模型训练与测试 -----BN层()
Feature normalization Feature scaliing
首先是为什么要归一化或者标准化,从下面可以看出来如果我们的输入的样本或者特征值,他们之间的差异比较大,那么其实我们的梯度下降图是畸形的。比如下面因为x1比x2小太多,所以梯度没有x2 那么浮夸。但是如果他们是一样的话,那么他们就有右边这样的东西了。所以为了好的梯度下降,我们需要针对不同的参数用不同的learning rate。这一个是已经有实现的就是我们自适应优化器的出现,但是其实优化器对他们的影响还是有限的,但是如果我们在处理前,将图变成右边那样呢?那是不是其实我们就可以更好的做梯度下降了,所以到这里我们可以看到了BN层或者归一化的作用力。

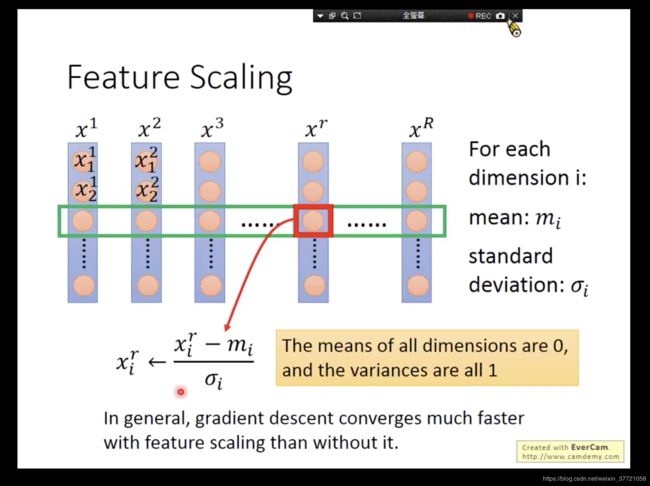
其他原因呢?
之所以就会研究BN层是因为,我在用pytorch写模型的时候,会发现pytorch给了两个东西一个叫做model.train()
一个叫做model.eval().这两者的区别在于如果你要训练模型那么你要用第一句,如果你是测试模型那么你要用第二句。而两者的区别在于他们对BN层和dropout层的处理是不一样的。所以我们发现训练和测试的过程,我们看待BN层也是不一样的。也因为好奇,所以我们去深入看看BN层在训练的过程的作用。要不也不会叫做batchnormalization了,因为和batch有关啊
图中 的几个点:
第一个是因为模型在训练所以每次的output的数值都是有变化的, 而BN层的办法就是让他们归一化。减少对下一层的影响。
第二个就是internal covariate shift的想象在于,前面的变化会导致后面的变化,有时候变化不统一出现的结果。大家都动结果容易坏掉。

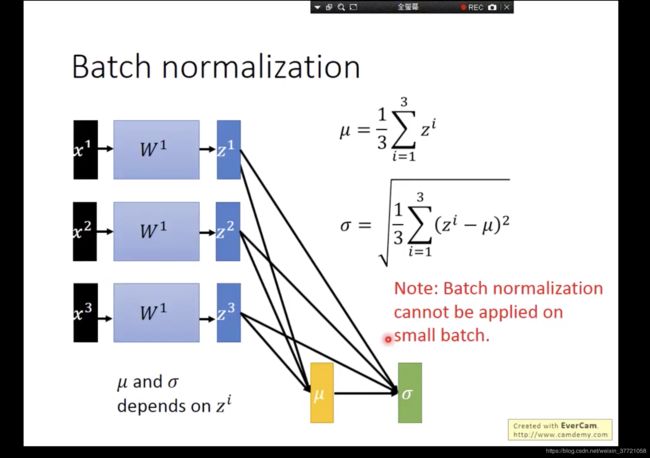
左下面是GPU实际上的batch操作。

下面是BN层的计算:
- 关于均值和方差我们是对每个训练的batch来求的,这里意味着如果我们训练的过程中batch太小?你算毛方差和均值,所以batch不能太小。所以我们测试的时候,我们一般都是单张图的话,我们的BN层需要固定住,这也是为什么有了上面两种模式了。但是如果你是多张同时的话估计没啥问题。
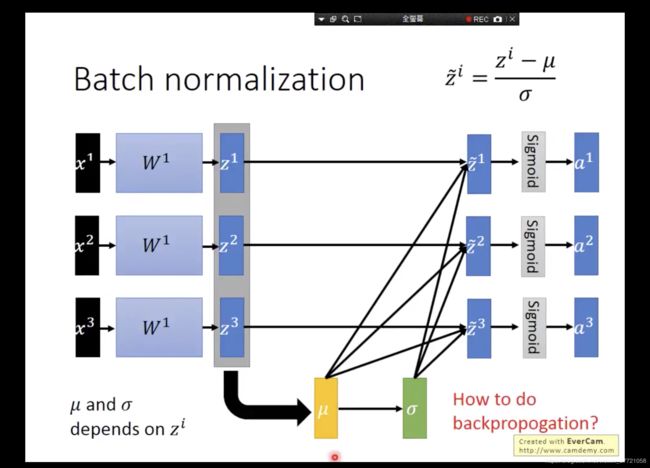
接下来呢?有了方差和均值,肯定要归一化啦。下面就是进行归一化了,这样一看感觉BN层好像不需要进行训练吧?不过就是一个归一化的操作?但实际上BN层也是有参数需要训练的。而实际上还有另外两个是用来训练的参数,这个参数可以让我们的BN层不局限于当前的batch也会和之前的有些关系。
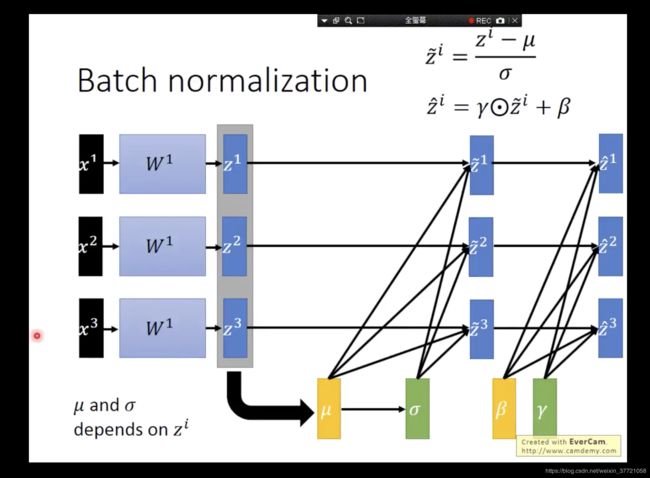
上面的后面两个就是我们训练的参数,其实这两个有时候会让BN层失效,但是这就符合我们模型本身,让自由度更加高。但是如何做反向传播呢?下面是公式的推导:
https://zhuanlan.zhihu.com/p/26138673
https://blog.csdn.net/kevin_hee/article/details/80783698
通过上面就可以知道推导的过程。知道BN层的反向传播,其实也是更加有利于我们知道深度学习反向传播的本质,就是不断的求梯度往下走。然后到达一个终点的路有很多,那么我们也要注意路上的反向传播。这里说下大疆的笔试题目,有涉及到这一部分,很多面试题目都有要求BN层的反向传播,所以建议非常熟悉这一部分的推导
然后就是测试的时候,如何算均值和方差呢?因为我们大部分测试的时候都是一张图的,这也是我们pytorch为什么在测试和训练会给出两个不同的模式,因为我们的BN层的处理是不一样的,训练的时候我们用batch的均值和方差。但是测试的时候呢,我们做下面说的操作。

BN层的好处:
第1个可以用大的learning rate,因为我们BN了啦,所以大家的梯度都很漂亮呀
第2个是减少covariate shift,
第3个是可以减少梯度消失的问题,特别是用了sigmoid这样的函数在womendemoxing
第4个减少因为初始化模型参数带来的影响。参数的变化,那么输出也发生变化,那么归一化呢?一起大一起小,什么事情都没发生。
第5个可以减少噪声带来的影响呀,据说可以避免overfitting

云从笔试题有问到:BN层与EWA的关系

pytorch中的BN层:看到了EWA了,个人理解之所以用Momentum是在测试时候需要用到均值和方差,这时候通过EWA可以记录过去最好的,这时候就可以用上了,这也就是云从科技的笔试题问到了BN层在训练和测试的时候会做什么,分别是计算当前的,和累加出最好的,前者就是统计计算,后者就是EWA也就是滑动平均 ,model.eval() 和model.train() 在预训练中是非常重要的。
The running mean and variances are computed using an exponential moving average with smoothing factor 0.1. i.e running_mean[t] = running_mean[t-1]*0.9 + batch_mean[t]*0.1
track_running_stats – a boolean value that when set to True, this module tracks the running mean and variance, and when set to False, this module does not track such statistics and always uses batch statistics in both training and eval modes. Default: True
————————————————
trainning=True, track_running_stats=True。这个是期望中的训练阶段的设置,此时BN将会跟踪整个训练过程中batch的统计特性。
trainning=True, track_running_stats=False。此时BN只会计算当前输入的训练batch的统计特性,可能没法很好地描述全局的数据统计特性。
trainning=False, track_running_stats=True。这个是期望中的测试阶段的设置,此时BN会用之前训练好的模型中的(假设已经保存下了)running_mean和running_var并且不会对其进行更新。一般来说,只需要设置model.eval()其中model中含有BN层,即可实现这个功能。[6,8]

BN层的作用
1.防止过拟合,可以用来替代drop out层
2.可以防止梯度弥散
3.其能够让优化空间(optimization landscape)变的平滑
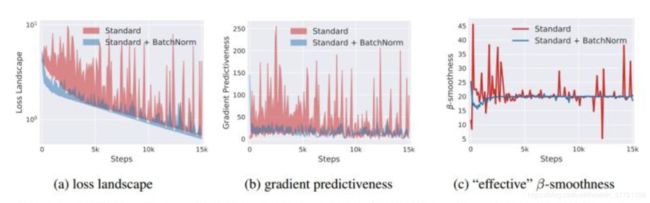
N可以提高训练时模型对于不同超参(学习率、初始化)的鲁棒性从而避免了过拟合、可以让大部分的激活函数能够远离其饱和区域防止梯度爆炸或弥散
对于没有BN的神经网络,其loss函数是不仅非凸,并且还有很多flat regions、sharp minimal。这就使得那些基于梯度的优化方法变得不稳定,因为很容易出现过大或者过小的梯度值。观察上图,可以发现,在使用了BN后,loss的变化变得更加稳定,不会出现过大的跳动;同样,梯度也变得更加平滑。
参考原文链接:
https://blog.csdn.net/LoseInVain/article/details/86476010
https://blog.csdn.net/xiaojiajia007/article/details/90115174
https://zhuanlan.zhihu.com/p/68863894
https://zhuanlan.zhihu.com/p/33173246