。
首先zipkin-server是已经下载的jar包无法改造,所以只需要改造zipkin-client即可,在 POM 依赖里引入 spring-cloud-stream-binder-rabbit 即可,别的不用改。然后启动zipkin-server,serv的版本需要高一点的才能和rabbit连上。
这里的rabbit版本是3.7.8,zipkin-server的版本的是2.2.0
首先启动eureka-server,然后启动rabbit服务,访问http://localhost:15672/#/
zipkin-server,启动的命令是:
java -jar zipkin-server-2.2.0-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672 --zipkin.collector.rabbitmq.username=guest --zipkin.collector.rabbitmq.password=guest正常的话消息队列里面已经有这个服务名字了,
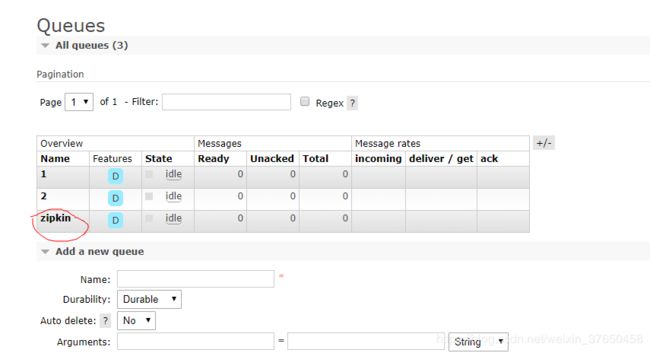
之前就是因为zipkin-serverde 版本太低导致与rabbit美连接上。
然后就是改造两个zipkin-client工程,一个服务提供者,一个路由网关。
user-service的pom文件:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
com.wx
user-service
0.0.1-SNAPSHOT
user-service
Demo project for Spring Boot
UTF-8
UTF-8
1.8
Finchley.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.cloud
spring-cloud-starter-eureka
1.4.4.RELEASE
org.springframework.cloud
spring-cloud-starter-zipkin
2.0.3.RELEASE
org.springframework.amqp
spring-rabbit
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-surefire-plugin
true
yml文件:
server:
port: 8774
spring:
application:
name: user-service
sleuth:
sampler:
probability: 1.0
zipkin:
sender:
type: rabbit
enabled: true
rabbitmq:
host: localhost
port: 5672
password: guest
username: guest
listener:
direct:
retry:
enabled: true
simple:
retry:
enabled: true
eureka:
client:
serviceUrl:
defaultZone: http://peer1:8761/eureka/
需要配置消息的发送方式是使用rabbit,
gateway-service的pom文件;
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
com.wx
gateway-service
0.0.1-SNAPSHOT
gateway-service
Demo project for Spring Boot
UTF-8
UTF-8
1.8
Finchley.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.cloud
spring-cloud-starter-eureka
1.4.4.RELEASE
org.springframework.cloud
spring-cloud-starter-netflix-zuul
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-starter-zipkin
2.0.3.RELEASE
org.springframework.amqp
spring-rabbit
2.0.3.RELEASE
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-surefire-plugin
true
yml文件:
eureka:
client:
serviceUrl:
defaultZone: http://peer1:8761/eureka/
server:
port: 8775
spring:
application:
name: gateway-service
sleuth:
sampler:
probability: 1.0
zipkin:
sender:
type: rabbit
rabbitmq:
host: localhost
port: 5672
password: guest
username: guest
listener:
direct:
retry:
enabled: true
simple:
retry:
enabled: true
zuul:
routes:
api-hi:
path: /user-api/**
serviceId: user-service启动这两个服务:

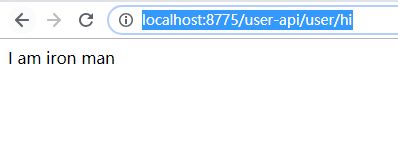
访问:http://localhost:8775/user-api/user/hi
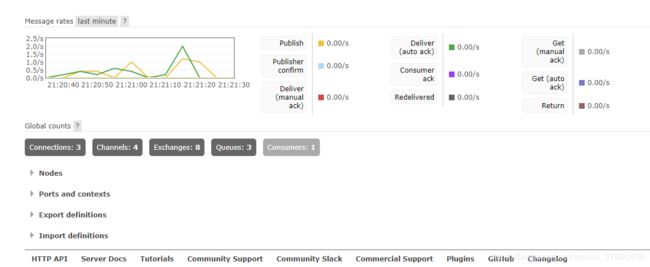
查看消息队列:
然后擦好看zipkin-server

依赖关系:
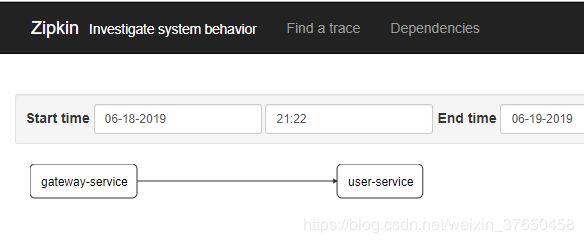
数据从zipkin-clinet产生,然后发送到了rabbitMQ,然后由rabbitMQ,发送到zipkin-server显示,使用的是socket协议,比之前的http协议更好,因为当zipkin-server重启的时候数据丢失的可能性很小。
此时zipkin的状态如下:

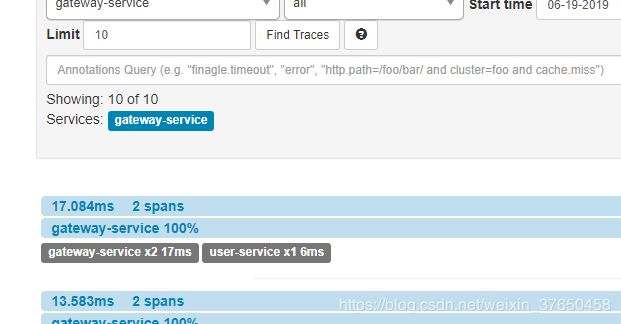
现在我关闭zipkin-server,然后调用http://localhost:8775/user-api/user/hi
可以看到消息走的是rabbit
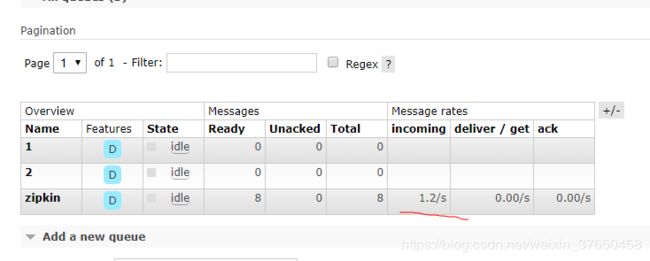
现在打开zipkin-server:可以发现他重启后是可以消费之前堆积的消息的。
3.通过MySql来持久化链路数据
因为这些链路的数据都是存在zipkin-server的内存中的,内存的内存又小又不安全,所以需要将数据持久化存储
但是数据的传输协议有两种,可以通过Http的方式或者Rabbit,
这里就讲使用Rabbit的方式来将zipkin-server收集的链路数据放到Mysql中。
首先数据的脚本:
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp():epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration():micros used for minDuration and maxDuration query'
)ENGINE=INNODB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'forjoining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'forgetTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering andrange';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincideswith zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincideswith zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used toimplement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null whenBinary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null whenBinary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null whenBinary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT'Null when Binary/Annotation.endpoint is null'
)ENGINE=INNODB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`,`a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`)COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'forgetTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'forgetTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'fordependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT
)ENGINE=INNODB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
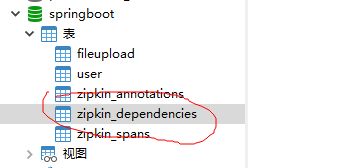
执行的结果就是下面三个表
zipkin-server的启动命令就需要加上mysql的参数了:
java -jar zipkin-server-2.2.0-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672 --zipkin.collector.rabbitmq.password=guest --zipkin.collector.rabbitmq.username=guest --STORAGE_TYPE=mysql --MYSQL_DB=springboot --MYSQL_USER=root --MYSQL_PASS=****** --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306请求几次服务查看数据库:

数据到了数据库了。
4.使用ElasticSearch来存储链路数据
在高并发的情况下显然使用ElasticSearch来储存数据是不合理的,所以使用ES来储存,使用Kibana来显示数据。
参考博客:https://blog.csdn.net/qq_27828675/article/details/83543048
https://blog.csdn.net/qq_27828675/article/details/83543048