Python进阶(八):in的详解
“in”的存在使得python在操作可迭代对象时简单得多,这便是“in”存在的一个最大的好处
1.用于判断(查找)元素是否在可迭代对象中(不包括生成器;但包括set集合,set不能迭代,但是也能用“in”来查找元素):
xxx in XXX :判断xxx是否在XXX中, 如果在,返回真,不在,返回假。
xxx not in XXX :判断xxx是否不在XXX中, 如果不在,返回真,在,返回假。
可配合“if”和“while”使用:
if x in X
if x not in X
while x in X
while x not in X2.用于逐个取可迭代对象的元素, 一般要配合for使用:
我们可能常用到的可迭代的对象包括:string, list, dict, tuple, generator, range函数
例子:
list_1 = [n for n in range(10)]
for i in list:
print(i)3.在前面1的条件下,“in”的效率在不同的对象中查找元素效率是很不一样的。
tuple, list, dict, set用“in”来查找元素时效率是相差很大的。
主要是因为dict, set背后原理是一个散列表。而tuple, list只是一个单纯类似与数组的结构
那什么是散列表?
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
关于散列表的原理我就不在这里细讲,总之就是一种算法来使表中的每个元素附上一个键(key),然后查找元素只要匹配这个键来就可以了。速度上会快很多。如果有兴趣可以点这篇链接了解:哈希表(散列表)原理详解
下面我举个例子感受下:
import time
import random
LEN = 10 ** 7
# 生成各不相同的10^7个元素
in_set = {random.random()
for i in range(LEN)}
while len(in_set) < LEN:
in_set.add(random.random())
# 转换为list,tuple,dict
in_list = list(in_set)
in_tuple = list(in_set)
in_dict = {key: 0 for key in in_set}
#随机选择其中500个用于查找
needles = [in_list[random.randint(0, LEN)]
for _ in range(500)]
def test(target):
t1 = time.time()
global needles
found = 0
for n in needles:
if n in target:
found +=1
t2 = time.time()
print(found)
return t2 - t1
t1 = test(in_set)
t2 = test(in_list)
t3 = test(in_tuple)
t4 = test(in_dict)
print(t1, t2, t3, t4)结果:set:0.0009999275207519531, list:451.28881216049194,tuple:464.02254033088684, dict:0.0010001659393310547
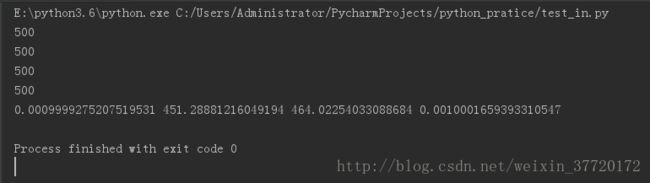
dict,set比tuple, list快了不止一点。所以说在数据量比较大的且需要查找元素的时候请使用dict, set,这样带来的速度提升不是一点点那么简单了
谢谢阅读,如果可以请关注小弟的公众号:
